




文章目录
- 【docker】 镜像的制作——主从数据库创建
- 快照创建镜像
- docker file
- 指令
- FROM 指定基础镜像
- MAINTAINER 添加制作者信息(LABEL用的更多)
- LABEL 添加元数据信息
- COPY
- ENV 设置环境变量
- WORKDIR 设置工作路径
- ADD 类似COPY
- RUN 启动容器的时候自动执行指定的命令
- CMD 修改启动命令
- EXPORT 声明端口,但是不会绑定端口
- ENTRYPOINT 和CMD类似,不同的是:启动容器不会覆盖自己设置的启动命令,会作为参数传给ENTRYPOINT
- ARG 区别 ENV,只能在docker file里使用
- VOLUME 创建卷
- SHELL 修改shell
- USER 切换当前用户组和用户
- HEALTHCHECK 检查容器是否健康
- ONBUILD 触发器
- STOPSIGNAL 修改传给容器的信号
- 命令
- 优秀实践
- 优化角度
- 实战
- 其余问题
【docker】 镜像的制作——主从数据库创建
编写的代码打包到镜像中发布
第三方制作内容安全性可能有问题
给镜像添加更多功能
快照创建镜像
首先启动基础容器,docekr exec进入容器后安装需要的组件和数据,然后docker commit提交快照
docker commit
参数:
-a 表示镜像作者
-c 修改启动命令
使用:
docker commit testmydocker testdocker:1.0 #
docker run -it --name test testdocker:1.0 bash
缺陷
- 黑盒:没有记录操作过程,不知道镜像添加了什么
- 不可重复:如果我们希望重新制作一便一样的镜像会很困难,没有记录操作过程
- 臃肿
docker file
与快照创建不同的是docker file安装软件的方式是使用RUN COPY RUN这种标准的语法所形成的文件,然后使用docker build完成镜像制作。
指令
FROM 指定基础镜像
用于为镜像文件指定基础镜像,如果没有,会自己pull
格式:
FROM [--platform=<platform>] <image>[:<tag>] [AS <name>]
FROM [--platform=<platform>] <image>[@<digest>] [AS <name>]
参数:
<platform>: CPU架构,如linux/amd64 linux/arm64
如果容器和宿主机的CPU架构不一样,就不能运行,可以已通过虚拟化来运行。
使用:
FROM --platform=linux/amd64 ubuntu:18.04
如果我们通过一个docker bulid文件创建不同容器:
在Dockerfile文件里:
FROM ubuntu:22.04 as build1
FROM ubuntu:22.04 as build2
在shell里:
docker build -t myweb:v0.4 --target build1 .
docker build -t myweb:v0.5 --target build2 .
MAINTAINER 添加制作者信息(LABEL用的更多)
MAINTAINER "lxx lxx@111.com"
LABEL 添加元数据信息
支持多个key value对
LABEL version="1.0" desc="create by bit"
COPY
格式:
COPY [--chown=<user>:<group>] <src>... <dest>
COPY [--chown=<user>:<group>] ["<src>",... "<desc>"]
参数:
<src>:其他容器、或者宿主机路径
<desc>:容器路径,
--chown 修改用户和组
使用:
# 复制单个文件
COPY app.py /app/app.py
# 复制多个文件
COPY file1.txt file2.txt /app/
# 复制整个目录
COPY ./src /app/src
# 带所有权的复制
COPY --chown=www-data:www-data index.html /usr/share/nginx/html/
# 使用通配符
COPY *.txt /app/
# 使用COPY完成多级构建
FROM baseimage1 as build1
RUN apt install xx
RUN xx src/demo.exe
From baseimage2
COPY --from build1 src/demo.exe dst # 第二个镜像就可以更小
ENV 设置环境变量
可以在docker file里使用${}在dockerfile里设置的环境变量
WORKDIR 设置工作路径
容器默认的工作路径是/
已进入容器,就进入了/,可以根据WORKDIR设置进入后一开始处于哪个路径
ADD 类似COPY
相比COPY,可以自动解压压缩文件,从远程下载并解压
RUN 启动容器的时候自动执行指定的命令
RUN cd /data/src && touch test.cc
RUN ["sh","-c","mkdir -p /data/src/hello && cd /data/src/hello && toush test.cc"]
CMD 修改启动命令
docker inspect + 镜像 查看CMD,就可以看到启动命令了
# 1. 使用 Exec 形式
CMD ["node", "app.js"]
# 2. 确保命令在前台运行(用于 Web 服务)
CMD ["nginx", "-g", "daemon off;"]
# 3. 使用数组格式,避免 shell 解析问题
CMD ["python", "-u", "app.py"]
如果在启动容器的时候在后面带上自己希望运行的启动命令,那么这个CMD就会被覆盖掉
EXPORT 声明端口,但是不会绑定端口
docker export 80/tcp
ENTRYPOINT 和CMD类似,不同的是:启动容器不会覆盖自己设置的启动命令,会作为参数传给ENTRYPOINT
ARG 区别 ENV,只能在docker file里使用
VOLUME 创建卷
VOLUME ["/data1"]
如果启动容器的使用使用-v创建bind卷,就会覆盖
SHELL 修改shell
多用于windows,因为power shell和cmd不一样
可以多次使用SHELL 每次使用完后会修改shell
FROM ubuntu:22.04
RUN ls -l / > /test.txt
SHELL ["/bin/bash", "-cvx"]
RUN ls -l / > /test2/txt
-cvx可以查看信息。
docker build -t shell:v0.1 --no-cache --progress=plain .
其中–no-cache禁用构建缓存.修改了 Dockerfile 中早期步骤(如基础镜像、依赖安装),避免缓存导致旧内容残留;输出模式设为 plain(详细模式)
为什么需要 --no-cache?
- Docker 会缓存构建层。如果之前构建过,后续的 RUN 可能直接使用缓存,看不到 SHELL 指令的实际效果。第2层可能被缓存,看不到 SHELL 指令改变后的行为
USER 切换当前用户组和用户
FROM ubuntu:22.04
RUN groupadd nginx
RUN useradd nginx -g nginx
USER nginx:nginx
RUN whoami > /tmp/user1.txt
USER root:root
RUN whoami > /tmp/user1.txt
RUN useradd nginx -g nginx的第一个nginx表示用户名,第二个表示组
HEALTHCHECK 检查容器是否健康
FROM nginx:1.24.0
HEALTHCHECK --interval=5s --timeout=3s \
CMD curl -fd http://localhoat/ || exit 1
ONBUILD 触发器
在一个Dockerfile文件写ONBUILD + shell 命令。FORM ubuntu:22.04。
然后docker build构建成功。然后切换一个路径创建Dockerfile文件
另一个Dockerfile文件写FROM 刚刚创建的镜像,然后docker build创建镜像,发现会自动执行触发器的命令。
STOPSIGNAL 修改传给容器的信号
如果把信号修改为9.当容器退出时,不能优雅的退出,使用docker logs可以验证结论。
命令
docker build 创建镜像
语法:
docker build [OPTIONS] PATH | URL | -
PATH 表示Dockerfile路径
URL 表示本地/远端地址。比如宿主机开启nginx服务,可以在html/编写mybuild.txt作为Dockerfile,就可以通过127.0.0.1/mybuild.txt找到Dockerfile地址
- 表示标准流
这三个选一个就行
参数:
--build-arg=[] 设置镜像创建时的ARG
-f 指定Dockerfile路径+文件名
--label=[] 设置镜像使用的元数据
--no-cache 创建镜像的过程不使用缓存
--pull 尝试更新镜像的新版本
-q 安静模式,不会打印日志,只打印id
--progress=plain 显示完整输出,适合日志记录和CI/CD
-t 镜像名字及标签
--network 默认default,可以使用--network host 让容器能上网,Docker 构建镜像时,会创建一个「临时容器」来执行 Dockerfile 中的指令(尤其是 RUN 这类可能涉及网络的操作,如 apt-get install、git clone、curl 拉取依赖等)。--network 就是为这个临时容器指定网络命名空间,决定它能访问哪些网络资源。
示例:
docker build -t build:v0.6 --build-arg NGINX_VERSION=1.23.4 .
优秀实践
善用.dockerignore
类似.gitignore,可以在构建镜像的时候忽略指定的文件
必须和 Dockerfile 放在同一级目录
oj-server/ # 构建上下文根目录(docker build . 执行目录)
├── Dockerfile # 构建镜像的配置文件
├── .dockerignore # 宿主机侧的过滤配置(关键)
├── src/ # 源码目录(需要打包)
├── logs/ # 日志目录(需要忽略)
├── build/ # 编译产物(需要忽略)
├── .git/ # git版本目录(需要忽略)
└── test.log # 测试日志(需要忽略)
文件内容:
# 忽略日志目录
logs/
# 忽略编译产物目录
build/
# 忽略git版本文件
.git/
# 忽略单个日志文件
*.log
# 注意:注释用#开头,匹配规则和.gitignore一致
利用COPY完成多级构建减少镜像内存
# 使用COPY完成多级构建
FROM baseimage1 as build1
RUN apt install xx
RUN xx src/demo.exe
From baseimage2
COPY --from build1 src/demo.exe dst # 第二个镜像就可以更小
合理使用缓存
内容不变的指令放前面,尽量复用
基础镜像使用体积小的最好
尽量合并指令来减少镜像层数
精简镜像
每个镜像用途单一、避免多功能的镜像
减少外部源的干扰
网络版本可能变化或者会更相信。所以尽量使用本地的、离线导入镜像里。可以通过COPY
减少依赖包
优化角度
导入C++程序在镜像运行
- 首先在本地编写好demo.c
- 然后创建Dockerfile文件,FROM指明依赖镜像,RUN执行配置软件源的命令
- WORKDIR制作工作目录 /src
- COPY ./demo.c .
- RUN apt install -y gcc && rm -f demo.c && apt remove -y gcc
- CMD [“/src/demo”] 启动命令就是执行程序
CMD 与 ENTRYPOINT
Shell 和 Exec 模式差异
- Shell不会直接启动,会作为sh的子程序执行。
- Exec会直接启动,pid就是1
- 因为Exec模式启动命令的pid就是1,所以收到结束信号的是自己指定的服务,可以优雅结束。
- Shell的pid为1的进程时bash,收到结束信号后直接终止,不会打印结束的日志。
- 所以无论CMD还是ENTRYPOINT,都推荐使用Exec
命令覆盖
CMD作为参数传给ENTRYPOINT,ENTRYPOINT负责指令
CMD会覆盖前面的CMD,多个CMD只会执行最后一句CMD。ENTRYPOINT也是
参数覆盖
我们执行容器时使用:
docker run -it --rm cmd:v0.1 echo hello2
CMD:只要docker run后面指明了echo,就会覆盖docker file里指定的起始命令
对于ENTRYPOINT,不会覆盖。除非使用:
docker run -it --entrypoint "/bin/sh" --rm cmd:v0.2 -c "echo hello2" # -c表示只执行这个语句,执行完退出,不进入交互模式
前文说到过,这是因为默认情况下后面的指令会作为参数喂给ENTRYPOINT,什么意思呢?
这是相关Dockerfile文件:
FROM busybox
ENTRYPOINT ["echo", "hello"]
这是Shell运行:
docker run -it --rm cmd:v01 echo hello2
打印结果
hello echo hello2
总结:
对于参数覆盖,CMD会直接覆盖,但是ENTRYPOINT使用–entrypoint才能覆盖
对于命令覆盖,两者都会。
docker ps查看容器启动命令
组合模式(官方推荐)
FROM ubuntu:22.04
RUN apt-get update -y && apt install -y iputils-ping
ENTRYPOINT ["ping","-c","3"]
CMD ["localhost"]
CMD的内容会作为参数交给ENTRYPOINT
结合参数覆盖,所以如果我们docker run后面指定参数,CMD会被命令覆盖掉,自然而然传给ENTRYPOINT的参数变化了。以此实现可变参数
多阶段构建
ps:我们可以创建一些无关文件,然后创建.dockerignore熟悉流程
Dockerfile文件:
FROM ubuntu:22.04
WORKDIR /src
COPY ./* .
RUN apt-get update && apt-get install -y gcc && gcc -o demo demo.c
RUN rm -f demo.c
CMD ["/src/demo"]
这里没有使用到多阶段构建,我们修改一下让他成为多阶段构建:
FROM ubuntu:22.04 as buildstage
WORKDIR /src
COPY ./* .
RUN apt-get update && apt-get install -y gcc && gcc -o demo demo.c
RUN rm -f demo.c
CMD ["/src/demo"]
FROM ubuntu:22.04
COPY --from=buildstage /src/demo /src/
CMD ["/src/demo"]
然后使用docker build完成镜像构建,可以发现镜像大小大大减小,这是因为后者镜像没有gcc
如果我们希望占用磁盘空间进一步减小,还可以修改FROM ubuntu:22.04为FROM busybox
我们分析一下第一阶段构建过程:
Layer 1: FROM ubuntu:22.04 as buildstage
└─ 基础镜像层(约 70-80MB)
Layer 2: WORKDIR /src
└─ 创建目录(几乎不占空间)
Layer 3: COPY ./* .
└─ 复制源文件(demo.c,几KB)
Layer 4: RUN apt-get update && apt-get install -y gcc && gcc -o demo demo.c
└─ 安装 gcc 和编译(gcc 及其依赖约 100-200MB)
Layer 5: RUN rm -f demo.c
└─ 删除源文件(注意:这不会减少镜像大小!)
注意:Layer 5 删除 demo.c 不会减少最终镜像大小,因为:
-
Docker 层是叠加的,每一层都保留变更记录
-
删除操作只是在新层标记文件为删除,底层文件仍然存在
-
这就是为什么需要多级构建
分析第二阶段:
Layer 1: FROM ubuntu:22.04
└─ 全新的基础镜像层(约 70-80MB)
Layer 2: COPY --from=buildstage /src/demo /src/
└─ 只复制编译好的可执行文件(几KB到几MB)
Layer 3: CMD ["/src/demo"]
└─ 设置命令(元数据,不占空间)
-
buildstage 阶段的所有层(包括 gcc、编译工具、源文件等)在最终镜像中完全不存在.所以此时构建的镜像空间更小
-
buildstage 是临时阶段:只用于编译,编译完成后就被丢弃
-
最终镜像从全新的基础镜像开始:不包含任何编译工具
-
只复制需要的文件:通过 COPY --from=buildstage 精确控制哪些文件进入最终镜像
合理运用缓存
dockerfile文件:
FROM ubuntu:22.04
WORKDIR /src
COPY ./* .
RUN apt-get update && apt-get install -y gcc && gcc -o demo demo.c
RUN rm -f demo.c
CMD ["/src/demo"]
如果我们使用docker build构建,然后修改demo,c
然后我们再次开始构建,查看构建日志。发现,当COPY时开始向后,都没有使用缓存。
这是因为发现COPY的内容发生了变化,所以从COPY后的内容全都要重新做,不能使用缓存。我们可以修改一下顺序,先apt-get,然后COPY:
FROM ubuntu:22.04
WORKDIR /src
RUN apt-get update && apt-get install -y gcc && gcc -o demo demo.c
COPY ./* .
RUN rm -f demo.c
CMD ["/src/demo"]
然后我们docker build构建,然后修改demo.c
然后我们再次开始构建,查看构建日志。发现,比上次我们构建快多了。
ps: --no-cache=true可以让我们构建的时候不使用缓存
实战
创建mysql主从集群
docker compose build
格式一:
services:
web:
image: nginx:v1.0
build: ./webapp
格式二:
services:
web:
image: nginx:v1.0
build:
context: ./backend
dockerfile: Dockerfile2
然后使用docker compose build就可以批量制作镜像
mysql主从同步原理
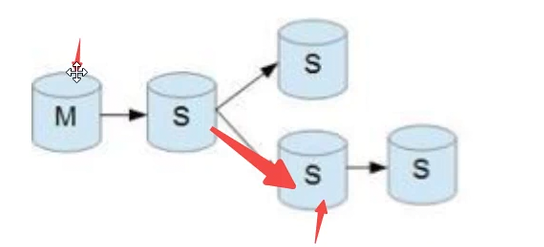
主节点主要负责写,从节点主要负责读。如果主节点挂掉,从节点没挂掉,可以完成读的操作、但是不能完成写的操作。
从节点可以完成主节点数据的备份,如果主节点数据丢失了可以恢复。
如果主节点挂掉,可以选择一个从节点作为主节点使用,这样用户就感觉不到差异了。
架构图

什么是binlog
主库每提交一次事务,都会把数据变更记录到一个二进制文件,这个二进制文件就是binlog,注意只有写操作才会记录到binlog。
Bin Log 一共有三种日志格式,可以binlog_format配置参数指定
Statement日志格式
Statement 记录原始SQL语句,会导致更新时间与原库不一致,比如update_time=now()
Row日志格式
Row 记录每行数据变化,保证数据与原库一致,缺点是数据量较大。
Minxed日志格式
Minxed :Statement和Row混合模式,默认使用Statement模式,涉及日期的使用Row模式,减少了数据量还保证了数据一致性
三种日志格式补充
除了上述提到的优缺点外,还需要考虑幂等性的存在,还要考虑[不同日志格式的影响](#### 不同日志格式的影响)(主要体现在可重放/幂等是什么,以及存在的必要性)
主从同步的方式
全同步
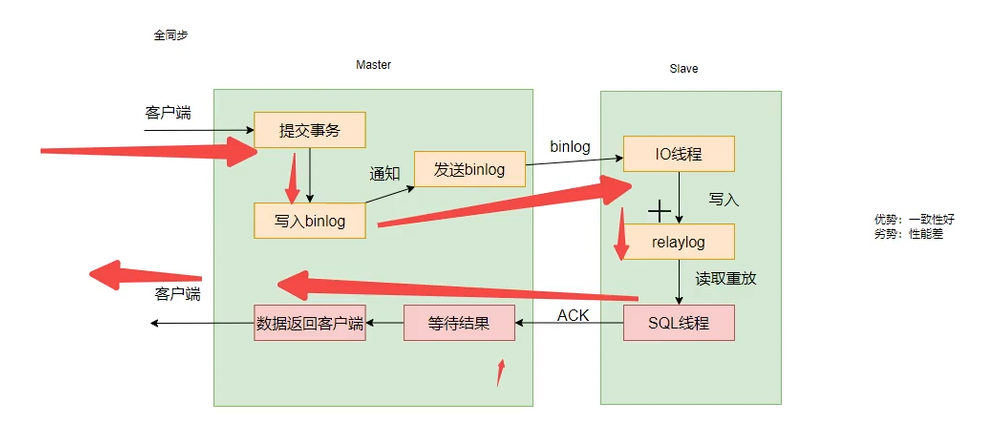
一致性好,但是性能差。主节点效率依靠从节点服务器效率。实际生产环境一般不用
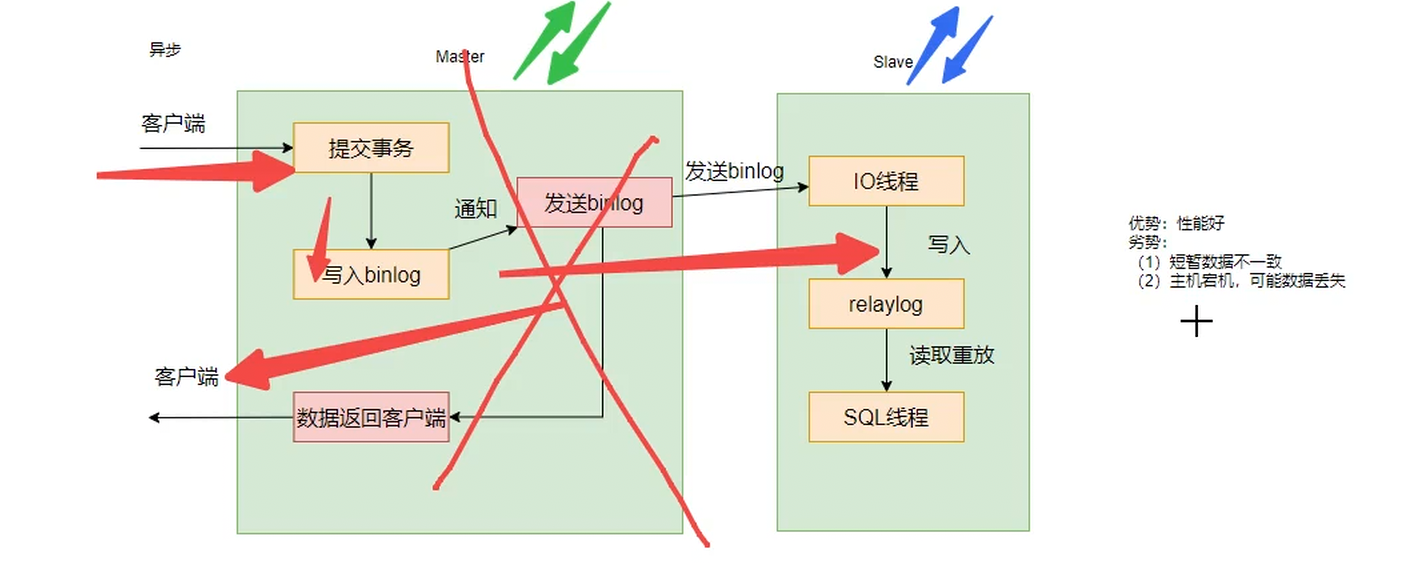
异步
半同步
Master提交事务后,写入binlog,然后一个线程负责通知Stave,一个相乘负责提交本地存储引擎和后续操作
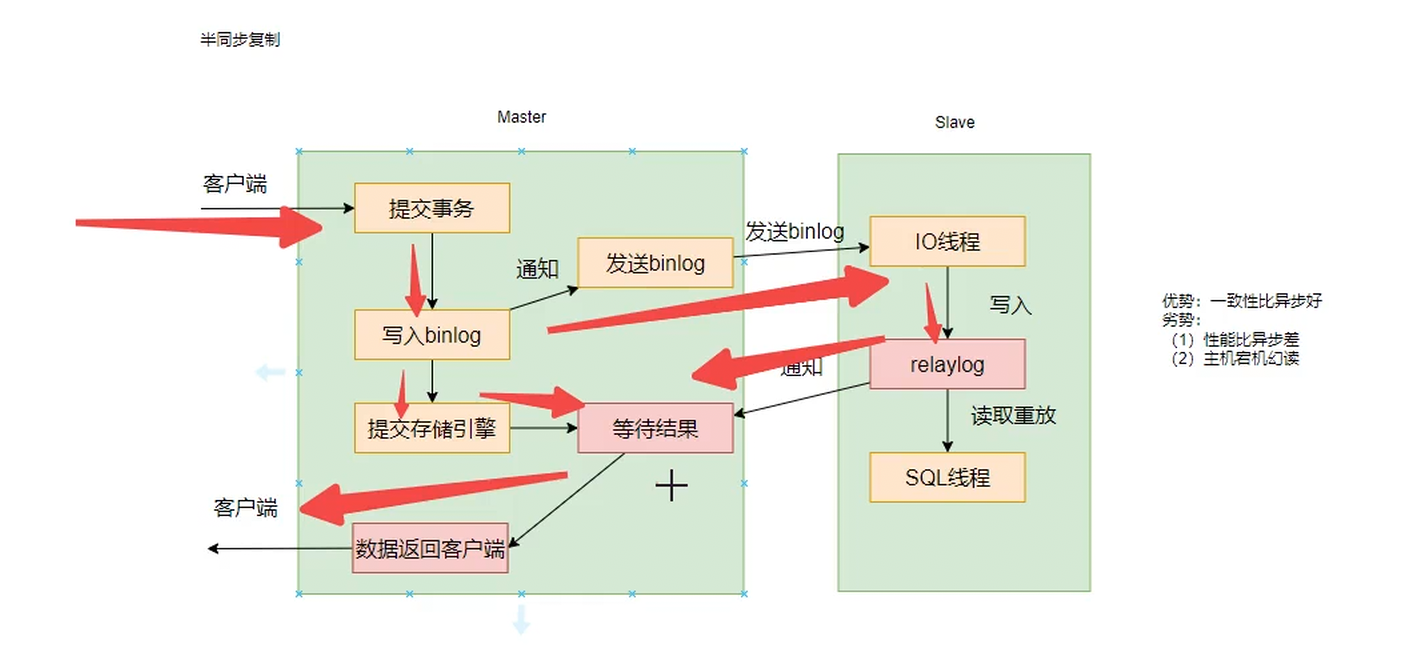
幻读现象解释:Master提交事务,然后写入binlog后,一个线程开始发送通知给客户端,另一个线程已经提交存储引擎,开始等待结果了。此时请求Master use1内容,返回一个值。又有一个客户端请求Master use1内容,但是此时Master挂掉了,Slave作为新的Master,但是这个ltave还没有接收到binlog,所以没有修改原数据。此时返回use1发现没有。导致了幻读。
增强半同步
解决了幻读的问题。但是有一致性问题(其他大厂有自己的解决防范)
数据不一致的问题:比如现在Master节点接收到数据,然后写入binlog,此时还没有发送数据,但是Master节点挂掉了,然后立即重启并且重新作为Master节点,此时发现binlog节点有内容,但是不知道要发送binlog,而是会直接写入Master的存储引擎,所以会导致Master节点数据比Slave节点数据多的情况
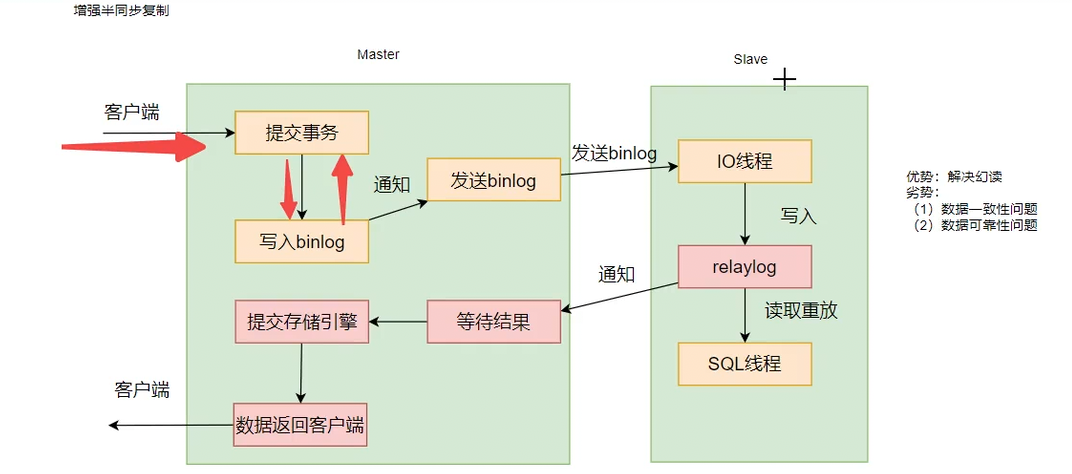
另外,如果Master和Slave同时挂掉,就会导致数据丢失。
那么如何解决这个问题,提升一致性和可靠性呢?
组复制,一致性协商协议——允许N/2+1个节点挂掉。
事务回滚与主从同步的关系(分布式角度看待数据库)
-
单库事务:BEGIN…COMMIT/ROLLBACK 只保证本库原子性。失败可回滚到起点。
-
复制(主→从):主库提交时产生 binlog 事件和 GTID,从库按顺序重放。若从库重放某事务失败,可能停止复制或跳过,无法像本地事务那样“自动回滚主库已提交的效果”;因此复制需要幂等/可重放的事件格式,避免部分执行。
-
GTID 复制的设计就是让“每个提交的事务 = 唯一 GTID = 可重放的事件”。一旦事务在主库提交,GTID 记录下来,从库必须完整成功或报错停下,不能做半回滚半成功。因此源事务必须是可回放的(要求事务表、行模式等)。GTID模式详情看:[GTID](### GTID)
-
分布式事务(跨库/跨服务,如两阶段提交、XA、Sagas):要在多个参与方间实现“要么都成功,要么补偿”。与单库回滚不同,分布式回滚要靠协调者和参与方协议(锁/日志/补偿)实现。MySQL 复制不是分布式事务协议;它只是单向重放日志,不能帮你在多个节点间自动回滚一致。
场景差异:
-
单库事务:InnoDB 表 + 本地事务,失败回滚即可。
-
主从复制:确保 binlog 可重放、幂等;若从库失败,运维介入或跳过/修复,主库已提交无法自动撤销。
-
分布式事务:跨多个节点的写操作,用 2PC/XA 保证强一致,或用 Saga/补偿确保最终一致;失败时依赖协调或补偿逻辑,而不是复制回放。
主从形式
-
一主一从
-
一主多从,从负责数据读取
-
多主一从,讲多个mysql数据库备份到一台服务器上
-
双主复制
-
级联复制,常被应用数据分析库,因为不需要实时查找数据,所以为了提高主数据库写的效率,防止因为从数据库导致主数据库等待时间边长。可以选择使用级联复制。
正式流程
核心目录结构
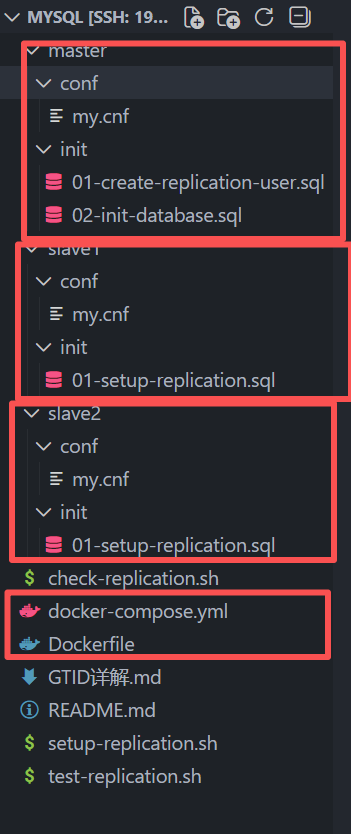
master是主库,slave是从库,conf配置了库的信息,比如innodb缓冲器大小、字符集格式、服务器标识符,还有日志前缀名等信息:
master->conf
[mysqld]
# 服务器唯一标识,不能重复
server-id = 1
# 启用二进制日志
log-bin = mysql-bin # 和框架图照应看,master会把事务内容打印到mysql-bin文件里供其他客户端读取。不开启log-bin就不能完成主从复制的任务。这个mysql-bin指明了log-bin的文件的名称,生成的日志文件会叫 mysql-bin.000001、mysql-bin.000002
binlog-format = Mixed
# GTID 模式
gtid-mode = ON # 这句话表示开启GTID模式
enforce-gtid-consistency = ON # 这句话表示强制每一个sql都是一个事务,不能使用create table ... from select... 语句,使用begin commit包装也不行
# 二进制日志过期时间(天)
expire_logs_days = 7
# 需要同步的数据库(可选,不配置则同步所有)
# binlog-do-db = testdb
# 不同步的数据库(可选)
# binlog-ignore-db = mysql
# binlog-ignore-db = information_schema
# binlog-ignore-db = performance_schema
# 字符集
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
# 其他配置
max_connections = 1000
innodb_buffer_pool_size = 1G
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2
这里有个GTID模式,GTID模式详情看:[GTID](### GTID)
slave->conf
[mysqld]
# 服务器唯一标识
server-id = 2
# 中继日志
relay-log = mysql-relay-bin
# 只读模式,只能从从库读数据,让从库拒绝普通用户的写操作(DDL/DML),但它不会阻止复制线程应用来自主库的更新:
# 防止应用或误操作直接在从库写入,保证从库数据只来源于主库复制。
# 复制不受影响:IO/SQL 线程仍然可以把主库的 binlog 应用到从库。
read-only = 1
# 字符集
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
# 其他配置
max_connections = 1000
innodb_buffer_pool_size = 512M
master->create-replication.sql
-- 创建主从复制用户
CREATE USER IF NOT EXISTS 'repl'@'%' IDENTIFIED BY 'repl123';
-- 授予复制权限
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
-- 显示主库状态(用于配置从库)
SHOW MASTER STATUS;
master->init-database.sql
-- 创建测试数据库
CREATE DATABASE IF NOT EXISTS testdb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE testdb;
-- 创建测试表
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_username (username),
INDEX idx_email (email)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- 插入测试数据
INSERT INTO users (username, email) VALUES
('admin', 'admin@example.com'),
('user1', 'user1@example.com'),
('user2', 'user2@example.com')
ON DUPLICATE KEY UPDATE username=username;
-- 创建订单表
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
order_no VARCHAR(50) NOT NULL UNIQUE,
amount DECIMAL(10, 2) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id),
INDEX idx_user_id (user_id),
INDEX idx_order_no (order_no)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
slave->setup-replication.sql
-- 配置从库连接到主库
-- 注意:这个文件会在容器启动时执行,但需要等待主库完全启动
-- 停止从库复制(如果已经在运行)
STOP SLAVE;
-- 配置主库连接信息
CHANGE MASTER TO
MASTER_HOST='mysql-master',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl123',
MASTER_AUTO_POSITION=1;
-- 启动从库复制
START SLAVE;
-- 查看从库状态
SHOW SLAVE STATUS\G
docker-compose.yml
构建完毕后,Master mysql使用show master status; Slave mysql使用show slave status;可以检查同步状态
version: '3.8'
services:
# MySQL 主库
mysql-master:
build:
context: .
dockerfile: Dockerfile
image: mysql:5.7
container_name: mysql-master
restart: always
environment:
MYSQL_ROOT_PASSWORD: root123
MYSQL_DATABASE: testdb
ports:
- "3307:3306"
volumes:
- ./master/data:/var/lib/mysql
- ./master/conf/my.cnf:/etc/mysql/conf.d/my.cnf
- ./master/init:/docker-entrypoint-initdb.d
networks:
- mysql-cluster
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "127.0.0.1", "-proot123"]
interval: 5s
timeout: 3s
retries: 10
start_period: 10s
command: --server-id=1 --log-bin=mysql-bin --binlog-format=Mixed --gtid-mode=ON --enforce-gtid-consistency=ON
# MySQL 从库 1
mysql-slave1:
build:
context: .
dockerfile: Dockerfile
image: mysql:5.7
container_name: mysql-slave1
restart: always
environment:
MYSQL_ROOT_PASSWORD: root123
ports:
- "3308:3306"
volumes:
- ./slave1/data:/var/lib/mysql
- ./slave1/conf/my.cnf:/etc/mysql/conf.d/my.cnf
- ./slave1/init:/docker-entrypoint-initdb.d
networks:
- mysql-cluster
depends_on:
mysql-master:
condition: service_healthy
command: --server-id=2 --relay-log=mysql-relay-bin --read-only=1
# MySQL 从库 2
mysql-slave2:
build:
context: .
dockerfile: Dockerfile
image: mysql:5.7
container_name: mysql-slave2
restart: always
environment:
MYSQL_ROOT_PASSWORD: root123
ports:
- "3309:3306"
volumes:
- ./slave2/data:/var/lib/mysql
- ./slave2/conf/my.cnf:/etc/mysql/conf.d/my.cnf
- ./slave2/init:/docker-entrypoint-initdb.d
networks:
- mysql-cluster
depends_on:
mysql-master:
condition: service_healthy
command: --server-id=3 --relay-log=mysql-relay-bin --read-only=1
networks:
mysql-cluster:
driver: bridge
Dockerfile
# MySQL 主从集群 Dockerfile
# 如果需要自定义 MySQL 镜像,可以使用此 Dockerfile
# 否则直接使用官方 mysql:5.7 镜像即可
FROM mysql:5.7
# 设置维护者信息
LABEL maintainer="your-email@example.com"
LABEL description="MySQL 5.7 Master-Slave Replication Cluster"
# 安装额外工具(可选)
RUN apt-get update && \
apt-get install -y vim netcat-openbsd && \
rm -rf /var/lib/apt/lists/*
# 复制自定义配置文件(如果需要)
# COPY my-custom.cnf /etc/mysql/conf.d/
# 暴露端口
EXPOSE 3306
# 使用官方 MySQL 的默认启动命令
# CMD 和 ENTRYPOINT 由官方镜像提供
其余问题
虚悬镜像
如果我们使用dockerfile创建mydocker:v1.0这个镜像,创建完毕后修改dockerfile,依然创建mydocker:v1.0镜像,但是我们之前已经有了这个镜像了。所以会把之前的镜像设置为虚悬镜像。镜像名字和版本都是,可以通过docker image ls -f dangling=true
那我们怎么批量删除呢?我们可以通过加上-q参数,让打印结果只有镜像id,然后把这些镜像id喂给docker rmi就行了
中间层镜像
-
没有 repository 和 tag
-
只有 IMAGE ID
-
用于构建缓存
-
每次 RUN、COPY、ADD 等指令都会创建一个中间层:
FROM ubuntu:20.04 RUN apt-get update # 中间层1 RUN apt-get install -y nginx # 中间层2 COPY app.py /app/ # 中间层3 RUN chmod +x /app/app.py # 中间层4
docker image ps -a 的 -a可以帮助我们看到中间层镜像
GTID
GTID = Global Transaction Identifier(全局事务标识符)
GTID 是 MySQL 5.6+ 引入的一个功能,为每个提交的事务分配一个全局唯一的标识符。
GTID = source_id:transaction_id
- source_id:服务器的 UUID(唯一标识符)
- transaction_id:事务序号(从 1 开始递增)
主库(Master)
事务执行流程:
1. 开始事务
2. 执行 SQL 语句
3. 提交事务 → 分配 GTID(例如:uuid:123)
4. 写入 binlog,包含 GTID 信息
从库(Slave)
复制流程:
1. IO 线程从主库读取 binlog
2. 发现包含 GTID 的事务
3. 检查本地是否已执行过该 GTID
4. 如果未执行 → 写入中继日志并执行
5. 如果已执行 → 跳过(避免重复执行)
GTID 模式的优势
简化主从配置
传统方式(需要指定位置)
-- 需要先查看主库状态
SHOW MASTER STATUS;
-- 结果:
-- File: mysql-bin.000001
-- Position: 154
-- 然后配置从库
CHANGE MASTER TO
MASTER_HOST='mysql-master',
MASTER_USER='repl',
MASTER_PASSWORD='repl123',
MASTER_LOG_FILE='mysql-bin.000001', -- 必须指定
MASTER_LOG_POS=154; -- 必须指定
问题:
- 需要手动查看主库的 binlog 位置
- 如果位置错误,复制会失败
- 主库 binlog 轮转后,需要重新配置
GTID 方式(自动定位)
-- 配置从库(非常简单!)
CHANGE MASTER TO
MASTER_HOST='mysql-master',
MASTER_USER='repl',
MASTER_PASSWORD='repl123',
MASTER_AUTO_POSITION=1; -- ✅ 自动定位,无需指定位置
优势:
- 不需要指定 binlog 文件名和位置
- 自动找到正确的复制起点
- 即使主库 binlog 轮转,也能自动处理
自动故障转移
场景:主库故障,切换到新主库
传统方式:
-- 需要找到每个从库的复制位置
-- 非常复杂,容易出错
GTID 方式:
-- 从库自动知道已经执行了哪些事务
-- 只需要指向新主库,自动继续复制
CHANGE MASTER TO
MASTER_HOST='new-master',
MASTER_AUTO_POSITION=1;
START SLAVE;
防止重复执行
场景:从库重启后重新连接主库
传统方式:
- 可能重复执行某些事务
- 需要手动检查位置
GTID 方式:
- 自动检查 GTID 是否已执行
- 已执行的事务自动跳过
- 保证幂等性
支持多源复制
一个从库可以从多个主库复制数据
每个主库的 GTID 不同(UUID 不同)
从库可以区分事务来自哪个主库
GTID 的限制和注意事项
必须启用 enforce-gtid-consistency
-- 必须同时启用
gtid-mode=ON
enforce-gtid-consistency=ON
原因:某些操作与 GTID 不兼容,需要禁止。
禁止的操作
-- ❌ 禁止:CREATE TABLE ... SELECT
CREATE TABLE t2 SELECT * FROM t1;
-- 需要改为两步:
CREATE TABLE t2 LIKE t1;
INSERT INTO t2 SELECT * FROM t1;
-- ❌ 禁止:在事务中使用临时表,临时表生命周期仅绑定当前会话,在从库重放同一事务时,并不存在相同的临时表上下文,语句不可被可靠重放。
BEGIN;
CREATE TEMPORARY TABLE temp1 (...);
INSERT INTO temp1 VALUES (...);
COMMIT; -- 错误!
-- ❌ 禁止:某些存储过程操作
最佳实践
同时启用一致性检查
gtid-mode=ON
enforce-gtid-consistency=ON
使用自动定位
MASTER_AUTO_POSITION=1
定期检查 GTID 状态
SHOW SLAVE STATUS\G
备份时包含 GTID 信息
- 恢复后,从库可据此判断哪些事务已执行、哪些未执行,从而用 MASTER_AUTO_POSITION=1 自动对位,不需要手工指定 binlog 文件/位置。
mysqldump --master-data=2 --set-gtid-purged=ON
- GTID 是在成功写入 binlog 时分配的;如果事务回滚,就没有 GTID。
- 若事务中包含 GTID 不支持的操作(例如对 MyISAM/MEMORY 写、或混用事务/非事务表),在 enforce_gtid_consistency=ON 时会被拒绝,事务根本不会进入 binlog,因此也不会生成 GTID。
可重放/幂等是什么,以及存在的必要性
可重放/幂等是说从库重做主库已提交的事件时,不会出现“部分执行”“重复执行导致脏数据”。具体:
-
可重放:从库拿到 binlog 事件,按原顺序执行就能得到与主库相同的结果;事件本身不依赖主库上下文的不可重现状态(如非确定性函数在语句模式下可能不一致)。
-
幂等:同一个事件即使被执行多次,结果保持一致,不会因为重复重放而把数据改坏(如行模式写某行到固定值是幂等的,而“自增 +1”在重复执行就不是)。
- 幂等例子(重复执行结果不变):行模式的行事件把某行的字段设置为具体值,比如 UPDATE user SET age=30 WHERE id=1,或在行模式里写入一条变更记录,包含新行的最终值。即使这条事件被执行多次,最终 age 都是 30,不会继续变。
- 非幂等例子(重复执行会累加/改变):UPDATE user SET age = age + 1 WHERE id=1。第一次执行 age 从 29 到 30;如果因重试又执行一次,就变成 31,结果偏离主库。
可能混淆的点。存在的必要性:
- 复制重放不是“本地单机事务”,在从库 SQL 线程中,同步过来的事务会按顺序执行。某个事务里的语句/行事件如果中途报错,已执行的部分不会自动被回滚(尤其是涉及非事务表或语句格式下的半成功),复制线程只会停在出错位置。结果:主库已提交的效果在从库上变成“半条命”。
- 如果同一事务的事件因重试被重复执行,非幂等的写(如 age=age+1)会让数据越跑越偏,无法靠回滚补救,因为主库那边已经提交,复制只能重放或跳过。
- 也就是说,“部分执行”指从库因错误或非事务引擎导致事务无法整体原子落地;“重复执行导致脏数据”指重复重放非幂等事件会把数据改坏。复制线程不会自动替你恢复一致性,只会停/跳,后果需要人工处理。
MYSQL的保障
- 运行 GTID + enforce_gtid_consistency=ON 时,会拒绝某些明显不安全的操作(非事务表写入、混合事务/非事务写、CREATE TEMPORARY TABLE … SELECT 等),防止无法重放的一致性问题。
不同日志格式的影响
- 二进制日志格式 ROW 天生更幂等:记录的是行的最终值(或旧值+新值),重复执行不会累加效果。STATEMENT 或 MIXED 可能因非确定性函数、受影响行数不同而出现不幂等风险。

















 1351
1351



 到【灌水乐园】发言
到【灌水乐园】发言








