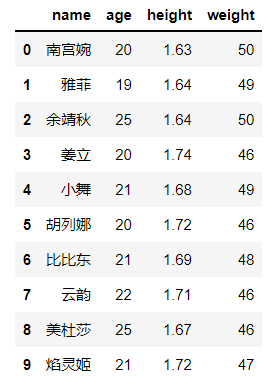
names =['南宫婉','雅菲','余靖秋','姜立','小舞','胡列娜','比比东','云韵','美杜莎','焰灵姬']
df = pd.DataFrame({"name":names,"age":[random.randint(18,25)for i inrange(len(names))],"height":[round(random.uniform(1.6,1.75),2)for i inrange(len(names))],"weight":[random.randint(45,50)for i inrange(len(names))],})




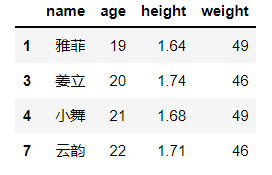
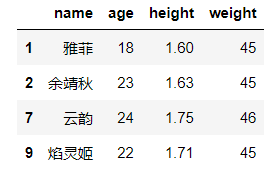
 本文通过实例展示了使用Pandas库在Python中筛选数据的多种方法,包括filter、map、apply、query和eval等函数的运用,帮助读者加深对数据查询和筛选的理解。文章覆盖了基于字符串长度和首字母的筛选操作,旨在提升数据处理能力。
本文通过实例展示了使用Pandas库在Python中筛选数据的多种方法,包括filter、map、apply、query和eval等函数的运用,帮助读者加深对数据查询和筛选的理解。文章覆盖了基于字符串长度和首字母的筛选操作,旨在提升数据处理能力。

















 4746
4746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









