




 博客先提及多目标跟踪评价指标及MOT数据集格式相关文章,接着介绍MOT格式示例。随后对多目标跟踪评价指标代码进行说明,包括项目地址、简便检测方法、代码流程,还列举了评价指标。最后给出单个和多个输出的例子。
博客先提及多目标跟踪评价指标及MOT数据集格式相关文章,接着介绍MOT格式示例。随后对多目标跟踪评价指标代码进行说明,包括项目地址、简便检测方法、代码流程,还列举了评价指标。最后给出单个和多个输出的例子。
前言
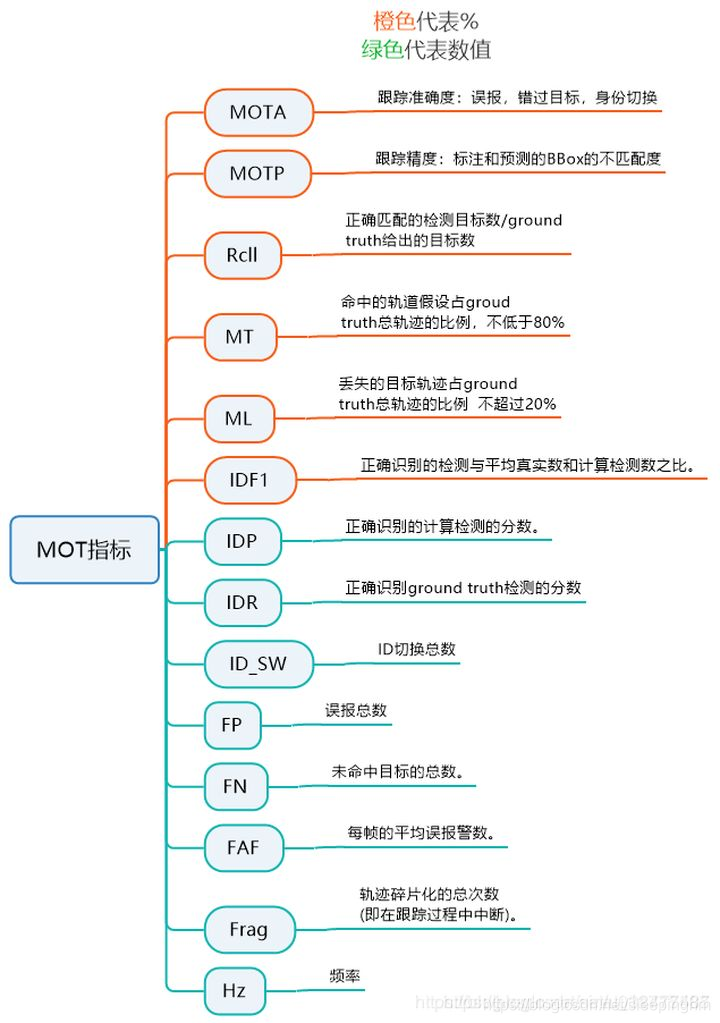
先看两篇文章:多目标跟踪评价指标介绍1,多目标跟踪评价指标介绍2,MOT数据集格式介绍。
MOT的格式,例如gt.txt:
1,0,1255,50,71,119,1,1,1
2,0,1254,51,71,119,1,1,1
3,0,1253,52,71,119,1,1,1
...
例如test.txt:
1,1,1240.0,40.0,120.0,96.0,0.999998,-1,-1,-1
2,1,1237.0,43.0,119.0,96.0,0.999998,-1,-1,-1
3,1,1237.0,44.0,117.0,95.0,0.999998,-1,-1,-1
...
代码介绍
项目地址,其中多个test衡量代码可以参考eval_motchallenge.py
以下介绍简便检测方法:
- 首先
pip install motemetrics - 代码的大概流程是:使用
mm.io.loadtxt()导入gt.txt和test.txt文件,然后使用mm.utils.compare_to_groundtruth()创建一个accumulator,再使用mh.compute()进行计算,最终通过mm.io.render_summary()得到规范化格式的输出。
import motmetrics as mm
import numpy < 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2407
2407













 到【灌水乐园】发言
到【灌水乐园】发言









