




摘要
1. 摘要精翻
最近,多目标跟踪(MOT)吸引了越来越多的关注,并取得了显著的进展。然而,现有的方法倾向于使用各种不同的基础模型(例如,检测器和嵌入模型)以及不同的训练或推理技巧。因此,构建一个用于公平比较的优秀基准是至关重要的。在本文中,我们首先重新审视了一个经典的跟踪器,即DeepSORT,然后从目标检测、特征嵌入和轨迹关联等多个角度对其进行了显著的改进。我们提出的名为StrongSORT的跟踪器,为MOT社区贡献了一个强大且公平的基准。此外,我们提出了两种轻量级的即插即用算法,以解决MOT中两个固有的“缺失”问题:关联丢失和检测丢失。具体来说,与大多数在高计算复杂度下将短轨迹关联成完整轨迹的方法不同,我们提出了一种无外观链接模型(AFLink),它可以在没有外观信息的情况下执行全局关联,从而在速度和精度之间取得了良好的平衡。此外,我们提出了基于高斯过程回归的**高斯平滑插值(GSI)**来缓解检测丢失问题。AFLink和GSI可以轻松地集成到各种跟踪器中,而带来的额外计算成本可以忽略不计(在MOT17上,每张图像分别增加1.7毫秒和7.1毫秒)。最后,通过将StrongSORT与AFLink和GSI相融合,我们最终的跟踪器(StrongSORT++)在多个公开基准(即MOT17、MOT20、DanceTrack和KITTI)上取得了业界顶尖(state-of-the-art)的成果。代码已在 [GitHub链接] 上开源。
索引词 — 多目标跟踪,基准,AFLink,GSI。
2. 核心信息提炼
这篇摘要告诉我们四件核心事情:
- 动机 (Why):现有的MOT方法由于组件(检测器、Re-ID模型)不统一,难以公平比较。因此,学术界急需一个强大、公平的新基准。
- 方案一 (What):作者选择了经典算法DeepSORT,并用更强的检测器、特征提取器等技术对其进行了全面升级,得到了StrongSORT。这个StrongSORT就是他们提出的新基准。
- 方案二 (How to improve further):作者还提出了两个原创的轻量级插件来解决MOT的通用难题:
- AFLink:用于连接断裂的轨迹,但它不看外观(速度快),只看时空信息。
- GSI:用于填充轨迹中因遮挡而丢失的帧,比传统的线性插值更智能。
- 最终成果 (Result):将StrongSORT与AFLink、GSI结合,诞生了最终的完全体——StrongSORT++,它在多个权威数据集上都达到了SOTA(State-of-the-Art)的水平。
3. 逐句精读解析
Abstract—Recently, multi-object tracking (MOT) has attracted increasing attention, and accordingly, remarkable progress has been achieved.
- 解析:标准的“开场白”。
However, the existing methods tend to use various basic models (e.g., detector and embedding models) and different training or inference tricks. As a result, the construction of a good baseline for a fair comparison is essential.
- 解析:点出核心痛点。MOT系统通常是模块化的(检测 -> 跟踪)。如果A方法用了SOTA的检测器,B方法用了去年的检测器,那么即使A方法的跟踪性能更好,也很难说清是它的跟踪策略更优,还是仅仅因为它“站的起点更高”(检测器更好)。同理,不同的Re-ID模型(embedding models)和技巧也会导致不公平。因此,作者强调,建立一个强大且所有人都认可的**基准(baseline)**至关重要,这样未来的研究者就可以在这个基准上进行公平的“苹果对苹果”的比较。
In this paper, a classic tracker, i.e., DeepSORT, is first revisited, and then is significantly improved from multiple perspectives such as object detection, feature embedding, and trajectory association. The proposed tracker, named StrongSORT, contributes a strong and fair baseline to the MOT community.
- 解析:提出了第一个解决方案。他们没有完全从零开始设计新算法,而是选择了一个大家耳熟能详的DeepSORT。
- revisited(重新审视):意味着他们分析了DeepSORT的优点和缺点。
- significantly improved from multiple perspectives:他们对DeepSORT进行了全方位的“魔改”,包括换上更好的检测器,更好的Re-ID模型(feature embedding),以及改进关联算法(trajectory association)。
- 这个升级版就是StrongSORT,它的定位就是上面提到的那个“强大且公平的基准”。
Moreover, two lightweight and plug-and-play algorithms are proposed to address two inherent “missing” problems of MOT: missing association and missing detection.
- 解析:在基准之上,提出了原创性贡献。他们指出了MOT中两个长期存在的难题:
- missing association (关联丢失):一个目标因为被遮挡等原因丢失后,再次出现时被当成了一个新目标,导致ID切换。轨迹断了。
- missing detection (检测丢失):目标在某几帧被完全遮挡,检测器根本没检测到它。轨迹中出现了“空洞”。
- lightweight (轻量级) 和 plug-and-play (即插即用) 是这两个算法的重要特性,意味着它们计算开销小,且可以方便地应用到其他跟踪器上。
Specifically, unlike most methods… we propose an appearance-free link model (AFLink)… and achieve a good balance between speed and accuracy.
- 解析:详细介绍第一个插件AFLink。
- 它解决的是missing association问题。
- unlike most methods:它的独特之处在于appearance-free (无外观)。传统的做法是比对前后两个人的Re-ID特征,看长得像不像,这种方法计算量大。AFLink反其道而行之,只利用时空信息(运动轨迹、时间差)来判断,因此在速度和精度上做到了很好的平衡。
Furthermore, we propose Gaussian-smoothed interpolation (GSI) based on Gaussian process regression to relieve missing detection.
- 解析:详细介绍第二个插件GSI。
- 它解决的是missing detection问题。
- 它的技术核心是高斯过程回归 (Gaussian process regression)。简单来说,当一个轨迹中间有几帧丢失时,最简单的方法是线性插值(画直线连接断点),但物体的运动往往不是匀速直线。GSI用一种更高级的非线性方法来预测丢失帧的位置,使得轨迹更平滑、更真实。
Finally, by fusing StrongSORT with AFLink and GSI, the final tracker (StrongSORT++) achieves state-of-the-art results on multiple public benchmarks…
- 解析:展示最终成果。将“升级后的基准”和“两个原创插件”结合起来,就组成了最终的SOTA跟踪器——StrongSORT++。并通过在多个权威数据集(MOT17, MOT20等)上的优异表现来证明其强大。这为论文的贡献提供了坚实的实验证据。
通过这番精读,我们可以清晰地看到作者的行文逻辑:指出问题 -> 提出基准方案 -> 提出原创改进方案 -> 组合方案并验证效果。这是一个非常经典且有力的研究范式。
I. INTRODUCTION
1. 引言部分的核心脉络
这篇引言的逻辑非常清晰,层层递进,可以概括为以下几个步骤:
- 背景介绍:首先定义什么是多目标跟踪(MOT),并指出当前主流的技术范式是“先检测后跟踪”(Tracking-by-Detection, TBD)。
- 点出问题:直接切入在摘要中提到的核心痛点——由于各研究使用的检测器、Re-ID模型、训练数据和技巧五花八门,导致算法之间难以进行公平比较。
- 提出方案一 (构建基准):为了解决上述问题,作者提出重振DeepSORT。他们认为DeepSORT的跟踪范式本身没有过时,只是其内部组件(检测器等)太老旧。通过为其换上最先进的组件,就能打造一个强大而公平的新基准——StrongSORT。
- 提出方案二 (原创贡献):在基准之上,作者进一步指出了MOT中普遍存在的两个“缺失”问题(关联丢失和检测丢失),并对现有解决方案的不足(计算量大、依赖外观、不考虑运动信息)进行了批判。
- 展示原创方案:针对上述不足,正式引出本文的两个核心原创贡献——无外观链接模型 (AFLink) 和 高斯平滑插值 (GSI),并强调了它们的轻量级和即插即用特性。
- 成果预告与贡献总结:最后,将StrongSORT与两个新模块结合成StrongSORT++,预告了其在多个基准测试上的SOTA性能,并用一个列表清晰地总结了本文的三大贡献。
2. 分段精读解析
第一部分:背景与主流范式 (Paragraph 1)
原文大意:多目标跟踪(MOT)旨在逐帧检测和跟踪特定类别的所有目标,在视频理解中至关重要。近年来,MOT领域一直由“先检测后跟踪”(TBD)范式主导。TBD首先在每一帧进行目标检测,然后将MOT问题转化为一个数据关联任务。TBD方法通常先提取外观和/或运动嵌入,然后执行二分图匹配。得益于高性能的目标检测模型,TBD方法因其出色性能而备受青睐。
- 解析:
- Tracking-by-Detection (TBD):这是理解现代MOT算法的基石。它的流程是两步走的:1. Detection:在视频的每一帧,用一个强大的目标检测器(如YOLO系列)找出所有感兴趣的目标。2. Tracking:通过某些策略(数据关联)将不同帧中的同一个目标连接起来,形成轨迹。
- Data Association Task:数据关联是TBD的核心。你可以把它想象成一个跨帧的“连连看”游戏。系统需要判断第一帧的“张三”,是不是第二帧的那个“张三”。
- Bipartite Graph Matching:这是实现数据关联的一种常用数学工具(例如,匈牙利算法)。它帮助在上一帧的轨迹和当前帧的检测框之间找到一个最优的匹配方案。
- 关键信息:作者开篇就明确,他们工作的舞台是TBD这个主流范式,并点明了TBD的成功很大程度上依赖于检测器的性能。这为后文“更换更强的检测器”埋下了伏笔。
第二部分:问题陈述与研究动机 (Paragraph 2-4)
原文大意:由于MOT是目标检测和ReID的下游任务,近期工作倾向于使用各种检测器和ReID模型来提升性能,这使得构建公平比较变得困难。使用各种外部数据集进行训练也加剧了这个问题。此外,各种训练和推理技巧也被用来提升性能。为了解决这些问题,本文提出了一个简单而有效的基准——StrongSORT。我们重访了经典的DeepSORT,它因其简单性、可扩展性和有效性而被选中。我们认为,DeepSORT之所以性能落后,是因为它的技术组件过时了,而不是其跟踪范式本身有问题。具体来说,我们为DeepSORT配备了一个强大的检测器和嵌入模型,并借鉴了近期工作中的一些推理技巧。仅仅通过这些先进组件的装备,就得到了我们提出的StrongSORT,并且它能在MOT17和MOT20上取得SOTA级别的结果。
- 解析:
- 这是全文立论的基石。作者一针见血地指出了领域内的“混乱”现状,并给出了自己的核心论断。
- 不公平比较的三个来源:1. 模型不统一 (检测器/ReID模型);2. 训练数据不统一 (外部数据集);3. 技巧不统一 (各种tricks)。
- 选择DeepSORT的理由:simplicity, expansibility and effectiveness (简单、可扩展、有效)。这意味着DeepSORT的框架清晰,容易理解和修改,并且其核心思想是管用的。
- 核心论断:outdated techniques, rather than its tracking paradigm。这句话非常有力。它为“重振DeepSORT”提供了理论依据——不是要推倒重来,而是要“旧瓶装新酒”。DeepSORT的“瓶子”(跟踪框架)是好的,只需要把“旧酒”(老的检测器和ReID模型)换成“新酒”。
- StrongSORT的诞生:通过“换件升级”——用更强的检测器、更强的Re-ID模型、更强的推理技巧来武装DeepSORT——就得到了StrongSORT。
第三部分:StrongSORT的三大动机 (Bulleted List)
原文大意:StrongSORT的动机可以总结如下:
• 它可以作为不同跟踪方法之间公平比较的基准,特别是对于TBD类跟踪器。
• 与弱基准相比,一个更强的基准能更好地展示新方法的有效性。
• 精心收集的推理技巧可以无需重新训练就应用在其他跟踪器上,有益于学术界和工业界。
- 解析:
- 动机一:回应前文痛点,提供一个公平的竞技平台。
- 动机二:这是一个非常深刻的见解。如果你的基准太差(比如原始DeepSORT),那么任何一个小改动都可能带来巨大的性能提升,这会夸大新方法的实际效果。而如果在一个非常强的基准(StrongSORT)上还能取得提升,那才真正说明你的新方法是真金不怕火炼。
- 动机三:强调了工作的实用性和通用性。他们整理的这些“tricks”是可迁移的,可以直接给别人用,非常有价值。
第四部分:两个“缺失”问题与现有方案的不足 (Paragraph 6-7)
原文大意:MOT任务中有两个“缺失”问题:关联丢失和检测丢失…对于关联丢失问题,一些方法使用全局链接模型来关联短轨迹…虽然这些方法提升了性能,但它们依赖于计算密集型的模型,特别是外观嵌入…相比之下,我们提出的AFLink只利用时空信息…。对于检测丢失问题,线性插值被广泛使用…然而,它忽略了插值过程中的运动信息…
- 解析:
- 关联丢失 (Missing Association):轨迹中断,一个目标被赋予了多个ID。常发生在长时遮挡后。
- 检测丢失 (Missing Detection):轨迹中有空白,目标在某几帧完全没被检测到。
- 对现有方案的批判:
- 批判全局链接模型:太慢、太耗资源(computation-intensive),而且过度依赖外观特征,如果目标外观相似或变化大,就容易出错。
- 批判线性插值:太简单粗暴(ignores motion information),无法模拟真实的非线性运动。
- 通过批判现有方案的不足,为引出自己的原创方案AFLink和GSI的优越性做好了铺垫。
第五部分:AFLink和GSI的提出与贡献总结 (Paragraph 8-End)
原文大意:为了解决上述问题,我们提出了高斯平滑插值(GSI)…GSI也是一种检测噪声滤波器…AFLink和GSI都是轻量级、即插即用、模型无关和无外观的模型…实验表明它们能显著提升StrongSORT和其他SOTA跟踪器的性能…最终我们得到一个更强的跟踪器StrongSORT++。本文的贡献总结如下:…
- 解析:
- 正式介绍GSI,并指出它的双重身份:既是插值器,又是噪声滤波器(因为它可以平滑整个轨迹,消除由检测框抖动带来的噪声)。
- 再次强调了AFLink和GSI的四大优点:lightweight (轻量), plug-and-play (即插即用), model-independent (模型无关), appearance-free (无外观)。这些特性使得它们具有极高的实用价值。
- StrongSORT++ 正式登场,其构成是 StrongSORT + AFLink + GSI。
- 最后,用一个清晰的列表总结了三大贡献:1. 提出了强大的基准StrongSORT;2. 提出了两个新颖轻量的算法AFLink和GSI;3. 通过大量实验证明了方法的有效性。
II. RELATED WORK
1. 核心脉络
这一章结构非常清晰,围绕着本文提出的三个核心概念展开,分为三个小节:
- A. 分离式与联合式跟踪器 (Separate and Joint Trackers):这一节主要为本文选择DeepSORT-like这种分离式(Separate)跟踪范式提供理由。它将MOT方法分为两大类,分析了各自的优劣,并特别提到了一种“无外观”的趋势,最终落脚点是:尽管无外观方法速度快,但在复杂场景下鲁棒性差,因此我们坚持使用基于外观的经典范式,并证明其有效性。
- B. MOT中的全局链接 (Global Link in MOT):这一节是为本文提出的第一个原创贡献AFLink做铺垫。它介绍了“全局链接”(或称离线轨迹关联)这个子任务,列举了多种现有方法(如TNT, TPM, GIAOTracker等),并指出它们的共同问题:严重依赖计算昂贵的外观特征。最后引出本文的AFLink,强调其只用运动信息,更轻更快。同时,它还与一个同样只用运动信息的LGMTracker进行对比,强调AFLink模型更简单、训练更快。
- C. MOT中的插值 (Interpolation in MOT):这一节是为本文提出的第二个原创贡献GSI做铺垫。它首先指出最常用的线性插值方法的缺陷:忽略运动信息。然后介绍了一些更复杂的插值或平滑方法(如V-IOUTracker, MAT, MAATrack),并指出它们的共同问题:需要引入额外的、耗时的模块(如单目标跟踪器、CMC模型)。最后引出本文的GSI,强调其在不引入额外复杂组件的情况下,仅靠高斯过程回归(GPR)就高效地解决了问题。同时,它也与一个最相似的GPR应用进行对比,强调应用场景和方法的不同。
2. 分段精读解析
A. 分离式与联合式跟踪器
原文大意:MOT方法可分为分离式和联合式。分离式跟踪器遵循TBD范式,先定位后关联…联合式跟踪器则联合训练检测及其他组件…近来,一些研究放弃了外观信息,只依赖高性能检测器和运动信息,速度很快…然而,放弃外观特征会导致在复杂场景下鲁棒性差。本文中,我们采纳了DeepSORT-like的范式…来证明这个经典框架的有效性。
- 解析:
- 分类学:作者首先建立了MOT方法的两种主要流派。
- Separate Trackers (分离式):就是TBD范式,检测和跟踪是两个独立的步骤。DeepSORT、StrongSORT都属于这一类。优点是灵活,可以随意更换更好的检测器或Re-ID模型。缺点是速度可能较慢,因为需要分别运行两个大模型。
- Joint Trackers (联合式):将检测和跟踪(甚至Re-ID)放在一个模型里进行端到端(end-to-end)的训练。代表作有FairMOT、JDE。优点是速度快、效率高。缺点是模型耦合度高,训练复杂,不够灵活。
- 点出新趋势与隐患:作者敏锐地观察到近年来出现了一股“无外观信息”的潮流(如ByteTrack、OC-SORT),这些方法速度飞快,性能也很高。但他紧接着指出了这种方法的潜在风险:poor robustness in more complex scenes(在更复杂的场景中鲁棒性差)。例如,在需要长时重识别的场景下,没有外观信息几乎是不可能完成任务的。
- 表明立场:在分析完各种流派后,作者明确了自己的选择——we adopt the DeepSORT-like paradigm。他们不是在追逐“无外观”的潮流,而是要返璞归真,证明基于外观的经典范式通过现代化改造后,依然是强大且有效的。这既是对自己选择的辩护,也含蓄地指出了那些“无外观”方法可能存在的局限性。
- 分类学:作者首先建立了MOT方法的两种主要流派。
B. MOT中的全局链接
原文大意:关联丢失是MOT的一个核心问题。为了利用全局信息,一些方法使用全局链接模型来优化跟踪结果…(列举了TNT, TPM, ReMOT, GIAOTracker等方法)…虽然这些方法效果显著,但它们依赖于带来高计算成本的外观特征。相比之下,我们提出的AFLink只利用运动信息…AFLink与LGMTracker有相似的动机,后者也用运动信息关联轨迹…然而,AFLink表明,通过精心设计的框架和训练策略,一个更简单、更轻量的模块同样能行…AFLink在MOT17上只需要10多秒训练…
- 解析:
- 定义子任务:Global Link,即在初步跟踪(通常是在线跟踪)完成后,进行一次“全局回看”,把那些被打断的轨迹(tracklets)重新连接起来。这通常是一个离线(offline)处理步骤。
- 文献综述与批判:作者列举了一系列相关工作,并精准地指出了它们的共同命门——rely on appearance features, which bring high computational cost。这是一种非常高效的写作手法,通过归纳现有工作的共性弱点,来反衬自己方法的创新性。
- 凸显AFLink的创新点:
- 对比主流:主流方法用外观,AFLink不用,只用运动信息,因此更轻更快。
- 对比同类 (LGMTracker):LGMTracker同样只用运动信息,但它的模型设计interesting but complex(有趣但复杂)。而AFLink证明了simpler and more lightweight(更简单轻量)的模型也能奏效,并且训练和测试速度极快(10+秒 vs. 通常需要数小时)。这进一步强调了AFLink在效率和简洁性上的巨大优势。
C. MOT中的插值
原文大意:线性插值常被用来填补轨迹中的空缺,但它忽略了运动信息…为了解决这个问题,一些策略被提出来…(列举了V-IOUTracker, MAT, MAATrack等)…所有这些方法都引入了额外的、耗时的模型…作为性能提升的代价。相反,我们提出的方法基于高斯过程回归(GPR)算法来建模非线性运动…在没有额外耗时组件的情况下,我们的GSI算法在准确性和效率上取得了很好的平衡…与我们GSI最相似的工作是,它也用GPR…然而,它的应用场景不同…并且我们提出了一个自适应的平滑因子…
- 解析:
- 定义问题与基线方法:问题是“检测丢失”,基线方法是“线性插值”,其缺陷是ignores motion information。
- 文献综述与批判:作者再次运用了相同的策略。列举了V-IOUTracker、MAT等更高级的方法,并指出它们的共性弱点——apply extra models… in exchange for performance gains。意思是,为了提升性能,它们引入了新的复杂模块(如单目标跟踪器SOT、相机运动补偿CMC),导致整个系统变得更臃肿、更慢。
- 凸显GSI的创新点:
- 对比主流:主流方法靠“堆模块”,GSI不堆,只用一个优雅的数学工具GPR就解决了问题,因此在accuracy and efficiency之间取得了更好的平衡。
- 对比同类 ():同样是使用了GPR,作者从两个方面划清了界限:a. 应用场景不同(他们做的是通用MOT,做的是监控视频里的事件检测);b. 方法有改进(他们提出了adaptive smoothness factor自适应平滑因子,而不是用固定的超参数)。
III. STRONGSORT
本节的目标是清晰地拆解DeepSORT的核心工作流程。作者将其总结为一个双分支框架(two-branch framework),并详细介绍了每个分支的功能和关键技术。
- 引言部分 (Paragraph 1):开宗明义,本章的目标是介绍如何将DeepSORT升级为StrongSORT。作者非常坦诚地声明,本章(指介绍StrongSORT的部分)不包含算法层面的创新 (do not claim any algorithmic novelty)。他们的贡献在于清晰地理解并用先进技术重装DeepSORT,从而提供一个强大的基准。
A. Review of DeepSORT
原文大意:我们简要总结DeepSORT为一个双分支框架,即一个外观分支和一个运动分支…
- 解析:这是一个非常好的概括。它帮助读者从高层次理解DeepSORT的并行工作模式。
外观分支 (Appearance Branch)
原文大意:在外观分支中…应用深度外观描述子(一个简单的CNN)来提取外观特征。它利用一个特征库机制来存储每个轨迹过去100帧的特征。当新检测框到来时,计算其特征fj与第i个轨迹的特征库Bi之间的最小余弦距离d(i, j)…这个距离被用作关联过程中的匹配成本。
- 解析:
- Deep Appearance Descriptor:这就是DeepSORT名字里“Deep”的由来。它用一个小的卷积神经网络(CNN)来提取一个向量,这个向量就代表了目标的“外观”。
- Feature Bank:每个被跟踪的目标都有一个“相册”,里面存放着它最近100次被拍到的“照片”(特征向量)。
- 最小余弦距离 (Smallest Cosine Distance):当一个新的检测框出现时,不是只和目标上一帧的特征比,而是和它“相册”里所有的100个特征都比一遍,取那个**最相似的(距离最小的)**作为最终的相似度得分。这样做的好处是,即使目标的外观因为角度、光照发生短暂变化,只要它和历史上的某个样子相似,就依然能被识别出来,增加了鲁棒性。
- 匹配成本 (Matching Cost):距离越小(越相似),成本就越低,在后续的匈牙利匹配中就越有优势。
运动分支 (Motion Branch)
原文大意:在运动分支中,卡尔曼滤波算法负责预测轨迹在当前帧的位置…它通过一个两阶段过程工作:状态预测和状态更新…(公式2-6)…给定轨迹的运动状态和新来的检测框,马氏距离被用来测量它们之间的时空不相似性。
- 解析:
- 卡尔曼滤波 (Kalman Filter):这是运动跟踪领域的基石算法。它假设一个物体做匀速直线运动(或者更复杂的运动模型),并基于这个假设来预测它在下一时刻的位置。当新的观测(检测框)到来时,它会结合预测和观测来得到一个更准确的最终位置。
- 两阶段过程:1. 预测 (Predict):根据上一帧的状态,猜测这一帧物体应该在哪里。2. 更新 (Update):用这一帧实际的检测框位置来修正这个猜测。
- 马氏距离 (Mahalanobis Distance):你可以把它理解为一种考虑了不确定性(协方差)的距离。它衡量的是一个点(新的检测框)距离一个分布(卡尔曼滤波预测的位置分布)有多远。相比欧氏距离,它更科学,因为它考虑了预测在不同方向上的不确定性。例如,对于一个水平移动的物体,卡尔曼滤波对水平位置的预测会很准(不确定性小),对垂直位置的预测可能会差一些(不确定性大)。马氏距离会把这种差异考虑进去。
关联策略 (Association Strategy)
原文大意:DeepSORT将这个运动距离(马氏距离)作为一个门(gate),来过滤掉不可能的关联。之后,提出级联匹配算法来解决关联任务…其核心思想是给予更频繁被看见的物体更高的匹配优先级。每个子问题都用匈牙利算法解决。
- 解析:
- 门控 (Gating):这是一个剪枝步骤。如果一个检测框离某个轨迹的预测位置太远(马氏距离超过阈值),系统就认为它们不可能是同一个物体,直接“拉黑”,后续连计算外观相似度的步骤都省了。
- 级联匹配 (Matching Cascade):这是DeepSORT关联逻辑的精髓。它体现了一种**“尊老爱幼”**的思想。
- “老”:指那些连续匹配了很多帧的、非常稳定的轨迹(more frequently seen objects)。
- “幼”:指那些刚出现几帧,或者时断时续的不稳定轨迹。
- 匹配流程:先处理最“老”的轨迹,让它们优先挑选当前帧的检测框进行匹配。匹配完后,剩下的检测框再给次“老”的轨迹匹配。以此类推。
- 好处:防止一个稳定的长老轨迹被一个短暂出现的新轨迹“抢走”了本该属于它的检测框。这能有效减少ID切换,提升跟踪的连贯性。
B. StrongSORT
作者将改进分为了两大类:先进模块 (Advanced modules) 和 推理技巧 (inference tricks)。我们将逐一拆解这些改进点。
1. 核心脉络
本节的逻辑就像一个系统升级清单。作者系统地评估了DeepSORT的每一个环节,并用当前更先进的技术或策略进行了替换或增强。
- 更换核心引擎 (Advanced Modules):
- 检测器:将过时的Faster R-CNN换成了顶级的YOLOX-X。
- 特征提取器:将简单的CNN换成了更强大的Re-ID模型BoT (Bag of Tricks)。
- 这是最基础也是最重要的升级,好比给汽车换上了更强劲的发动机。
- 优化关键算法 (Inference Tricks):
- 特征更新:用**EMA(指数移动平均)**替代了DeepSORT的特征库(Feature Bank),以增强鲁棒性并提高效率。
- 运动补偿:引入**ECC(增强相关系数)**来补偿相机自身的运动,让卡尔曼滤波更准确。
- 卡尔曼滤波:引入NSA卡尔曼滤波,使其能根据检测框的置信度自适应地调整噪声,变得更“智能”。
- 代价矩阵:将单纯的外观代价,改为外观代价和运动代价的加权和,综合两种信息进行匹配。
- 匹配策略:用简单的**普通匹配(Vanilla Matching)**取代了DeepSORT复杂的级联匹配(Matching Cascade),这是一个反直觉但非常深刻的改进。
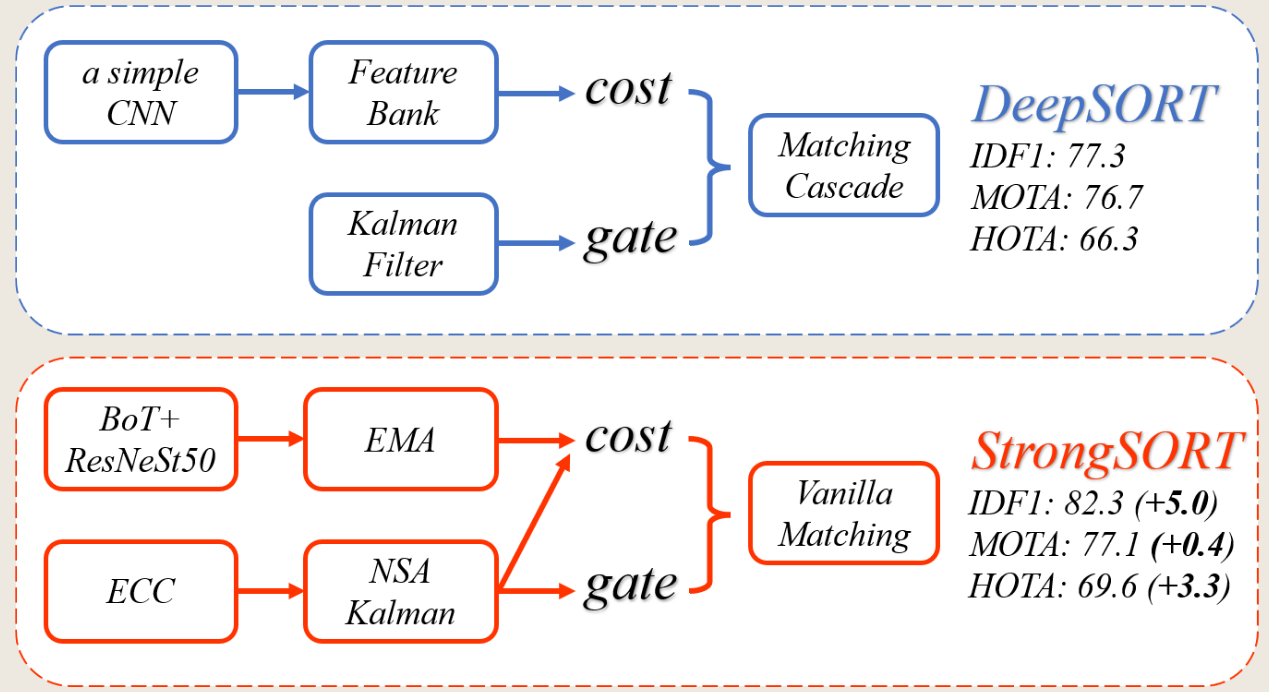
2. 逐一精读解析
1. 先进模块 (Advanced Modules) - 更换引擎
- 做了什么?
- 检测器:replace the detector with YOLOX-X。
- 外观特征提取器:replace the original simple CNN with a stronger appearance feature extractor, BoT。
- 为什么这么做?
这是最直观的改进。DeepSORT诞生于2017年,其使用的检测器和Re-ID模型在当时是先进的,但现在已经远远落后。跟踪算法的性能上限很大程度上受限于输入(检测框和特征)的质量。所谓“Garbage in, garbage out”(垃圾进,垃圾出),使用过时的组件不可能得到SOTA的结果。 - 有什么好处?
- YOLOX-X 是当时最先进的目标检测器之一,能提供更准确、更可靠的检测框,大大减少了漏检和误检,为后续跟踪打下了坚实的基础。
- BoT (Bag of Tricks for Re-ID) 是一个非常强大的行人重识别模型,它提取的特征much more discriminative(更具区分度)。这意味着它能更好地区分不同的行人,即使他们穿着相似,也能有效降低ID切换的概率。
2. EMA - 更智能的特征更新策略
- 做了什么?
用EMA (Exponential Moving Average, 指数移动平均) 更新策略,替代了DeepSORT的特征库 (Feature Bank) 机制。 - 为什么这么做?
DeepSORT的特征库会存储过去100帧的特征,虽然这保留了长期信息,但它有一个致命弱点:对噪声敏感(sensitive to detection noise)。如果某几帧的检测结果很差(比如目标被严重遮挡,检测框不准),提取出的特征就是“污染”的特征。特征库会把这些坏特征和好特征同等地位地存起来,干扰后续的匹配。 - 有什么好处?
- 平滑噪声:EMA通过公式 新特征 = α * 旧历史特征 + (1-α) * 当前帧特征 来更新。当α=0.9时,它表示当前轨迹的特征主要(90%)继承自历史,只从当前帧获取一小部分(10%)新信息。这就像一个平滑滤波器,单帧的噪声特征很难对长期累积的平滑特征产生巨大影响,从而使特征表示更稳定、更鲁棒。
- 提升效率:EMA只需要存储一个历史特征向量即可,而特征库需要存储100个。这不仅减少了内存消耗,也加快了计算速度(reduces the time consumption),一举两得。
3. ECC - 相机运动补偿
- 做了什么?
引入ECC (Enhanced Correlation Coefficient Maximization) 模型来进行相机运动补偿 (Camera Motion Compensation, CMC)。 - 为什么这么做?
卡尔曼滤波的基本假设是:物体的运动是平滑的。但是,如果相机本身在移动(比如手持拍摄的抖动、车载相机的转弯),那么在画面中,一个静止的物体也会产生运动。这种“伪运动”会严重干扰卡尔曼滤波的预测,使其失效。 - 有什么好处?
- 分离真实运动与相机运动:ECC通过分析连续两帧图像的像素,估算出相机的整体运动(平移和旋转)。然后,在将检测框位置送入卡尔曼滤波之前,先从中减去相机的运动。
- 你可以把它想象成一个“数字防抖”系统。它让卡尔曼滤波“看到”的是一个稳定世界中的物体真实运动,从而使其预测更加精准。
4. NSA Kalman - 可信度感知的卡尔曼滤波
- 做了什么?
借鉴了GIAOTracker中的NSA (Noise-adaptive) 思想,来动态调整卡尔曼滤波的测量噪声协方差 Rk。 - 为什么这么做?
传统的卡尔曼滤波很“死板”,它认为所有检测框(测量值)的可信度都是一样的。但实际上,一个置信度为0.99的清晰检测框,显然比一个置信度为0.4的模糊检测框更可信。vanilla Kalman filter is vulnerable w.r.t. low-quality detections(原始卡尔曼滤波在面对低质量检测时很脆弱)。 - 有什么好处?
- 引入“信任”机制:通过公式 新噪声R̃k = (1 - ck) * 旧噪声Rk(其中ck是检测置信度),实现了高置信度 -> 低噪声,低置信度 -> 高噪声的自适应调整。
- 更智能的更新:在卡尔曼滤波的更新步骤中,测量噪声R越小,意味着系统越相信本次的测量值(检测框),更新时检测框所占的权重就越大。反之,R越大,系统就越相信自己的预测,而对本次测量值持怀疑态度。这使得滤波器的状态更新更加精准和鲁棒。
5. Motion Cost & Vanilla Matching - 更强大的关联策略
- Motion Cost (代价矩阵改进)
- 做了什么?:将匹配的代价函数从单纯的外观距离,改为了外观距离和运动距离(马氏距离)的加权和 C = λAa + (1 − λ)Am。
- 为什么?:DeepSORT只用运动距离做“门控”,而不用它来计算最终匹配成本,这浪费了宝贵的运动信息。
- 好处:让匹配决策同时考虑“长得像不像”和“在不在该在的位置”,关联更可靠。λ=0.98表明外观依然是主要依据,但运动信息也起到了辅助作用。
- Vanilla Matching (匹配策略改进)
- 做了什么?:抛弃了DeepSORT的级联匹配,换成了简单的全局线性分配(即一次性对所有轨迹和检测框进行匹配)。
- 为什么?(这是最深刻的洞见):作者发现,级联匹配这种“尊老爱幼”的策略,本质上是一种为了弥补早期跟踪器性能不足而设计的“拐杖”。当跟踪器的各个组件(检测、Re-ID)都变得非常强大后,关联的模糊性大大降低了。此时,级联匹配这种带有很强先验约束的策略,反而会限制算法找到全局最优解,limits the performance。
- 好处:对于一个强大的跟踪器,其特征已经足够有区分度,不再需要复杂的优先级规则来避免混淆。去掉这个“束缚”,反而能让匈牙利算法在全局范围内自由寻找到最优匹配,从而大幅提升了IDF1指标(关联准确性)。
IV. STRONGSORT++
A. AFLink
1. 核心脉络
AFLink (Appearance-Free Link model) 的设计思路和介绍逻辑非常清晰:
- 动机 (Motivation):首先批判现有“全局链接”方法的两大痛点:
- 计算昂贵且依赖外观:主流方法(如GIAOTracker)需要用大型模型(如ResNet50)提取外观特征,速度慢,且在遮挡时不可靠。
- 超参数繁多:需要手动调整大量阈值和权重,调参困难,鲁棒性差。
- 核心思想 (Core Idea):基于上述动机,作者设计的AFLink必须是无外观的 (appearance-free),即只利用时空信息 (spatiotemporal information) 来预测两个轨迹片段是否应该被连接。
- 模型架构 (Architecture):设计一个专门的网络来解决这个连接预测问题。
- 输入:两个轨迹片段(tracklets),每个片段包含最近30帧的 (帧号, x, y) 坐标。
- 特征提取:
- 时间模块 (Temporal Module):用7x1的卷积沿着时间维度提取每个轨迹的动态特征。
- 融合模块 (Fusion Module):用1x3的卷积在特征维度上(跨f,x,y三个通道)融合信息。
- 决策:将两个轨迹提取出的特征向量进行处理(池化、压缩、拼接),最后送入一个MLP(多层感知机)来输出一个连接置信度分数。
- 训练与推理 (Training & Inference):
- 训练:将其作为一个二元分类问题来训练。输入一对轨迹,如果它们属于同一个真实目标,标签就是1,否则是0。使用标准的二元交叉熵损失函数进行优化。
- 推理:用训练好的模型为所有可能的轨迹对打分,然后结合一些简单的时空约束(比如两个轨迹在时间上不能离太远)来过滤掉明显不可能的连接。最后,将这个问题构建为一个线性分配任务(用匈牙利算法求解),根据模型预测的连接分数来找到全局最优的连接方案。
2. 分段精读解析
引言部分
原文大意:我们在第三节中提出了一个强大的基准。在本节中,我们介绍两个轻量级、即插即用、模型无关、无外观的算法,即AFLink和GSI,来进一步解决关联丢失和检测丢失的问题。我们将最终的方法称为StrongSORT++…
- 解析:清晰地承上启下。点明StrongSORT是基准,而AFLink和GSI是锦上添花的原创模块。StrongSORT++ = StrongSORT + AFLink + GSI。
A. AFLink
原文大意:全局链接被用于追求高精度的关联。然而,它们通常依赖于计算昂贵的组件和大量的超参数…例如,GIAOTracker…有六个超参数要设置…而且,过度依赖外观特征在遮挡时可能很脆弱。受此启发,我们设计了一个无外观模型AFLink…
- 解析:
- 批判性地引入问题:作者精准地指出了现有技术的三个核心缺陷:1. 贵 (computationally expensive),2. 烦 (numerous hyperparameters),3. 脆 (vulnerable to occlusion)。
- GIAOTracker作为“靶子”:通过具体例子GIAOTracker,让读者对“烦”有了具体概念(six hyperparameters),这使得作者的批评非常有力。
- 解决方案的核心特性:appearance-free。这个设计原则直接解决了“贵”和“脆”的问题,因为不提取外观特征自然就快了,也不怕遮挡时外观信息不可靠。
原文大意:图3展示了AFLink模型的双分支框架。它接收两个轨迹Ti和Tj作为输入…每个轨迹包含最近N=30帧的帧号和位置…不足30帧的轨迹用零填充…一个时间模块…沿时间维度进行卷积…然后,一个融合模块…整合来自不同特征维度(即f, x, y)的信息…两个结果特征图被池化、压缩、拼接…最后,一个MLP被用来预测关联的置信度分数…
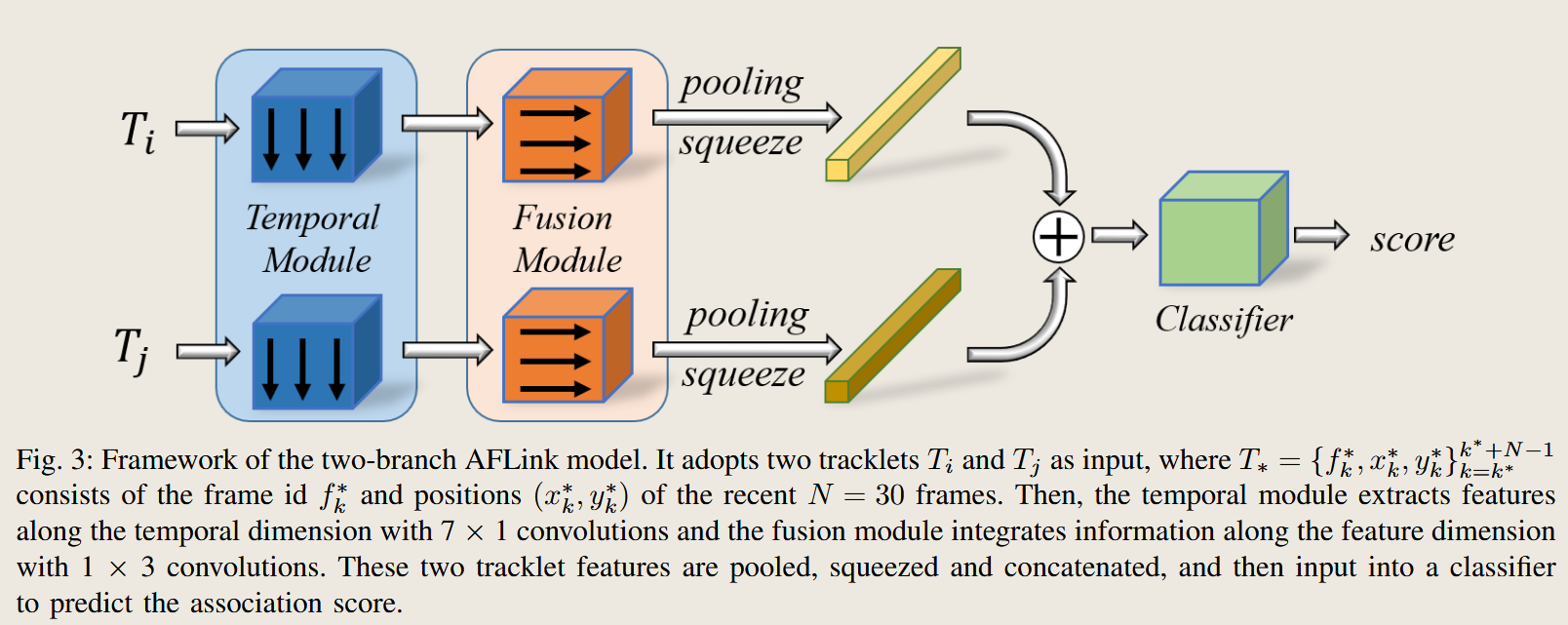
- 解析:
- 模型输入:非常纯粹,只有**(frame_id, x, y)**。这再次强调了其appearance-free的特性。N=30是一个经验选择,代表模型会观察轨迹过去大约一秒钟(假设30fps)的行为模式。
- 模型结构设计的巧思:
- 时间模块 (Temporal Module):使用7x1的卷积核,意味着卷积操作只在时间维度上进行,不会混合不同坐标轴的信息。它的作用是捕捉轨迹随时间变化的模式,比如速度、加速度、方向变化等。
- 融合模块 (Fusion Module):使用1x3的卷积核,这次卷积操作只在特征维度上进行,即在f, x, y这三个通道之间。它的作用是学习帧号、x坐标、y坐标这三者之间的相互关系。
- 双分支与权重不共享:weights… are not shared。这意味着模型为输入的两个轨迹分别学习一套独立的特征提取参数。这比共享权重的孪生网络(Siamese Network)更灵活,允许模型捕捉到两个轨迹各自独特的运动模式。
- 从输入到输出的流程:时空坐标序列 -> 动态特征提取 -> 跨维度信息融合 -> 特征整合 -> MLP分类。整个流程清晰且专门为轨迹关联任务设计。
原文大意:在训练期间,关联过程被构建为一个二元分类任务…用二元交叉熵损失进行优化…在关联(推理)时,我们用时空约束过滤掉不合理的轨迹对。然后,将全局链接问题作为一个线性分配任务来解决…
- 解析:
- 训练:这是一个非常标准的监督学习范式。通过构建正负样本对(应该连的和不应该连的),让模型学会区分。
- 推理:这是一个两步走的策略。
- 过滤 (Filtering):先用简单的规则(比如两个轨迹在时间上间隔不能超过30帧,在空间上距离不能太远)进行一次粗筛,去掉绝大多数无意义的匹配组合,减少计算量。
- 分配 (Assignment):对通过粗筛的轨迹对,用AFLink模型打分。然后,将这个问题建模成一个二分图匹配问题,用匈牙利算法(或者更高效的求解器)来找到一个能让总连接置信度最高的全局最优解。
B. GSI
1. 核心思想:从“菜鸟助理”到“国画大师”
想象一下,我们有一幅画,上面用点记录了一个物体的运动轨迹。但是,由于遮挡,中间有几处点是空白的,需要我们把它们补上。
- 线性插值 (Linear Interpolation, LI):这是我们的“菜鸟助理”。他的方法很简单,拿出尺子,在两个断开的点之间画一条笔直的线。
- 优点:简单,快速。
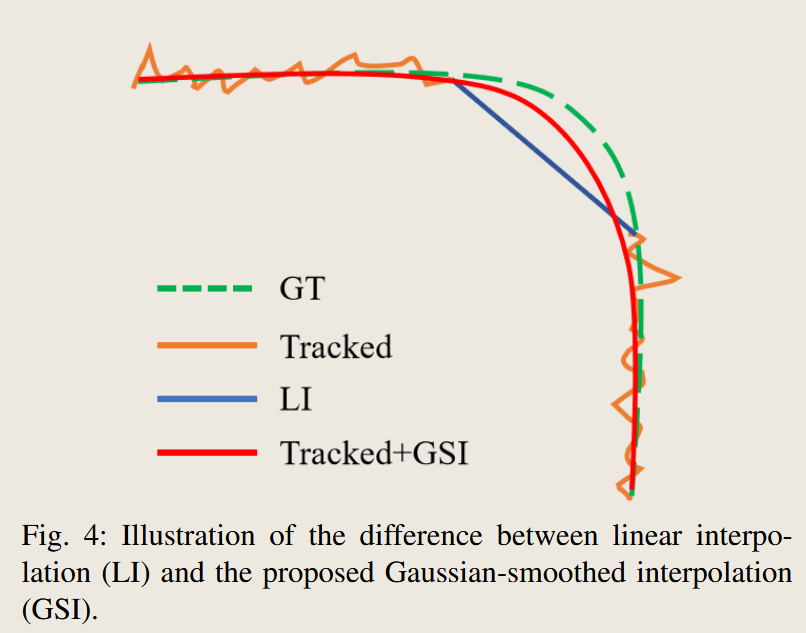
- 缺点:非常死板。物体的运动很少是完美的直线,所以画出来的线很生硬,有明显的转折。而且,如果原始的点本身就有些抖动(检测噪声),他会忠实地连接这些抖动的点,让整条线看起来更不自然。(这对应图4中的蓝色线条)
- 高斯平滑插值 (GSI):这是我们请来的“国画大师”(高斯过程回归)。他补全画作的方式完全不同:
- 观察全局:他不会只看缺口两端的点,而是会仔细审视整条已经存在的轨迹,理解这条轨迹的“笔锋”和“神韵”(即运动的趋势、速度和加速度)。
- 平滑噪声:他注意到原始的点有些抖动(noisy jitter),不像是真实的运动。他会先轻轻地将这些抖动的点进行平滑,让现有的轨迹变得流畅自然。
- 挥毫补全:在理解了整条轨迹的“神韵”并平滑了噪声之后,他才会下笔,用最符合整体风格的、一条平滑优美的曲线来补全空白的部分。
- GSI的精髓:它不是简单地填充空缺,而是对整条轨迹进行“重新诠释”和“艺术加工”,使其既完整又平滑。这对应论文中的关键描述:solves both problems simultaneously by smoothing the entire trajectory。(这对应图4中的红色线条)
2. 解码背后的数学“咒语”
国画大师的技艺背后是深厚的数学功底。我们来逐一解读这些公式:
公式 (12): pt = f(i)(t) + ε
- 翻译:“我们观测到的那个有点抖动的位置点 pt,其实是由两部分组成的:一个真实、完美的潜在运动轨迹 f(i)(t),再加上一点点随机的‘手抖’(噪声)ε。”
- 大师的目标:GSI的任务就是从观测到的、不完美的 pt 中,反推出那个我们看不见的、完美的 f(i)(t)。
公式 (13): f(i) ∈ GP(0, k(·, ·))
- 翻译:“我们假设,那条完美的轨迹 f(i) 是遵循高斯过程 (GP) 这个‘艺术流派’的。”
- 什么是高斯过程? 你可以把它理解为一种定义“曲线函数”的规则。它本身不是一条特定的曲线,而是能生成无数条平滑曲线的“生成器”。
- k(·, ·) 是什么? 这是核函数 (kernel),它定义了这个艺术流派的核心“画风”。
- 本文使用的径向基函数核 (RBF kernel) exp(…) 的画风是:“时间上离得越近的点,它们的位置也应该越相似。时间上离得越远,关系就越弱。” 这非常符合我们对物体连续运动的直觉。
公式 (14): P* = K(F*, F)(K(F, F) + σ²I)⁻¹P
- 翻译:这是高斯过程回归的核心预测公式。它看起来非常吓人,但它的本质思想是:
- “为了预测出空白处 F* 的新位置 P*,大师会综合考虑所有已知点 (F, P) 的信息。”
- “他会根据自己的‘画风’(由核函数 k 导出的协方差矩阵 K)来判断,每个已知点对空白处的点应该有多大的‘发言权’(权重)。”
- 最终,空白处的新位置 P* 就是所有已知点位置的一个极其智能的加权平均。这个权重不仅考虑了距离,还考虑了整体的运动趋势和噪声大小。
公式 (15): λ = τ * log(τ³/l)
- 翻译:这是GSI相比标准GPR的一个重要创新点。它让大师的“画风”变得自适应 (adaptive)。
- λ (lambda) 是核函数里的一个超参数,控制着曲线的平滑程度。λ 越大,画出的曲线越平滑、变化越缓慢;λ 越小,曲线越能贴近数据点,可能变化更剧烈。
- l 是当前轨迹的长度。
- 自适应的智慧:
- 当轨迹很短时 (l 很小):大师看到的信息很少,没法确定详细的运动模式。为了保险起见,他会选择一个较大的 λ,画出一条非常平滑、保守的曲线。
- 当轨迹很长时 (l 很大):大师已经观察了很久,对物体的运动模式了如指掌。他更有信心,可以选择一个较小的 λ,画出一条更贴合观测数据、更能反映细节变化的曲线。
- 这使得GSI既能在数据少的时候保持稳健,又能在数据多的时候充分利用信息。
3. GSI的优势总结
- 超越线性插值:它不仅填充空缺,还考虑了全局的运动信息,使得轨迹更真实、更平滑。
- 双重功效:它同时解决了**检测丢失(填充空缺)和检测噪声(平滑轨迹)**两个问题。
- 轻量级:与那些需要引入额外复杂模块(如单目标跟踪器、相机运动补偿模型)的方法相比,GSI只是一个纯粹的数学模型,没有增加额外的系统组件,做到了 lightweight。
- 智能自适应:通过自适应的平滑因子 λ,使其对不同长度的轨迹都具有很好的鲁棒性。
通过GSI,StrongSORT++不仅能“续上”断掉的轨迹,还能把整条轨迹“打磨”得更加光滑,极大地提升了最终输出的轨迹质量。


















 6740
6740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









