




 本文详细介绍了深度学习中常用的几种归一化技术,包括BatchNormalization (BN)、LayerNormalization (LN)、InstanceNormalization (IN)、GroupNormalization (GN)、SwitchableNormalization (SN)和WeightNormalization (WN)。BN通过缓解Internal Covariate Shift加速训练,而LN、IN、GN和WN各有适用场景,如LN适合RNN,IN适用于风格迁移,GN解决小batch问题,SN自动选择合适归一化,WN则在权值维度上进行归一化。各种归一化技术有其优缺点,选择需根据具体任务和网络结构来定。
本文详细介绍了深度学习中常用的几种归一化技术,包括BatchNormalization (BN)、LayerNormalization (LN)、InstanceNormalization (IN)、GroupNormalization (GN)、SwitchableNormalization (SN)和WeightNormalization (WN)。BN通过缓解Internal Covariate Shift加速训练,而LN、IN、GN和WN各有适用场景,如LN适合RNN,IN适用于风格迁移,GN解决小batch问题,SN自动选择合适归一化,WN则在权值维度上进行归一化。各种归一化技术有其优缺点,选择需根据具体任务和网络结构来定。
前言
- 数据规一化的作用:
- 调整数据分布,增加网络泛化度.
- 若每批数据分布不同,神经网络需要不断调整模型权重去适应不同的数据分布,因此可以增加训练速度.即缓解Internal Covariate Shift问题,将数据分布拉到激活函数的非饱和区,具有权重/数据伸缩不变性的特点.
- 起到缓解梯度消失/爆炸,加速训练,正则化的效果.
- 内部协方差转移internal convarite shift:
- 简设模型函数 y=f(θ,x)y=f(\theta,x)y=f(θ,x),训练时,每层网络的输入数据分布会不断变化,导致参数θ\thetaθ变化和y变化.
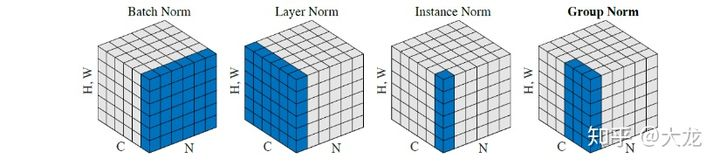
- 处理维度(B,C,H,W)数据时,
- BN:在batch上,对(C,H,W)做归一化.
- LN:在Channel上,对(B,H,W)做归一化.
- GN:在Channel上对C分组,即对(G,H,W)做归一化,其中G*K=C,将K个GN结果合并为最终归一化结果.
- IN:在图像像素上,对(H,W)做归一化.
- SN:是将BN LN IN结合,赋予不同权重,让网络自己去学习归一化层应该使用什么方法.
- WN:对模型权重进行归一化.
1.Batch Normalization(BN)
过程
- 预处理:
x(k)=x(k)−E[x(k)]Var[x(k)]x^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{Var[x^{(k)}]}x(k)=Var[x(k)]x(k)−E[x(k)] - 变换重构:
x(k)=γ(k)x(k)+β(k)x^{(k)}=\gamma^{(k)}x^{(k)}+\beta^{(k)}x(k)=γ(k)x(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3091
3091




 到【灌水乐园】发言
到【灌水乐园】发言









