




第I部分 数据结构
Python数据模型
Python数据模型是使Python对象与语言特性良好协作的API集合。它形式化了语言构建块的接口(如序列、函数、迭代器、类等),可以将数据模型视为对Python作为框架的描述。
数据模型的关键价值
- 语言一致性:理解数据模型后,能对新功能做出合理预测
- Pythonic代码:正确使用数据模型是编写符合Python习惯代码的关键
- 框架式设计:与使用框架类似,我们实现被Python解释器调用的方法
特殊方法(Dunder Methods)也可以称其为魔术方法(magic method),特殊方法通常以双下划线开头和结尾(如__getitem__),由Python解释器自动调用,通常由特殊语法触发。根据Python官方文档,“任何在任何上下文中使用__*__名称的方式,如果不遵循明确记录的用法,都可能在没有警告的情况下失效。”
其使用案例如:
obj[key]语法由__getitem__方法支持- 当计算
my_collection[key]时,解释器实际调用my_collection.__getitem__(key)
实现特殊方法可使自定义对象支持并与以下基本语言结构交互:
| 语言特性 | 相关特殊方法示例 |
|---|---|
| 集合操作 | __len__, __getitem__, __contains__ |
| 属性访问 | __getattr__, __setattr__, __delattr__ |
| 迭代 | __iter__, __next__, __aiter__, __anext__ |
| 运算符重载 | __add__, __eq__, __lt__, __matmul__ |
| 函数调用 | __call__ |
| 字符串表示 | __repr__, __str__, __format__ |
| 异步编程 | __await__, __aenter__, __aexit__ |
| 对象生命周期 | __new__, __init__, __del__ |
| 上下文管理 | __enter__, __exit__ |
为什么使用len(collection)而非collection.len()?
这是Python数据模型设计理念的体现:
- 一致性:所有对象使用统一的len()函数
- 开放性:无需修改类定义即可为现有类型添加功能
- 清晰分离:功能与实现分离,符合"鸭子类型"哲学
Pythonic的卡牌组
collections.namedtuple 工厂函数
import collections
import random
# 定义Card类,使用namedtuple表示单张牌
# collections.namedtuple 是一个工厂函数,用于创建轻量级的、不可变的自定义元组子类
# collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
# -typename: 新创建的类的名称,以字符串形式提供
# -field_names: 定义新类的字段(属性)名称,支持以下几种格式:
# 1. 字符串,字段名用空格分隔 "rank suit"
# 2. 字符串列表 ['rank', 'suit']
# 3. 单个包含所有字段名的字符串(逗号分隔,可有空格)"rank, suit"
# -rename (可选): 布尔值,默认为 False 当设置为 True 时,如果提供的字段名是无效的 Python 标识符(如以数字开头、包含空格或特殊字符等),将被自动替换为位置名称 _0, _1, _2... 例如:field_names=['abc', 'def', '123'], rename=True -> 实际字段名为 ('abc', '_1', '_2')
# defaults (可选): 为字段提供默认值的可迭代对象(如元组或列表)
# 默认值从右向左应用到字段上
# 例如:fields=['x', 'y', 'z'], defaults=(0,) -> z 的默认值为 0
# fields=['x', 'y', 'z'], defaults=(1, 0) -> y=1, z=0
# module (可选): 显式指定创建的类的 __module__ 属性 这在序列化(如 pickle)时可能有用,用于正确记录类的来源模块 如果不指定,会自动从调用栈中推断
# Card类通过collections.namedtuple创建,而namedtuple本质上是tuple的子类 通过这个实现了Card类的不可变性
Card = collections.namedtuple('Card', ['rank', 'suit'])
# 添加了两个命名字段:rank 和 sui
# 自动实现了必要的特殊方法(__init__、__repr__、__eq__ 等)
命名元组的优势
可读性增强
与普通元组相比,命名元组通过字段名访问数据,而不是索引:
# 普通元组
card = ('7', 'diamonds')
print(card[0]) # 难以理解 0 代表什么
# 命名元组
card = Card(rank='7', suit='diamonds')
print(card.rank) # 清晰表明这是牌的点数
自动实现的有用方法
命名元组自动提供以下方法:
-
_make(iterable): 从可迭代对象创建实例card = Card._make(['A', 'spades']) -
_asdict(): 将实例转换为OrderedDictprint(card._asdict()) # OrderedDict([('rank', 'A'), ('suit', 'spades')]) -
_replace(**kwargs): 创建新实例,替换指定字段new_card = card._replace(rank='K') -
_fields: 返回字段名元组print(Card._fields) # ('rank', 'suit')
良好的字符串表示
card = Card('7', 'diamonds')
print(card) # Card(rank='7', suit='diamonds')
# 这比普通元组的表示 ('7', 'diamonds') 更具可读性。
这比普通元组的表示 ('7', 'diamonds') 更具可读性。
与普通元组兼容
# 命名元组仍然是元组的子类,所以可以像使用普通元组一样使用:
card = Card('7', 'diamonds')
print(card[0]) # '7'
print(len(card)) # 2
rank, suit = card # 解包
核心示例
class FrenchDeck:
"""一副标准的法式扑克牌"""
ranks = [str(n) for n in range(2, 11)] + list('JOKA') # 2-10, J, O, K, A
suits = 'spades diamonds clubs hearts'.split() # 黑桃, 方块, 梅花, 红心
def __init__(self):
"""初始化牌组,创建52张牌"""
self._cards = [Card(rank, suit) for suit in self.suits for rank in self.ranks]
# 通过实现两个特殊方法构建了一个Pythonic对象
def __len__(self):
"""返回牌组中的牌数"""
return len(self._cards)
def __getitem__(self, position):
"""支持索引访问"""
return self._cards[position]
# 花色排序值,用于自定义排序
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0)
def spades_high(card):
"""自定义排序函数:先按等级排序(A最高),然后按花色排序(黑桃>红心>方块>梅花)"""
rank_value = FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
def main():
# 创建牌组实例
deck = FrenchDeck()
# 演示len()函数
print(f"牌组总共有 {len(deck)} 张牌") # 牌组总共有 52 张牌
# 演示索引访问
print("\n第一张牌:", deck[0]) # 第一张牌: Card(rank='2', suit='spades')
print("最后一张牌:", deck[-1]) # 最后一张牌: Card(rank='A', suit='hearts')
# 演示random.choice 与标准库无缝衔接
print("\n随机抽取三张牌:")
for _ in range(3):
print(random.choice(deck))
# 随机抽取三张牌:
# Card(rank='J', suit='clubs')
# Card(rank='9', suit='clubs')
# Card(rank='J', suit='diamonds')
# 自动支持切片操作
print("\n前三张牌(切片操作):")
for card in deck[:3]:
print(card)
print("\n所有A(切片操作):")
for card in deck[12::13]:
print(card)
# 支持迭代和反向迭代
print("\n前5张牌(迭代):")
for i, card in enumerate(deck):
if i >= 5:
break
print(card)
print("\n最后3张牌(反向迭代):")
for i, card in enumerate(reversed(deck)):
if i >= 3:
break
print(card)
# 支持in操作符
# 由于实现了迭代协议,即使没有__contains__方法,in运算符也能工作
print("\nin操作符测试:")
print("Card('Q', 'hearts') in deck:", Card('Q', 'hearts') in deck)
print("Card('7', 'beasts') in deck:", Card('7', 'beasts') in deck)
# 支持自定义排序
print("\n按花色和等级排序(前5张和最后5张):")
sorted_deck = sorted(deck, key=spades_high)
print("排序后的前5张牌:")
for card in sorted_deck[:5]:
print(card)
print("\n排序后的最后5张牌:")
for card in sorted_deck[-5:]:
print(card)
if __name__ == "__main__":
main()
上述笔记通过一个简单的扑克牌示例,教会我们如何利用 Python 数据模型 来创建真正“Pythonic”的代码:通过实现少量的特殊方法(如 __len__ 和 __getitem__),我们可以让自定义对象无缝地融入 Python 的生态系统,使其表现得像内置序列类型一样,从而自然地支持 len()、索引、切片、迭代和 in 操作等核心语言特性;这体现了 Python 的核心哲学,一致性和组合优于继承,即无需复杂的继承体系,只需遵循数据模型的协议,就能充分利用 Python 强大的标准库(如 random.choice 和 sorted),用简洁、直观的方式构建功能丰富的类。FrenchDeck 的例子完美地诠释了 Pythonic 编程的核心思想:通过实现数据模型定义的少量特殊方法,就能让你的自定义对象获得强大的、符合直觉的行为。
FrenchDeck 类虽然简单,但通过 __len__ 和 __getitem__ 两个方法,自动获得了以下核心语言特性的支持:
- 序列协议 (Sequence Protocol):
- 对象可以像列表、元组等内置序列一样被处理。
- 长度查询 (
len()函数):- 可以使用内置函数
len(deck)来获取牌组中牌的数量。
- 可以使用内置函数
- 索引和切片访问 (
[]操作符):- 可以通过索引访问特定位置的元素:
deck[0],deck[-1]。 - 可以使用切片操作:
deck[:3],deck[12::13]。
- 可以通过索引访问特定位置的元素:
- 可迭代性 (Iterability):
- 对象可以直接在
for循环中使用:for card in deck: ...。 - 支持反向迭代:
for card in reversed(deck): ...。
- 对象可以直接在
- 成员资格测试 (
in操作符):- 可以使用
Card('Q', 'hearts') in deck来检查某张牌是否在牌组中。
- 可以使用
- 与标准库集成:
- 能够直接使用如
random.choice(deck)这样的标准库函数,因为random.choice需要一个序列。
- 能够直接使用如
关于 __contains__ 方法的说明
笔记中提到,即使没有实现 __contains__ 方法,in 操作符也能工作。这是因为 Python 有一个优雅的降级机制:如果一个类没有定义 __contains__ 方法,解释器会退而求其次,使用 __iter__ 方法进行顺序扫描来检查成员资格。正是因为 __getitem__ 的存在,Python 将 FrenchDeck 视为一个序列,从而提供了默认的迭代行为,这间接支持了 in 操作。
特殊方法的使用方式
**特殊方法主要由Python解释器自动调用,而非用户直接调用。**例如应使用内置函数(如 len(my_object)),而不是直接调用特殊方法(如 my_object.__len__())。
对于内置类型(如 list, str 等),len() 会直接访问底层C结构体(PyVarObject)中的 ob_size 字段,速度极快。对于用户定义的类,len() 会通过解释器调用 __len__ 方法。
大多数特殊方法的调用是隐式的,例如:
for i in x:
# 隐式调用 iter(x)
# 进而可能调用 x.__iter__() 或 x.__getitem__()
**通常应更多地实现特殊方法,而非在代码中显式调用它们。**唯一常见的直接调用是在子类的 __init__ 中调用父类的 __init__。需要调用时,优先使用 len(), iter(), str() 等内置函数,它们不仅调用特殊方法,还提供额外服务且性能更优。
二维向量类
创建一个表示二维欧几里得向量的类,支持向量加法、计算模长、标量乘法。
import math
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return f'Vector({self.x!r}, {self.y!r})'
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
# 返回一个新的Vector实例,而不会修改任一操作数
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
# 同上
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
| 方法 | 功能 |
|---|---|
__init__ | 初始化向量的x和y分量。 |
__repr__ | 提供对象的“官方”字符串表示,用于调试和开发。!r 确保使用 repr() 表示值。 |
__abs__ | 计算并返回向量的模(长度),使用 math.hypot(x, y) 计算直角三角形的斜边。 |
__bool__ | 定义向量的布尔值。零向量为 False,非零向量为 True。 |
__add__ | 实现 + 运算符。创建并返回一个新 Vector 实例,不修改原操作数。 |
__mul__ | 实现 * 运算符(右乘标量)。创建并返回一个新 Vector 实例。 |
当前
Vector类示例中,只实现了右乘(__mul__),而没有实现左乘。
在表达式 v * 3 中:
v是Vector类的实例,位于运算符*的左边。3是一个标量(整数或浮点数),位于运算符*的右边。
当 Python 解释器遇到 v * 3 时,它会尝试调用 v 对象的 __mul__ 方法,并将 3 作为参数传入。因此,__mul__ 方法处理的是 self * other 这种情况,即向量对象在左,标量在右。
所以,虽然我们称其为“标量乘法”,但从方法调用的角度看,__mul__ 实现的是左操作数是向量、右操作数是标量的乘法,也就是 vector * scalar。
# 当前实现支持的操作
v = Vector(3, 4)
print(v * 3) # 输出: Vector(9, 12) ✅ 正常工作
# 当前实现不支持的操作
print(3 * v) # 报错: TypeError: unsupported operand type(s) for *: 'int' and 'Vector'
当执行 3 * v 时:
- Python 首先尝试调用左操作数(即
3,一个int)的__mul__方法。 int类型的__mul__方法知道如何与另一个int或float相乘,但它不知道如何与一个Vector对象相乘。- 因此,
int.__mul__(v)失败,返回NotImplemented。 - Python 接着检查右操作数(即
v,一个Vector)是否定义了__rmul__方法。 - 在当前的
Vector类中,没有定义__rmul__方法。 - 由于两种尝试都失败了,Python 就抛出了
TypeError。
为了使标量乘法具有交换律(即 v * s == s * v),我们需要实现 __rmul__ 特殊方法。
__rmul__ 的含义是 “right-side multiplication” 或 “reflected multiplication”。它在以下情况下被调用:
当本类的对象出现在
*运算符的右边,而左边的操作数无法处理该运算时。
# 对算法进行修正
class Vector:
# ... 其他方法保持不变 ...
def __rmul__(self, scalar):
# 反射乘法,当标量在左边时调用
return self * scalar # 等同于调用 __mul__
# 或者直接写成: return Vector(self.x * scalar, self.y * scalar)
v = Vector(3, 4)
print(v * 3) # Vector(9, 12)
print(3 * v) # Vector(9, 12)
仅仅实现 __mul__ 而不实现 __rmul__ 会导致 API 设计上的缺陷。它破坏了标量乘法的交换律,使得用户的代码不够灵活,也违背了数学直觉。一个完整的、用户友好的数值类型模拟,通常需要同时实现 __mul__ 和 __rmul__。
字符串表示
Python 提供了两种特殊方法来控制对象的字符串表示,它们服务于不同的目的。
__repr__ 方法(开发者视角)
- 调用方式:由内置函数
repr()调用。 - 使用场景:
- 交互式控制台显示求值结果
- 调试器
%r格式化占位符- f-string 中的
!r转换字段(如{obj!r})
- 设计原则:
- 返回的字符串应明确无歧义。
- 最好能匹配重新创建该对象所需的源代码。例如,
Vector(3, 4)的__repr__返回'Vector(3, 4)',这非常清晰。 - 在
__repr__中,建议对属性使用!r来显示其标准表示,以区分Vector(1, 2)和Vector('1', '2')这样的情况。
def __repr__(self):
return f'Vector({self.x!r}, {self.y!r})'
[!NOTE]
!r是 Python 中的一种转换标志 (conversion flag),主要用于字符串格式化操作中。它的作用是将一个对象通过repr()函数转换为其“官方”或“开发者友好”的字符串表示形式。当你在格式化字符串(如 f-string 或
.format()方法)中使用!r时,Python 会调用该对象的__repr__特殊方法来获取其字符串表示。
- 在 f-string (格式化字符串字面量) 中
name = "Alice" print(f"Hello, {name!r}") # 输出: Hello, 'Alice' # 对比不使用 !r print(f"Hello, {name}") # 输出: Hello, Alice
{name}: 直接插入变量值,结果为Alice。{name!r}: 插入repr(name)的结果,即带引号的'Alice',这清晰地表明它是一个字符串。
- 在 str.format() 方法中
name = "Bob" print("Hello, {!r}".format(name)) # 输出: Hello, 'Bob'
- 在 % 格式化中 (经典方式)
name = "Charlie" print("Hello, %r" % name) # 输出: Hello, 'Charlie'
转换标志 等效函数 说明 !rrepr()获取对象的“官方”表示,通常明确无歧义,适合调试。 !sstr()获取对象的“可读”表示,适合向最终用户显示。 !aascii()类似于 !r,但会使用\x,\u或\U转义序列替换任何非 ASCII 字符。假设我们有一个自定义的
Vector类:class Vector: def __init__(self, x, y): self.x, self.y = x, y def __repr__(self): return f'Vector({self.x}, {self.y})' def __str__(self): return f'({self.x}, {self.y})' v = Vector(3, 4)使用不同的转换标志会产生不同的输出:
print(f"Vector repr: {v!r}") # Vector repr: Vector(3, 4) <- 调用 __repr__ print(f"Vector str: {v!s}") # Vector str: (3, 4) <- 调用 __str__ print(f"Vector: {v}") # Vector: (3, 4) <- 默认调用 __str__
__str__ 方法(用户视角)
- 调用方式:由内置函数
str()调用,并被print()函数隐式使用。 - 使用场景:返回适合向最终用户显示的、友好的字符串。
- 继承关系:如果一个类没有实现
__str__,Python 会退而求其次,使用__repr__的返回值作为后备。
实践建议
如果你只能实现其中一个,请选择
__repr__。
有 Java 或 C# 背景的程序员可能习惯于实现类似 toString() 的方法,倾向于只写 __str__。但在 Python 中,__repr__ 对于调试和开发至关重要。一个良好的 __repr__ 可以极大提升开发效率。
自定义类型的布尔值
在 Python 中,任何对象都可以用于布尔上下文(如 if 语句、and/or 操作)。
确定一个对象是真值还是假值时,Python 会按以下顺序进行:
- 如果实现了
__bool__方法,则调用它并返回其结果(必须是True或False)。 - 如果未实现
__bool__,但实现了__len__,则检查__len__的返回值:- 如果长度为零,返回
False。 - 否则,返回
True。
- 如果长度为零,返回
- 如果以上两者都未实现,默认所有用户定义的实例都是真值。
Vector 类中的实现
def __bool__(self):
return bool(abs(self))
- 概念清晰:如果向量的模(长度)为零,则为假值(即零向量),否则为真值。
- 计算开销:需要计算平方和再开方,相对耗时。
def __bool__(self):
return bool(self.x or self.y)
- 性能更优:避免了数学运算,直接检查 x 或 y 分量是否非零。
- 注意:必须用
bool()显式转换,因为or操作符可能返回非布尔值(如数字本身)。
容器API
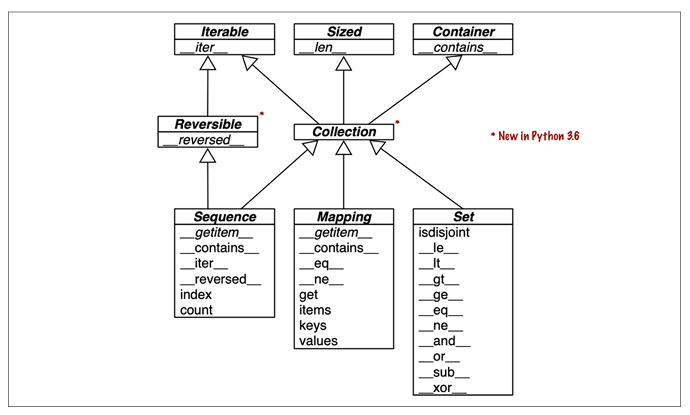
上图展示了 Python 基本集合类型的抽象基类 (ABCs) 结构。
| 抽象基类 (ABC) | 特殊方法 | 功能 |
|---|---|---|
| Sized | __len__ | 支持 len(obj) |
| Iterable | __iter__ 或 __getitem__ | 支持 for item in obj: 迭代 |
| Container | __contains__ | 支持 item in obj |
Collection ABC 统一了这三个接口。只要一个类实现了相应的特殊方法,就被认为“满足”了这些接口,无需显式继承。
-
Sequence (序列)
- 代表:
list,str,tuple - 关键方法:
__getitem__,__len__ - 特性:支持索引、切片、任意排序。
- 可逆性:是
Reversible的,因此支持reversed(seq)。
- 代表:
-
Mapping (映射)
- 代表:
dict,collections.defaultdict - 关键方法:
__getitem__,__iter__,__len__ - 特性:键值对存储。自 Python 3.7 起,
dict正式保证插入顺序,但这不等同于可以像序列一样随意重排。
- 代表:
-
Set (集合)
- 代表:
set,frozenset - 关键方法:
__contains__,__iter__,__len__ - 中缀运算符:所有集合操作都通过特殊方法实现:
a & b→a.__and__(b)(交集)a | b→a.__or__(b)(并集)a - b→a.__sub__(b)(差集)a ^ b→a.__xor__(b)(对称差)
- 代表:
Python 的集合类型并非通过复杂的继承树来强制行为,而是通过一套简单、一致的协议(即特殊方法)来定义。这体现了 Python 数据模型的核心思想:鸭子类型。**如果一个对象走起来像鸭子,叫起来像鸭子,那么它就是鸭子。**只要你的类实现了 __len__ 和 __getitem__,它就是一个“序列”,就能享受序列的所有便利。
特殊方法概述
The Python Language Reference(Python语言参考手册)的"Data Model"章节列出了许多特殊方法名称。需要再去查了。
当第一个操作数无法使用相应的特殊方法时,Python会在第二个操作数上调用反向运算符特殊方法。
为什么 len() 不是方法?
这是一个关于Python设计哲学的经典问题,答案根植于 “实用胜于纯粹” 的准则。
- 性能优先:对于内置类型(如
list,str,memoryview),len(x)并非调用方法。它直接从底层C结构体(PyVarObject)的ob_size字段读取长度,这比方法调用快得多。获取长度是一个极其频繁的操作,必须对基础类型高效。 - 一致性折衷:通过提供
__len__方法,Python 在保证内置类型高性能的同时,也允许用户自定义对象使用len()函数,实现了效率与一致性的完美平衡。**"一致性"指的是为所有开发者提供一个统一、直观的编程接口。**用户不需要记住不同的API,只需要调用len()即可。只要你实现了__len__方法,len()函数就会将其视为一个有长度的对象来对待。 - 概念类比:可以将
len和abs视为一元“运算符”,其函数式语法(len(obj))比面向对象的方法调用(obj.len())更自然。这一点源于Python的祖先语言ABC,其中使用#作为长度运算符(如#s)。
本章的核心思想是:通过实现特殊方法,你可以让你的自定义对象表现得像内置类型一样,从而编写出真正的 “Pythonic” 代码。 例如这我们需要为对象提供可用的字符串表示,使用__repr__用于调试,使用__str__用于用户展示。
- “python数据模型"也可以被称作"python对象模型”

















 2123
2123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









