



前言在无人机自主导航领域,如何让飞行器在复杂环境中仅凭机载传感与计算实现安全、高效的避障与路径规划,始终是极具挑战性的课题。传统方案往往依赖繁琐的轨迹生成与跟踪层级,或因传感器特性局限难以精准捕捉细小障碍物,而融合3D激光雷达与强化学习的端到端导航技术,正为这一难题提供突破性思路。本文所提出的方法,创新性地将高分辨率激光雷达的点云数据转化为任务适配的轻量化感知表示,既保留了对狭窄空域和纤细障碍物的精细感知能力,又通过强化学习直接映射至低延迟的底层控制指令,让无人机仿佛 “飞” 在点云之上 —— 无需复杂的中间处理模块,便能在50Hz的控制频率下,凭借对已知与未知区域的动态感知,在室内电线、室外树林等复杂场景中实现平滑避障与安全穿越。这种技术融合不仅突破了传统导航框架在速度与精度上的瓶颈,更为无人机在真实世界杂乱环境中的自主飞行开辟了全新路径。

论文题目:Flying on Point Clouds with Reinforcement Learning
论文作者:Guangtong Xu, Tianyue Wu, Zihan Wang, Qianhao Wang, Fei Gao
论文地址:[2503.00496] Flying on Point Clouds with Reinforcement Learning

该研究的核心在于构建一个从仿真到现实的强化学习框架,其能够将机载3D激光雷达的原始感知数据直接、端到端地映射为无人机的底层控制指令。整个技术框架可概括为 “感知表示设计-强化学习策略构建-仿真与实机部署” 三部分。
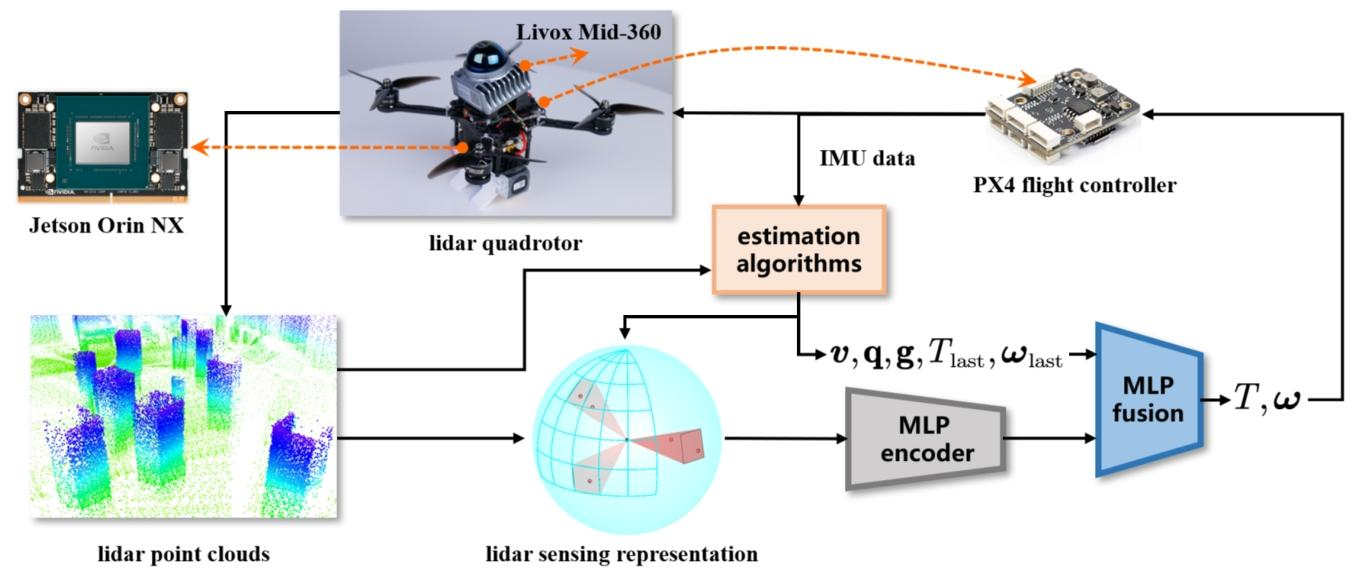
图1|融合3D激光雷达与强化学习的端到端导航框架。
感知表示设计
为了在不牺牲感知精度的前提下,解决原始点云数据维度过高、难以直接用于强化学习训练的难题,研究团队设计了一种任务相关的轻量化感知表征方法。该方法巧妙地将环境的几何信息与传感器的观测边界信息编码为一个固定维度的一维向量,具体构建过程如下:
空间分区:以无人机自身为中心,将其周围空间在机体坐标系下划分为3200个等角度的锥形分区。
信息编码:对每个锥形分区,根据其内部是否存在历史点云数据,赋予不同的值。若分区内有障碍点,则该分区的值被设为无人机中心到该分区内最近点云的距离。这保留了对近处障碍物的精细感知。若分区内无障碍点,则该区域被视为已知自由空间。为了让策略网络感知到观测范围的边界,该分区的值被设为一个与未知区域边界距离相关的函数,具体为
。这种设计让智能体能够明确区分已探明的安全区和未探索的未知区,从而做出更安全的决策。
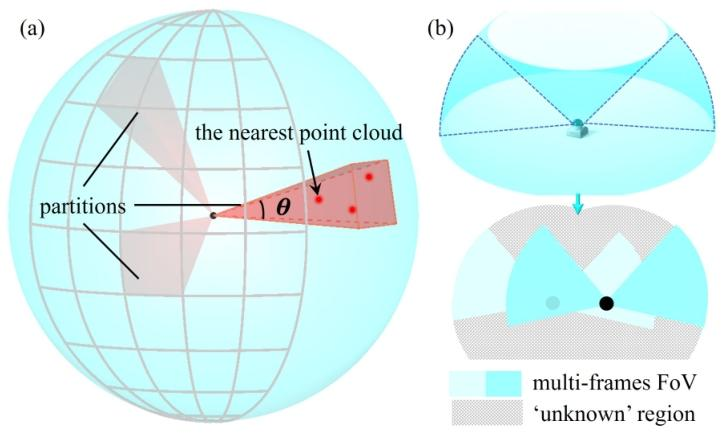
图2|激光雷达点云感知表示示意图。
通过这种方式,高维、无序的点云被转化为一个结构化的、信息密度高的3200维向量,既能有效检测细小障碍物,又为策略网络提供了关于环境可观测性的关键先验知识。
强化学习策略构建
该框架采用端到端的学习范式,策略网络直接输出无人机在50Hz频率下执行的底层控制指令:总推力和机体角速度。
网络结构:策略网络由一个多层感知机(MLP)编码器和一个MLP融合模块构成。前者负责处理前述的3200维激光雷达感知表征,将其压缩为低维特征;后者则融合该特征、无人机自身位姿以及目标点方向等信息,最终输出四维的动作指令。
奖励函数: 为了引导智能体学习到安全、平稳且高效的飞行策略, 研究团队设计了一个综合性的奖励函数。该函数由多个子项加权构成, 鼓励期望行为并惩罚危险行为,具体为:
其中, 鼓励无人机向目标点移动,
惩罚过大的总推力, 鼓励无人机以更节能、更平稳的方式飞行,
惩罚剧烈的机体角速度变化, 确保飞行姿态的平顺和稳定,
确保无人机的飞行速度不超过一个预设的安全上限,
鼓励无人机在设定的目标高度附近飞行,防止飞得过高或过低,
基于与障碍物的距离提供一个连续的塑形奖励, 引导无人机主动远离障碍物,
会在发生碰撞时给予一个巨大的惩罚值,
鼓励无人机的机头方向与其飞行速度方向对齐。
仿真与实机部署
为了确保在仿真环境中训练出的策略能够成功部署到物理世界的无人机上,研究团队采用了两项关键的技术:
动力学域随机化:在训练过程中,对无人机的动力学模型参数(如推力、角速度响应和空气阻力系数)引入大幅度的随机扰动。这使得训练出的策略对现实世界中未建模的空气动力学效应和执行器噪声具有更强的鲁棒性。
高保真度激光雷达仿真:研究团队没有使用理想化的射线投射来模拟激光雷达,而是通过拟合真实激光雷达传感器(Livox Mid-360)在现实中采集数据的时空扫描模式,构建了一个轻量级且高保真度的传感器模拟器。这极大地减小了仿真与现实世界在感知数据上的差异,是实现成功迁移的关键。

为了全面验证其提出的端到端导航框架的有效性和优越性,研究团队进行了一系列严谨的仿真和真实世界实验。实验结果有力地证明了该方法在感知精度、飞行效率和真实环境鲁棒性方面的突破。
为验证所设计的激光雷达点云感知表示的必要性和优越性,研究团队在包含大量细小障碍物(如电线)的仿真环境中,分别采用 3D CNN、2D CNN 处理占用图,与基于本文表示的 MLP 网络在相同训练条件下对比累积奖励的演化过程。
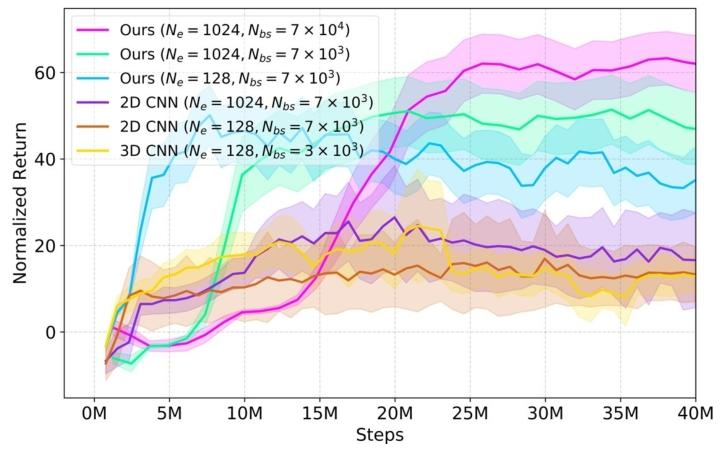
图3|本文提出的点云感知表示方法昱占用图方法在训练过程中的累积奖励的演化过程
结果显示,本文设计的点云感知表示(3200 维分区特征)支持更大批次(7×10⁴),训练效率显著提升,累积奖励快速增长并稳定在更高水平。这证明了该表示在保留细粒度感知的同时,能实现轻量级 RL 训练,为后续性能奠定基础。
在三种随机障碍物场景中(场景I:100个半径0.5-0.7m障碍物;场景II:130个同尺寸障碍物;场景III:90个半径0.5-1.2m障碍物),将本文的端到端导航与Fast-Planner、EGO-Planner、EGO-Planner v2对比不同速度约束下的成功率。
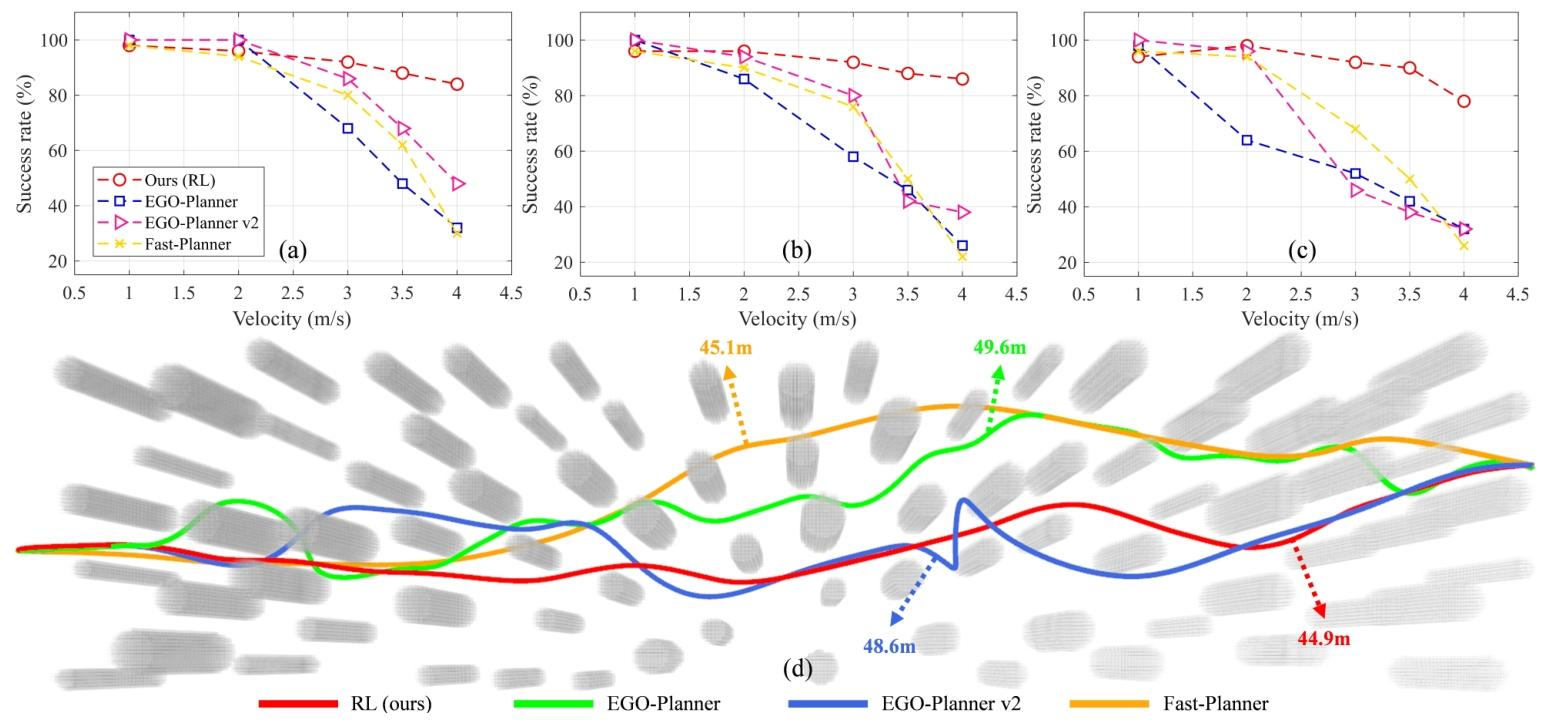
图4|不同最大速度约束下与现有系统的基准测试结果。图(a)-(c)分别展示了在场景 I、II 和 III 中的成功率对比结果。图(d)表示在速度约束为 3.0 m/s的场景 III 中,各对比方法的成功轨迹示例,并提供了相应的飞行距离
对比结果表明,在所有不同的场景中,本文的端到端导航方法均取得了最高的成功率和最快的平均速度。尤其是在场景III下,其成功率远超其他方法。此外,轨迹对比图显示,传统规划方法由于其分层特性,在面对密集障碍物时生成的轨迹往往过于保守和曲折;而本文的端到端导航方法则能生成更直接、更流畅的高速飞行轨迹。
为展示本文的端到端导航方法从仿真到现实的迁移能力,证明该方法在不经任何微调的情况下,能够直接部署于物理无人机并在真实、复杂的环境中鲁棒运行,研究团队设计了含10mm直径电线(视觉传感器易漏检)和箱体的室内场景,测试无人机对细障碍物的避障能力。

图5|室内飞行结果。(a)室内场景I。(b)室内场景II。无人机能够安全穿越杂乱环境。箭头表示飞行方向。(c)和(d)为无人机躲避电线的瞬间快照
结果显示,无人机能通过激光雷达提前感知电线,执行向上规避的平滑机动,以高达 2.5 m/s 的速度自主飞行。这直接证明了 3D 激光雷达在检测细小障碍物上的优势,以及强化学习策略将感知转化为实时控制的有效性。

该研究提出了一种创新的端到端强化学习导航框架,旨在解决无人机在未知、杂乱环境中的高速安全飞行难题。其核心突破在于设计了一种新颖的任务相关激光雷达感知表征方法,该方法能将高维点云高效编码为结构化输入,并巧妙地区分了障碍物、已知的安全区域与未探索的未知空间,从而为决策提供了更丰富的信息。通过结合高保真度的仿真环境与动力学随机化技术,该框架在仿真中训练出的策略无需任何真实世界微调,即可直接部署于物理无人机,为无人机自主飞行提供了高效且鲁棒的解决方案。

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









