




 本文深入探讨并发编程中的重排序现象,包括编译器优化、指令级并行及内存系统重排序,解析数据依赖性及其对程序执行的影响,并介绍as-if-serial语义确保单线程程序结果不变。
本文深入探讨并发编程中的重排序现象,包括编译器优化、指令级并行及内存系统重排序,解析数据依赖性及其对程序执行的影响,并介绍as-if-serial语义确保单线程程序结果不变。
相关阅读
在上篇文章 深入讲解并发编程模型之概念篇 比较详细分析了并发编程模型的相关概念。这篇文章就深入讲解下关于重排序的问题。
再讲重排序
重排序分为:
- 编译器优化的重排序
- 指令级并行的重排序
- 内存系统的重排序
其中,只要对单线程的语义(实际上可以理解为单线程执行结果)不产生影响,编译器在编译源代码的时候就可以重新编排程序语句的执行顺序。这就是编译器优化的重排序。
如果对程序执行结果不产生影响,处理器可以优化程序指令的运行顺序,一般是采用并行的方式来执行指令。那么,如何判断改变指令的执行方式不会影响程序运行结果呢?其实可以根据指令之间是否有数据依赖。,具有数据依赖的指令不能更改执行顺序,没有的可以修改,不会影响程序执行结果。这就是指令级并行的重排序。什么是数据依赖性,下面会讲。
接下来,什么是内存系统重排序呢?我们先来了解以下有关处理器缓存的知识。
我们知道,处理器为了加速对数据的读取,采用了三级缓存的策略。下面,先来分析CPU三级缓存是什么回事。
- CPU缓存的定义
CPU与内存之间的临时数据交换器,它的出现是为了解决CPU运行处理速度与内存读写速度不匹配的矛盾——缓存的速度比内存的速度快多了。
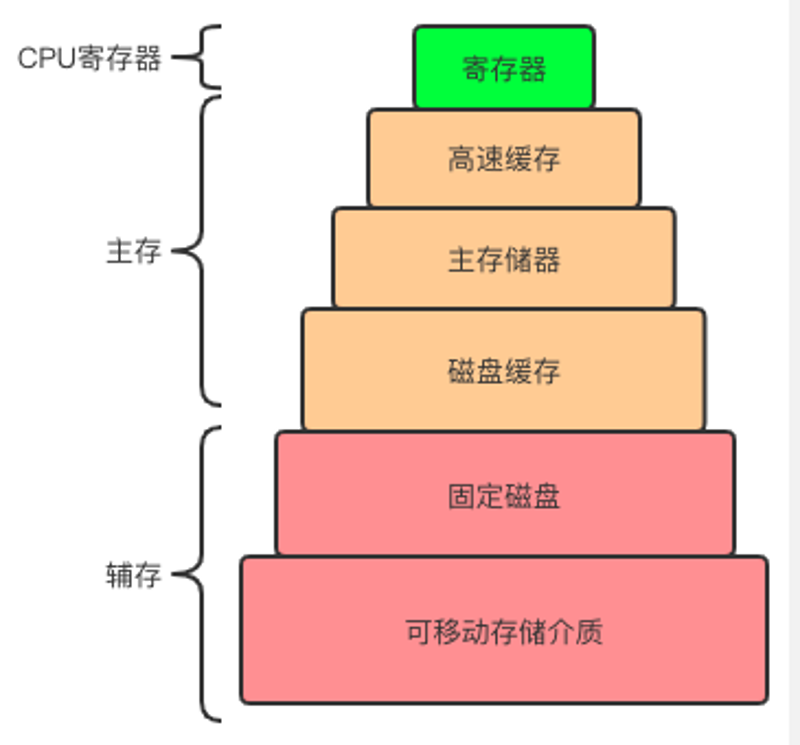
首先,我们来看看CPU三级缓存在计算机存储系统中处于哪个位置:
计算机存储系统:
CPU三级缓存:
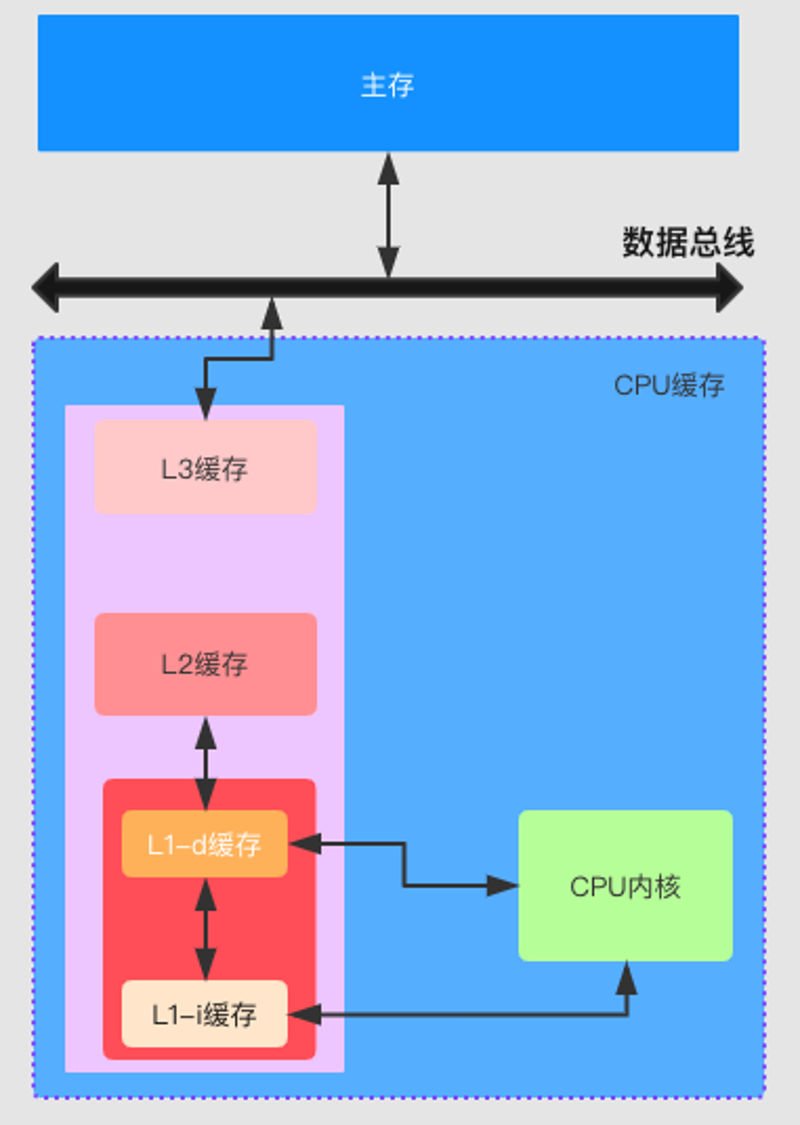
名词解释
- L1-d缓存:一级数据缓存
- L1-i缓存:一级指令缓存
- L2缓存:二级缓存
- L3缓存:三级缓存
执行速度:L1 > L2 > L3
我们可以看到,CPU缓存是直接和主存进行数据交换的。因为CPU缓存执行速度远远大于主存,我们可以把常用的数据缓存在CPU缓存中,大大提高指令的的执行速度。CPU缓存具体的工作原理不在这里讲,有兴趣的同学可以翻看相关书籍。
回到我们讲的重排序。这里我们就可以分析以下内存系统重排序了。
在上面CPU三级缓存系统中,实现缓存一致性机制有两种。
- 总线加锁机制
如果CPU读取一个数据,就会通过总线来对这个数据加锁。那么其它线程就不能对这个数据进行读写操作。其实这样的实现是有很大问题的,在多线程环境下,如果出现多个线程同时读写相同临界量,那么这种加锁效率是非常低下的。
- MESI协议(一种缓存一致性协议)
MESI它的工作原理可以阅读这篇文章 MESI--CPU缓存一致性协议 。
在内存系统中,处理器执行的程序指令有一部分是缓存在CPU缓存的,有一部分是需要在主存中获取的。那么,由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。(可以理解为是有些指令读写操作不一定按照程序对处理器的顺序要求来做,因为从缓存获取指令进行操作,远远快于从主存获取指令进行操作)。这就是作者理解的内存系统重排序。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
- 写后读
写一个变量之后,在读这个变量。比如:a=1, b=a
- 写后写
写一个变量后,再写这个变量。比如a=1, a=2
- 读后写
读一个变量后,再写这个变量。比如:a=b, b=1
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考 虑。(言外之意就是数据依赖性不保证线程安全问题)
as-if-serial 语义
as-if-serial 语义的意思指
不管怎么重排序(编译器和处理器为了提高并行度), (单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守 as-if-serial 语义。
为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
总结
这篇文章和大家一起分析了重排序的三种方式和基本原理,又讲了数据依赖性的必要性以及as-if-serial语义的用途。大家掌握了这些就可以了,没必要再深究重排序的知识了。
总之,在不影响程序执行结果的前提下,重排序是为了加速程序指令执行速度。重排序只对单个线程内的程序指令执行结果不产生影响,但是多线程模式下,就算不存在数据依赖的指令,在重排序后有可能会影响程序的执行结果。
作者:深夜程猿
链接:https://juejin.im/post/5d6a1bb8e51d4562043f5751
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









