



导读
让机器人“盲盒抓取”一个没见过的物体有多难?单视角观测、不完整点云、背景杂乱……这些现实因素常常让机器人“抓瞎”。但这篇论文换了个思路:别教机器人从零学抓取,不如让它“找相似的”。来自某研究团队的这项新方法完全跳脱传统深度学习框架,改为通过“相似性匹配”解决未知物体抓取问题。具体做法是:先用视觉特征去数据库里找相似模型,再用这些“相似物”的抓取经验规划动作,最后做一点本地优化来精调效果。不仅如此,作者还开发了一个新型点云描述符(C-FPFH),再加上大语言模型辅助、包围盒判断和平面配准等操作,在单视角条件下也能稳定识别和抓取。实验显示,这种“类比式抓取”策略在复杂环境下表现相当强悍,抓啥都不怕!
论文出处:IEEE Transactions on Robotics 2025
论文标题:A Multi-Level Similarity Approach for Single-View Object Grasping:Matching, Planning, and Fine-Tuning
论文作者: Hao Chen, Takuya Kiyokawa, Zhengtao Hu, Weiwei Wan, and Kensuke Harada

无论是工业机器人还是服务型机器人,都必须应对种类繁多、形状各异、摆放方式多样的物体。在传统的机器人系统中,通常需要预先了解每个物体的详细属性,然后为每种任务手动设计对应的操作动作。随着物体类型的增加,这种方式不仅劳动密集、难以扩展,而且对于从未见过的新物体仍然无能为力。因此,开发一种能够无需先验知识、也能稳定操作各种新物体的高灵巧性机器人系统,成为了亟待解决的难题。
过去十年,视觉技术与深度学习的快速发展,推动了大量面向未知物体抓取的研究成果。例如,已有方法利用深度图像、RGB-D图像或点云数据训练神经网络,以检测和评估未见物体的抓取动作。这类方法虽然取得了一定成果,但仍存在如下局限:如只能执行固定方向的抓取(如自上而下),或过于依赖高精度的视觉特征。
为了提升通用抓取系统的泛化能力,近期研究引入了场景级表示和大规模数据集,试图提供更丰富的训练样本。然而这些方法普遍面临高昂的训练代价,并对感知噪声与环境变化敏感。基于此,作者认为是时候跳出传统学习框架,另辟蹊径,提出一种基于**相似性匹配(similarity matching)**的新范式。
一项近期研究首次引入了“语义+几何”的打分机制,从相似的已知物体中迁移抓取知识来辅助未知物体抓取。但该方法需要多视角观测,且在目标物种类复杂时表现不稳定,根本原因在于语义与几何相似度的权重难以平衡。
本文在此基础上做出了重要拓展:将相似性匹配拓展到单视角条件下,并构建了一个更高效、结构更清晰的匹配框架。该框架从语义、几何、尺度三个层面独立评估物体相似性,避免了单一复合评分方式引发的冲突。特别地,作者提出了一种新型点云几何描述子 —— C-FPFH(Clustered Fast Point Feature Histogram),这是首个可用于不完全点云与完整模型之间相似度评估的描述符,表现出优异的抗遮挡能力。
此外,作者还结合了一系列增强模块,包括:
● 借助大语言模型提升语义判断能力;
● 提出半定向包围盒(semi-oriented bounding box)来辅助抓取姿态初估;
● 基于平面检测进行点云配准,从而提升在单视角观测条件下的匹配精度。
为了保证最终抓取的稳定性,作者还在模仿抓取的基础上引入了两阶段的微调机制,通过局部接触点的细粒度特征进一步优化抓取动作。
实验方面,作者使用一个不足100个物体模型的小型数据库,在丰富的新颖物体抓取任务上(包括独立物体和杂乱场景)进行评估,显著优于当前主流方法,在准确率、效率与泛化能力上均取得突破。图1展示了一个抓取牙刷的过程:系统识别出与其外形相似的螺丝刀模型,并借助已有抓取策略生成模仿抓取动作,最终执行并完成任务。
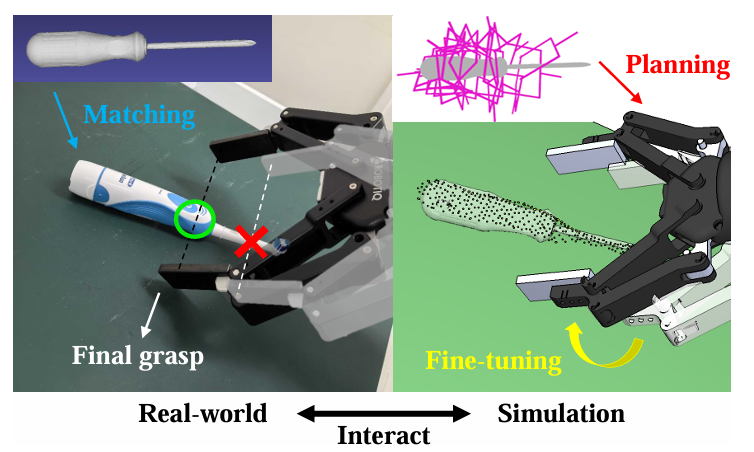
图1|这是一个使用本文三步法抓取未知物体的示例。首先,在真实环境中获取目标物体的视觉特征,并与数据库中的已知模型进行相似性匹配;接着,在仿真环境中基于匹配结果进行抓取规划与微调;最后,将优化后的抓取动作执行于真实世界,完成操作任务

整体流程概览
小编先来带大家看看整体方法的框架,系统的核心理念是:从单视角图像中提取目标特征,在已知物体数据库中找“长得像”的参考对象,再将已有抓取经验迁移给目标物体,这篇文章原文很长,小编在这里主要给大家总结归纳,挑重点介绍,要是感兴趣的读者可以继续读取原文查看细节部分。
整套流程如图2所示,可分为以下几个步骤:
1. 特征提取:用 RGBD 相机捕获目标图像,并通过分割模型获取其类别与 3D 点云;
2. 三层匹配:在数据库中进行语义(Semantic)、几何(Geometric)、尺寸(Dimensional)三层匹配:
● 语义匹配用 LLM(GPT-4o)辅助;
● 几何匹配引入了作者自研的 C-FPFH 描述子;
● 尺寸匹配则使用 SOBB 半定向包围盒评估;
3. 模型筛选:从多个维度得到的相似候选中进一步挑选,并通过点云配准确定最佳参考模型;
4. 模仿抓取:将数据库中该模型的预定义抓取动作映射到目标对象;
5. 两阶段微调:在仿真中精调抓取位置与中心,以提升稳定性
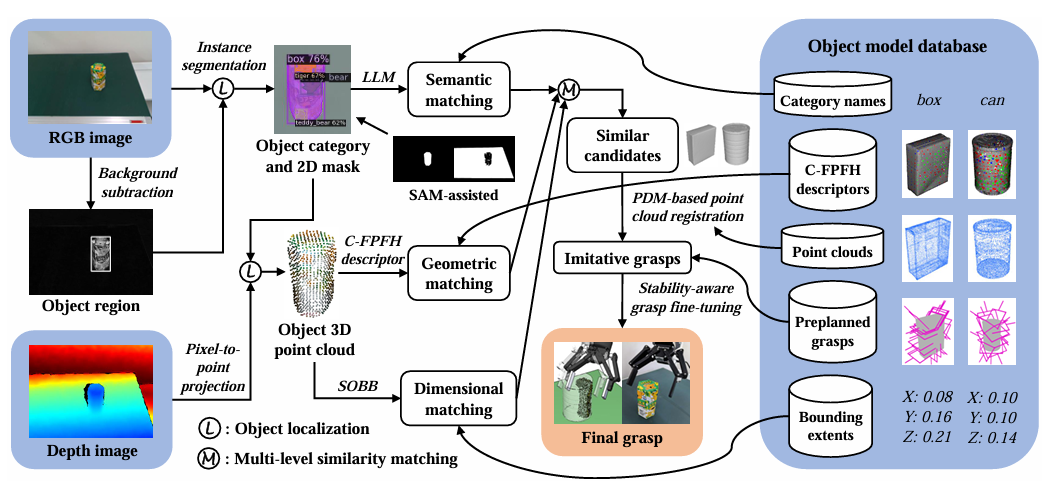
图2|方法的整体流程如图所示。系统的输入(蓝色框部分)包括一张单视角 RGBD 图像和一个已有的物体模型数据库,其中背景图像(不含目标物体)需提前拍摄获取。系统的输出(橙色框部分)则是一个经过优化的抓取动作,用于最终执行
目标物体识别与点云提取
这一部分保障了系统能从单帧图像中提取出相对可靠的点云和类别,为后续匹配奠定基础:
● 系统使用一台普通的 RGBD 相机安装在机械臂末端;
● 抓取前会先采集一张“纯背景图”用于背景减除;
● 对比差异图定位物体区域,借助预训练实例分割模型提取目标物体的类别与 2D 掩码;
● 对于未能正确识别类别的情况,系统会调用更强的 SAM 分割模型 提取轮廓,再基于深度图重建出物体的 3D 点云。
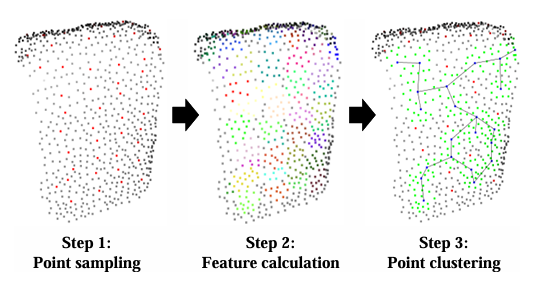
图3|C-FPFH点云产生的过程可视化
多层次相似性匹配
1. 三层视角下的匹配策略:
● 语义匹配:
○ 使用 GPT-4o,根据目标物体类别与数据库中已有类别之间的语义接近度判断(比传统 Word2Vec 更稳健);
○ 若目标类别缺失,则跳过该匹配层。
● 几何匹配:
○ 提出了新的几何描述子 C-FPFH(Clustered-FPFH),用于部分点云与完整模型之间的匹配;
○ 不再直接对比整云,而是先提取局部特征对(如点的主导法向分布),再通过“特征分布相似度 + 局部聚类结构”来判断相似度;
○ 提出了两个指标:
■ QS(Quantitative Similarity):评估特征对重合度;
■ DS(Distributional Similarity):评估主特征的空间分布相似性;
○ 并设定阈值(如 QS > 0.9 且 DS < 0.1)筛选最相似模型。
● 尺寸匹配:
○ 传统 AABB/OBB 包围盒对单视角点云并不准确;
○ 作者提出 SOBB(Semi-Oriented Bounding Box),通过提取桌面法向,固定一个轴的方向再评估其三维尺度,增强在遮挡场景下的稳健性;
○ 尺寸差异作为第三个指标 SS,若小于设定阈值也可纳入候选。
2. 多视角合成策略:
为避免单一匹配方式造成误判,作者提出如下优先级筛选原则:
● 同时满足三层匹配的模型优先;
● 若无,则退而求其次(任意两层匹配或一层匹配);
● 所有匹配失败时也保留最低优先级候选。
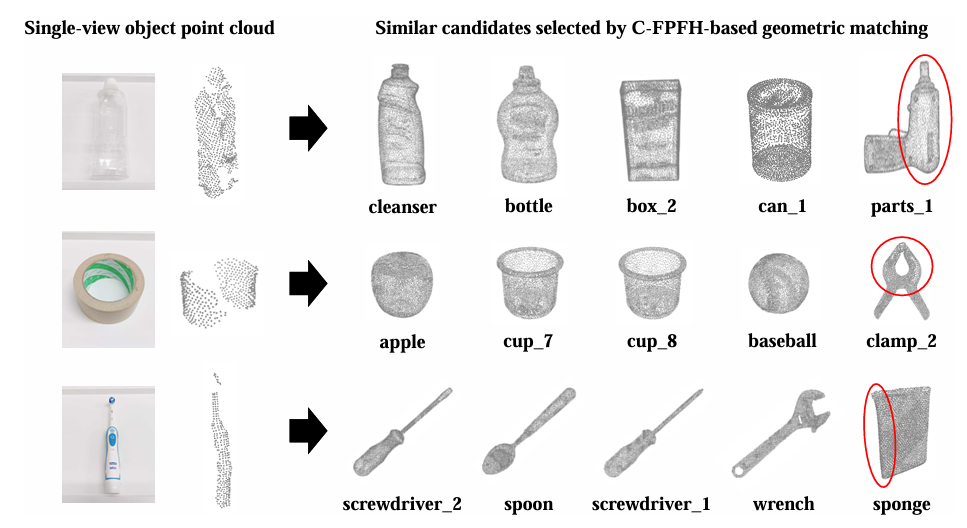
图4|使用基于 C-FPFH 的几何匹配方法,从单视角物体点云中识别相似模型的测试结果
点云配准与抓取迁移
选出相似模型后,下一步是将该模型的抓取知识“迁移”给目标物体。
● 首先使用 PDM(基于平面检测)+ ICP 进行点云配准,比传统 RANSAC + ICP 更稳定,特别适用于不同但相似形状的点云;
● 获得每个候选模型的配准得分与变换矩阵,选出最优的作为抓取参考源;
● 依靠数据库中的预定义抓取动作(提前通过 mesh segmentation 生成),将其位姿映射到目标物体;
● 在仿真中使用 IKFast + 碰撞检测筛选出可行抓取方式。
模仿抓取与仿真执行
在候选抓取姿态中,系统会进行进一步筛查:
● 通过仿真排除碰撞或不可达姿态;
● 对于不合理抓取(如没有夹到物体、位置偏移等)进行剔除;
● 若首个模型所有抓取都无效,则依次尝试下一个候选模型。
该过程不依赖于场景模型,而是通过背景图像重建障碍物,这在实际部署中非常关键。
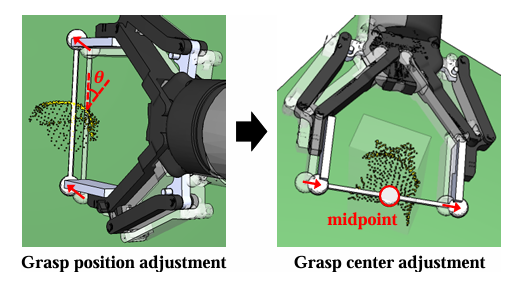
图5|两阶段抓取微调过程,包括抓取位置和抓取中心的调整,以优化最终的抓取质量
稳定性驱动的抓取微调
为了进一步提升抓取的可靠性,作者设计了两阶段抓取微调机制:
接触点微调:
● 利用射线检测法判断夹爪与物体接触点;
● 根据接触点法向与夹爪连线之间的夹角分类:
○ 角度小于 20°:认为抓取稳定;
○ 大于 40°:认为抓取不稳定,直接剔除;
○ 中间值:进入微调流程;
● 通过邻域搜索找出更合适的接触点,并调整抓取位置。
抓取中心微调:
● 防止夹爪两端夹持力不均;
● 通过 SOBB 算法获取两个交点中心作为理想抓取中心;
● 若位置偏差过大,则再进行位置修正。
如果调整后的抓取无法通过 IK 或发生碰撞,则该抓取姿态被丢弃。最终保留一组经过“优选+微调”的可执行抓取。

本文的实验主要围绕各种图标展开,因此小编也按照原文的思路把几个主要图表和背后的实验分析进行解读。
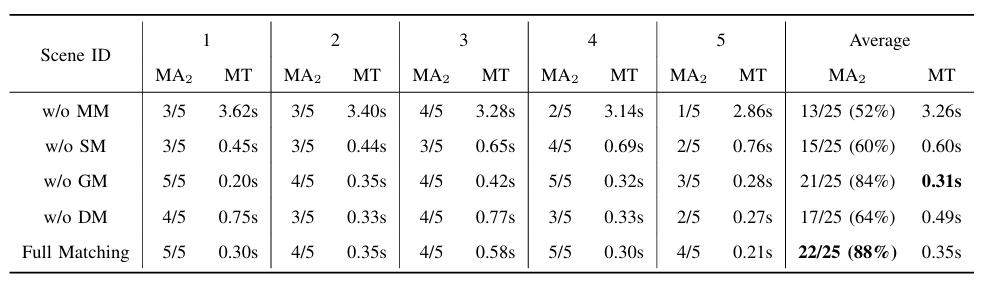
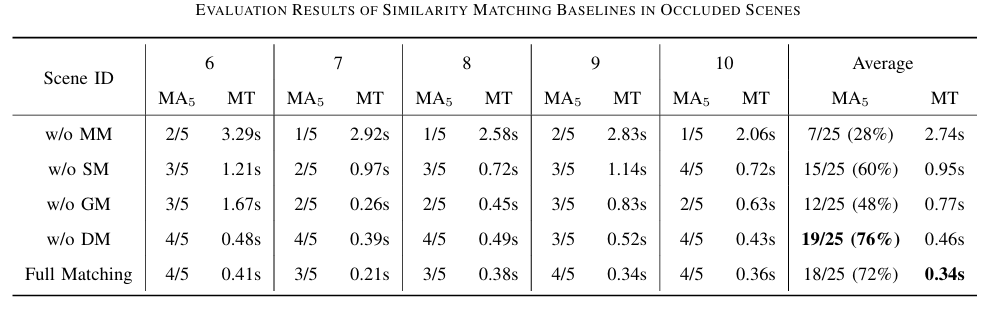
图6|五组方法对比实验结果(上表为无遮挡,下表为有遮挡)
对比内容:五组方法(分别去掉多层匹配、语义匹配、几何匹配、尺寸匹配 vs 完整方法)。
关键发现:
● 多层匹配(multi-level matching)显著提升匹配精度(Matching Accuracy)并减少匹配时间(Matching Time)。
● 去掉语义或尺寸匹配都会显著拉低准确率。
● 在非遮挡条件下,去掉几何匹配(w/o GM)影响不大,说明语义和尺寸信息足以锁定目标
● 遮挡条件下多层匹配仍表现最稳。
● 几何匹配(C-FPFH)成为关键组件,缺失该模块(w/o GM)导致匹配精度大幅下降。
● 有些情况下,尺寸匹配(Dimensional Matching)甚至误导识别,反而语义信息仍然具有鲁棒性。
● 完整方法在匹配时间上也最优,因其能快速缩小候选范围。
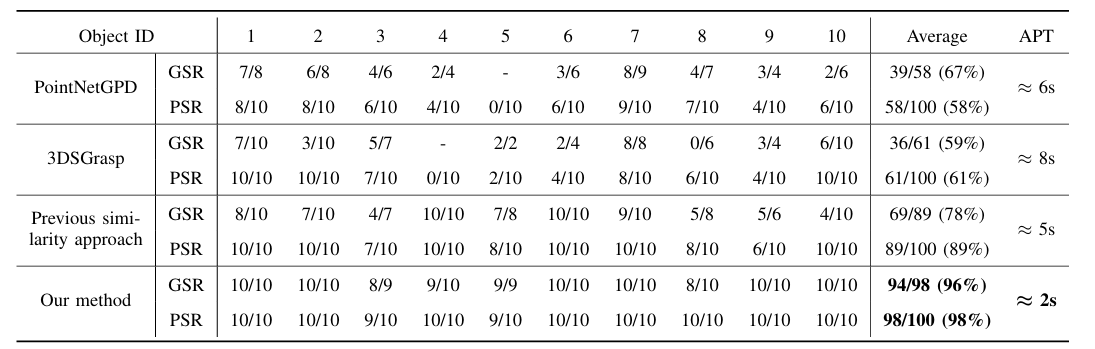
图7|耽误提抓取实验结果
对比方法:PointNetGPD、3DSGrasp、旧版相似性方法 vs 本文方法。
指标:
● 抓取成功率(GSR)
● 规划成功率(PSR)
● 平均规划时间(APT)
关键发现:
● 本文方法 GSR 和 PSR 均显著高于其他方法,说明其具备更强的泛化能力和规划可执行性。
● 本方法的平均规划时间远低于其他对比方法,归因于多层匹配减少了搜索空间。
● 对比图(下图)显示:PointNetGPD 抓取姿态经常不稳定;3DSGrasp 在光滑物体上重建精度低;旧方法缺乏抓取微调,稳定性差。

图8|不同抓取方法的抓取可视化对比结果
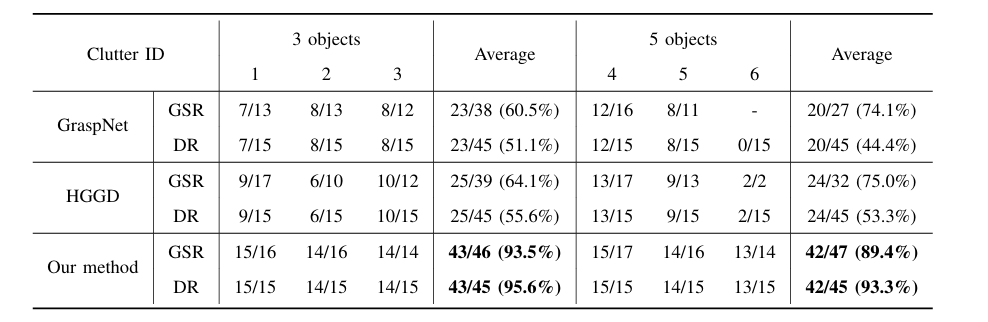

图9|杂乱场景抓取实验结果及可视化
对比方法:GraspNet、HGGD、本文方法。
关键指标:
● 抓取成功率(GSR)
● 清理率(Declutter Rate, DR)
关键发现:
● 本方法在复杂遮挡、多物体干扰下仍能有效执行高质量抓取,整体 GSR 和 DR 表现最优。
● GraspNet、HGGD 在面对小型/薄物体(如Clutter 6)时几乎无法生成可执行抓取。
● 本方法通过“多线程+障碍物建模”实现高效解耦识别与抓取,显著优于 end-to-end 检测策略
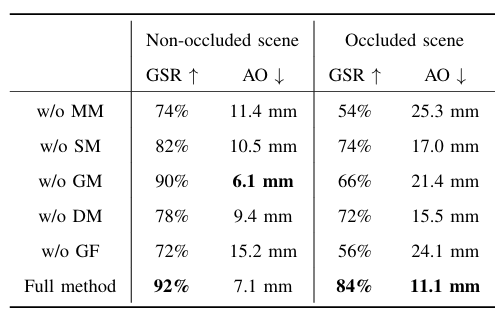
图10|消融实验结果
新增指标:Average Offset(AO,物体回放后偏移值,用于衡量抓取稳定性)。
关键发现:
● 去掉几何匹配模块(w/o GM)在遮挡条件下抓取精度显著下降,进一步验证 C-FPFH 在不完整点云匹配中的作用。
● 去掉抓取微调模块(w/o GF)也会导致抓取稳定性变差(AO增大),强调微调环节对于单视角条件下抓取成功率的重要性。

本研究提出了一种新颖的单视角未知物体抓取框架,核心在于引入多层次的相似性匹配方法,能够从已有数据库中精准识别相似参考模型,以指导未知目标物体的抓取。该匹配过程综合评估了语义、几何和尺寸三个方面的相似性,从而优化候选模型的筛选。
研究特别提出了 C-FPFH 描述子,这是一种新型的几何特征描述符,能够高效评估观测物体的局部点云与数据库中完整模型点云之间的相似度,尤其在应对遮挡问题上展现出极高的有效性。此外,方法还集成了大语言模型(LLM)辅助语义匹配,提出了 SOBB 结构用于精确的尺寸匹配,并构建了基于平面检测的点云配准方法(PDM registration)用于模仿式抓取规划,同时引入了双阶段微调策略以优化最终抓取质量。
大量真实场景实验表明,该方法在孤立场景与杂乱场景中抓取未知物体时,在各项指标上均大幅超越现有基准方法,展现出对传感器噪声和环境变化的极强鲁棒性——这一点是现有基于学习的方法难以实现的。
未来,研究团队计划将该方法拓展至动态场景与更复杂的操作任务中,进一步融合更多任务知识,超越传统“抓取”范畴。


















 2854
2854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









