




文章目录
C++入门
namespace
-
namespace可以定义命名空间域,本质是定义一个域,而不同域之间可以定义同名变量(即域隔离),所以不同的namespace可以定义同名变量。
-
例如,自己定义
namaspace lpx{class string{};}。在使用string时候,可以用作用域解析运算符表明自己使用的是哪个域的stringstd::string str1; lpx::string str2; -
可以使用
using namespace+ 命名空间名,来解除命名空间的域隔离。 -
可以使用
using+ 命名空间名 +::+ 函数或类,来部分展开命名空间的部分内容。要求保证展开后不会造成冲突,再展开,防止重定义问题。#include <iostream> #include <vector> using std::vector; // 对命名空间进行部分展开,以后使用vector,默认是std命名空间内的vector namespace lpx { void func() { printf("hello\n"); } } using lpx::func; // 对命名空间进行部分展开 //using vector<int>::push_back; //错误,需要实例化对象 class Date { public: Date(int year, int month, int day) :_year(year) ,_month(month) ,_day(day) {} void func1() { printf("void func1()\n"); } static void func2() { printf("void func2()\n"); } ~Date(){} private: int _year, _month, _day; }; // using Date::func1; // 不允许使用类限定名 // using Date::func2; // 不允许使用类限定名
-
-
namespace的使用:namespace只能定义在全局,namespace可以嵌套使用,可以在不同文件使用同一个命名空间,之后会自动合并相同命名的命名空间代码块- 项目中,多个同名
namespace不会冲突,会视为一个namespace
-
域和代码块的区别:
- **域(Scope)**是变量或函数等名称的可见范围,它决定了哪些地方可以访问这些名称。
- **代码块(Block)**是一个用大括号
{}包围的代码区域,定义了一个局部作用域,变量在代码块内有效。
缺省参数
-
缺省参数是声明或定义函数时,为函数的参数指定一个缺省值,如果对应实参没有使用,就会自动使用设定的缺省值。
-
缺省参数分为全缺省参数和半缺省参数。
- 要注意的是,半缺省参数只能从右向左给缺省值。
-
在调用带缺省值的函数时,必须从左向右一次给实参,不能跳跃给实参。
-
函数声明和定义分离时,规定必须给函数声明缺省值。
-
代码:
void func1(int a = 0) // 全缺省参数 { cout << a << '\n'; } void func2(int a, int b = 2, int c = 3) // 半缺省参数 {}
函数重载
-
要求同名函数的形参不同,可以是参数类型不同,也可以是参数个数不同。
-
在调用有重载函数的时候,优先调用最符合传参类型的函数。
-
函数重载本身是一种静态多态。
-
易错代码:
void f1() { cout << "void f1()" << endl; } void f1(int a = 10) { cout << "void f1(int a = 10)" << endl; }如此,这两个函数也会构成函数重载。在使用f1(5)时,会调用下边这个函数,不会出现问题。但是,在使用f1()时,会区分不了调用哪个函数,会报错
引用
-
引用不是新定义一个变量,是给已存在的变量取了一个别名。编译器不会给引用变量开辟空间,它和他引用的变量公用一块内存空间。实际上,汇编层面就是用指针实现的。
-
引用分为左值引用和右值引用。右值引用是c++11新特性,会在后文介绍。
-
代码:
int a = 0; int &b = a; // 类型 &引用别名 = 引用对象 int &c = a; //一个变量a,可以有多个别名 int &d = b; ++d; // 对d++,实际上abcd都会进行++操作,因为这四个变量对应都是一块内存空间,对四个变量取地址,会发现地址是一样的; cout << a << b << c << d << '\n'; cout << &a << endl; cout << &b << endl; -
引用的使用:
void swap(int &x, int &y); // 此时,传的是引用,因为对应的是一块地址空间,所以可以在swap修改实参 // 返回值用引用 //string &addStr(string& s1, string& s2)// 这里return的是右值,函数类型不能是左值引用 const string &addStr(string& s1, string& s2) { return s1 + s2; } // 为了向外界return,构建临时变量,临时变量类型就是函数指明的类型const string&,函数栈帧销毁后,右值s1 + s2被销毁,那么临时变量也会被析构,打印返回值就是空的 // 虽然语法上不报错,但是这个右值会被析构 const string &addStr(string& s1) { return s1; } // 看这个函数,是能够正常使用的,打印返回值也没有问题。 // 在return时候,构建const string&类型的临时变量,临时变量是s1的别名。同时,s1是实参的别名,那么临时变量就是实参的别名。函数内部没有创建空间,函数栈帧销毁,自然不会对s1进行析构,就能正常返回值。cout返回值也能正常打印 -
const 引用
-
权限问题
const int a = 1; // int &b = a; // 权限放大error,不能用非const变量引用const变量,防止造成因为修改b而修改a的问题 int a = 1; const int &b = a; // 权限缩小,可以 int a = 1; int &b = a; // 权限平移,可以 const int a = 1; const int &b = a; // 权限平移,可以 int a = 10; // int &b = a * 3; // 权限放大error,因为a * 3会建立一个临时变量,临时变量的属性都是const,但是b没有const属性,所以涉及权限放大 const int &b = a * 3; double d = 2.2; const int &e = d; // 权限平移,类型不同,d在进行类型转换的时候会有一个中间变量,所以e应该也是const,权限平移
-
-
指针和引用的关系
1.内存:引用不开空间,指针开空间
2.语法:汇编中都是指针实现
3.初始化:引用必须初始化,指针建议初始化
4.对象:引用不能更改引用对象,指针可以改变指向对象
5.访问:引用可以直接访问指向对象,指针需要解引用
6.sizeof:引用结果为引用类型大小,指针则是4/8,地址空间所占字节
7.安全性:引用更安全,指针可能有野指针、空指针
nullptr
C NULL ((void*) 0)
CPP NULL 0
inline
- 宏函数预处理替换,不用建立栈帧,更快
- inline修饰的函数叫内联函数,C++会在调用的地方展开内联函数
- inline内联多用于短小函数,不适用递归、多行
- inline只是对编译器的建议
- debug默认不展开inline
- inline函数不建议声明和定义分离到两个文件
类和对象
-
class和struct都可以定义类,都要在}后加;
-
类中内容称为类的成员,类中变量叫类的属性或成员变量,类的函数叫类的方法或成员函数
-
定义在类的成员函数默认为inline
-
类访问限定符
private成员只能被类的成员函数访问,不能在类外部访问,也不能被派生类访问。protected成员只能被类的成员函数和派生类的成员函数访问,不能在类外部直接访问。public成员可以在类外直接使用,可以被派生类继承- 访问权限作用域从该访问限定符出现到下一个访问限定符出现为止,或}结束
class默认private,struct默认public
-
与C语言不同,在类名前不用加struct
struct ListNodeCPP { void Init(){}; ListNodeCPP *next; // 不用写成struct ListNodeCPP } -
对象大小
成员函数指针不需要存储,调用函数时被编译成汇编指令
call地址。编译器在编译链接时就找到函数地址,不是在运行时找,只用动态多态时在运行时找,就要存储函数地址。其余对象符合==内存对齐原则== -
this指针-
类的非
static成员函数,都有一个隐藏的传参。这个参数就是this指针,指向此类。void Init(Data* const this, int year, int month, int day); -
this指针存在栈上,vs则是通过ecx寄存器来存储this指针。 -
类的成员都是通过
this指针访问的,如给_year = 10;赋值,本质是this->_year = 10; -
C++规定不能再函数实参和形参位置显示写
this指针(编译时,编译器会自己处理),但可在函数内部显示使用this指针 -
易错代码分析:
class A { public: void Print() { cout << "A::Print()" << '\n'; } private: int _a; } class B { public: void Print() { cout << "B::Print()" << '\n'; cout << _b << '\n'; } private: int _b; } int main() { A* pa = nullptr; B* pb = nullptr; pa->Print(); // 可以正常打印 // pb->Print(); //会引起报错 return 0; }- 分析实验现象,pa是空指针,但是对空指针->调用函数没有报错,这是因为函数没有存储在类内,调用函数本质是call函数地址完成的,不需要对空指针解引用访问。pb是空指针,对pb->调用函数报错,这是因为pb的方法中,要访问pb->_b。这一行为需要对空指针解引用,导致段错误。
-
类的默认成员函数
初始化与清理:构造函数、析构函数。
拷贝赋值:赋值重载,拷贝构造。
取地址重载:对普通对象和const对象取地址。
构造函数
完成对类的初始化等一系列操作。
-
函数名和类名一致
-
无返回值
-
对象实例化时,系统会自动调用对应参数列表的构造函数
-
可以进行函数重载
-
不写时,编译器会自动生成构造函数
-
自动生成的构造函数不会对内置类型有初始化要求,对于自定义类型会自动调用对应的构造函数
即,内置类型还是随机值。
-
内置类型:char,int,指针等c语言基础类型。
-
自定义类型:class,struct,union…
-
-
默认构造函数:无参构造函数、全缺省构造函数、不写构造时编译器默认生成的构造函数。也就是:不传实参就可调用的函数。
-
默认构造函数不是编译器默认生成的函数!!!
-
默认构造函数有且只有一个存在。
析构函数
完成对类的销毁等一系列操作。destory
- 函数名是
~+类名 - 无参数无返回值
- 未显示定义时,系统默认生成
- 需要注意的是:在一个类既有自定义类型,又有内置类型的情况下,如果我在此类的析构函数中,未显示调用自定义类型的析构函数,编译器仍然会自动调用自定义类型的析构函数
- 对象生命周期结束时,系统自动调用
- 编译器对内置类型不做处理,自定义类型成员会自动调用对应的析构函数
拷贝构造函数
已有一个类的实例化对象,根据此对象重新构造一个的新的对象
-
拷贝构造函数本质是构造函数的一个重载
-
拷贝构造函数第一个参数必须是类类型对象的引用,后面的参数一定要有缺省值,否则只是构造函数
若传值,每次调用拷贝构造函数前都要进行传值传参,而传值传参本身就是一种拷贝构造,就会形成无限递归。
-
C++规定自定义对象进行拷贝行为必须调用拷贝构造,对类值类型,有相应的拷贝构造函数
-
一个类内既有自定义类型,又有内置类型的情况下。如果我只完成对自定义类型的拷贝操作,那么内置类型可以顺利完成拷贝吗?反之呢?
都不可以.
需要注意的是:在初始化列表中可以调用成员的构造函数对其进行构造,在构造函数中不行
代码:
class Date { public: Date(int year, int month, int day, string str) :_year(year) , _month(month) , _day(day) , _data(str) { _data = str; } /* Date(const Date& d) { _data(d.GetStr()); cout << "Date(Date& d)" << '\n'; } */ Date(const Date& d):_data(d.GetStr()) // 正确用法 { cout << "Date(Date& d)" << '\n'; } const string& GetStr() const { return _data; } void Print() { printf("%d-%2d-%d_", _year, _month, _day); cout << _data << '\n'; } ~Date() {} private: int _year, _month, _day; string _data; };实验代码:
class Date { public: Date(int year, int month, int day, string str) :_year(year) ,_month(month) ,_day(day) ,_data(str) { _data = str; } Date(Date& d) { cout << "Date(Date& d)" << '\n'; } void Print() { printf("%d-%2d-%d_", _year, _month, _day); cout << _data << '\n'; } ~Date(){} private: int _year, _month, _day; string _data; }; int main() { Date d1(2025, 5, 20, "很热的一天"); d1.Print(); Date d2(d1); d2.Print(); return 0; }实验结果:
-

-
C++规定自定义对象进行拷贝行为必须调用拷贝构造。为什么呢?如果只使用默认生成的拷贝构造函数会怎样?
默认生成的拷贝构造函数对内置类型是按字节进行拷贝。即,浅拷贝、值拷贝。对自定义类型,调用相应的拷贝构造函数。
对于指针类型,在默认生成的拷贝构造函数中,会设置一个相同类型的指针,有着相同地址,指向相同位置。若此指针指向的空间是开辟在堆上,那么在进行析构的时候,就会进行两次,产生段错误。
-
引用返回可以减少拷贝,但要确保返沪对象在函数结束后还在。
Stack st1; Stack st3(st1); //这里是赋值拷贝 Stack st2 = st3; // 这里也是赋值拷贝
赋值运算符重载
用于两个已存在的对象,与拷贝构造相区分
-
默认赋值运算符重载与默认拷贝构造函数类似,都是浅拷贝
-
有返回值,为支持连续赋值场景,可写成类型引用作为返回值
Date& operator=(const Date &d) { if(this != &d) { _year = d._year; _month = d._month; _day = d._day; } return *this; }
运算符重载
-
返回类型 +
operator+ 运算符 -
bool ret = d1 == d2;本质是bool ret = operator==(d1, d2); -
在C++中,以下运算符不支持重载:
-
.(成员访问运算符):用于访问对象的成员,不能重载。 -
::\*(成员指针运算符):与成员访问运算符一起使用,用于指向成员函数或数据成员,不能重载。 -
::(作用域解析运算符):用于指定命名空间或类的作用域,不能重载。 -
sizeof:用于返回类型或对象的大小,不能重载。 -
typeid:用于获取对象的类型信息,不能重载。 -
alignof:用于返回类型对齐要求,不能重载。 -
noexcept:用于指定一个函数是否抛出异常,不能重载。 -
new和delete(运算符):虽然可以重载new和delete运算符(用于自定义内存分配),但new[]和delete[]等变种运算符不能直接重载。 -
?: 三目运算符 -
.*:typedef void(A::*PF1)();PF1 pf1 = &A::func1; A obj; (obj.*pf1)();
-
-
参数个数和该运算符作用的运算对象一样多。
-
因为有this指针,传参数少一个
-
运算符优先级不变
-
Date operator++();前置++Date operator++(int);后置++
构造顺序是按语句的顺序进行构造,析构按照构造相反的顺序析构,static改变对象生存作用域,在局部对象析构后析构,静态和全局的看定义的先后顺序 先定义的后析构。
// 全局变量
class Global
{
public:
Global() { cout << "Global constructor" << endl; }
~Global() { cout << "Global destructor" << endl; }
};
Global global_var; // 全局变量
void test()
{
// 局部变量
class Local
{
public:
Local() { cout << "Local constructor" << endl; }
~Local() { cout << "Local destructor" << endl; }
};
Local local_var; // 局部变量
// 静态变量
class Static
{
public:
Static() { cout << "Static constructor" << endl; }
~Static() { cout << "Static destructor" << endl; }
};
{
static Static static_var; // 静态变量
}
static Static static_var2; // 静态变量
}
int main() {
cout << "In main function" << endl;
test(); // 调用函数,测试局部、静态和全局变量的析构顺序
return 0;
}
初始化列表
-
无论初始化列表是否有对应成员的初始化,都会走初始化列表先初始化一遍,所有尽量在初始化列表提供初始化,来提高效率
-
引用成员变量,const成员变量,没有默认构造的类类型变量,必须在初始化列表进行初始化,否则编译报错。
-
需要注意的是,初始化列表是c++11新特性
-
初始化列表初始化顺序按声明顺序初始化
-
整个类的成员初始化顺序
-
如果没有初始化列表,先走缺省值,然后进入函数体。如果有初始化列表,不走缺省值,直接进入初始化列表进行初始化,然后进入函数体。若此时仍然没有初始化,自定义类型调用默认的构造函数,内置类型看编译器。引用成员变量,const成员变量,没有默认构造的类类型变量则会报错。
-
实验代码:
class A { public: A(int a1 = 3, int a2 = 4) :_a1(a1) ,_a2(a2) { _a1 = 5; _a2 = 6; } int _a1 = 1; int _a2 = 2; }; int main() { A a; return 0; }
-
explicit
explicit修饰构造函数,就不再支持隐式类型转换
static
-
初始化列表和缺省值是对类内成员初始化,static之后,对象不是成为域内对象,并不会走初始化列表和缺省值。static成员变量应在类内声明,类外定义。
class A{ static size_t _t; }; // 这是声明 size_t A:_t = 1; // 这是定义 -
静态成员没有this指针,所以static修饰的函数,不能访问类内成员和方法,但能访问static的成员和方法。
-
在类A中定义static func();方法,类A中其他方法可以直接使用func()方法。反之亦可。
-
inline static和const static在类内声明,该如何处理?
-
静态方法和非静态方法在使用的时候有什么区别?
例如,类A有
static void a();和非静态方法void b();调用
a(),可以A::a();直接调用,也可以先实例化,A m; m.a();调用;调用
b(),不能A::b();直接调用,需要先实例化,A m; m.b();调用;要注意的是,
using + 类名 + 方法都是非法的。
内部类
- 内部类是外部类的友元
编译器的优化
-
构造+拷贝=直接构造
A aa1 = 1; A aa2(2);对于aa1,本应是整形类型1构造出A类的临时变量,然后拷贝构造构造出aa1。但是编译器会直接优化两步,成为直接构造 -
编译器对于函数返回值的优化

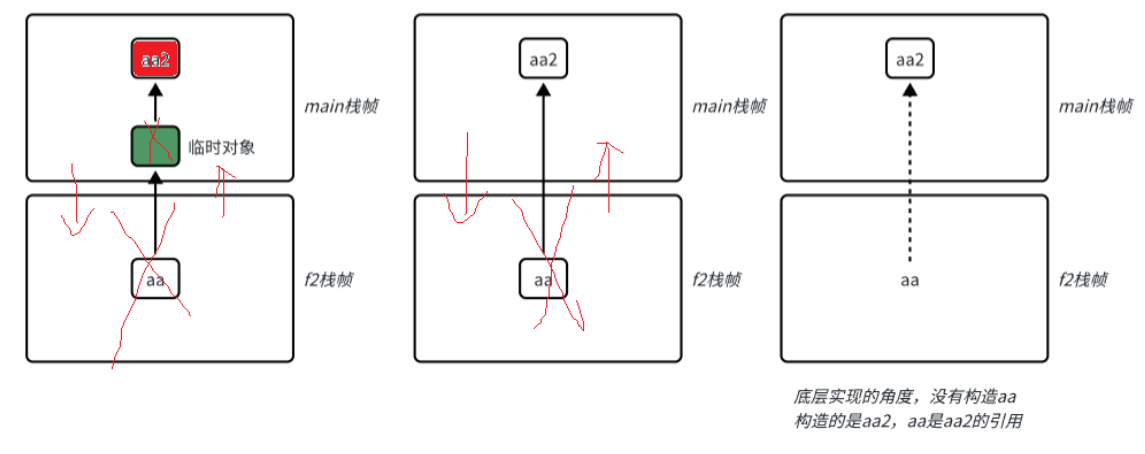
内存管理
-
存储位置
int globalvar = 1; // 数据段(静态区) static int staticGlobalvar = 1; // 数据段(静态区) void Test() { static int staticvar = 1; // 数据段(静态区) int localvar = 1; // 栈 int num1[10] = { 1, 2, 3, 4}; // num1栈 *num1栈 char char2[] = "abcd"; // char2栈 *char2栈 char *str = "abcd"; // str栈 *str代码段(常量区) int *ptr1 = (int*)malloc(sizeof(int) * 4); // *ptr1堆 ptr1栈 int *ptr2 = (int*)calloc(4, sizeof(int)); // *ptr2堆 ptr2栈 int *ptr3 = (int*)realloc(ptr2, sizeof(int) * 4); // *ptr3堆 ptr3栈 free(ptr1); free(ptr3); } -
new与deletenew先在堆开空间,然后调用构造函数,delete先调用析构函数,再free空间
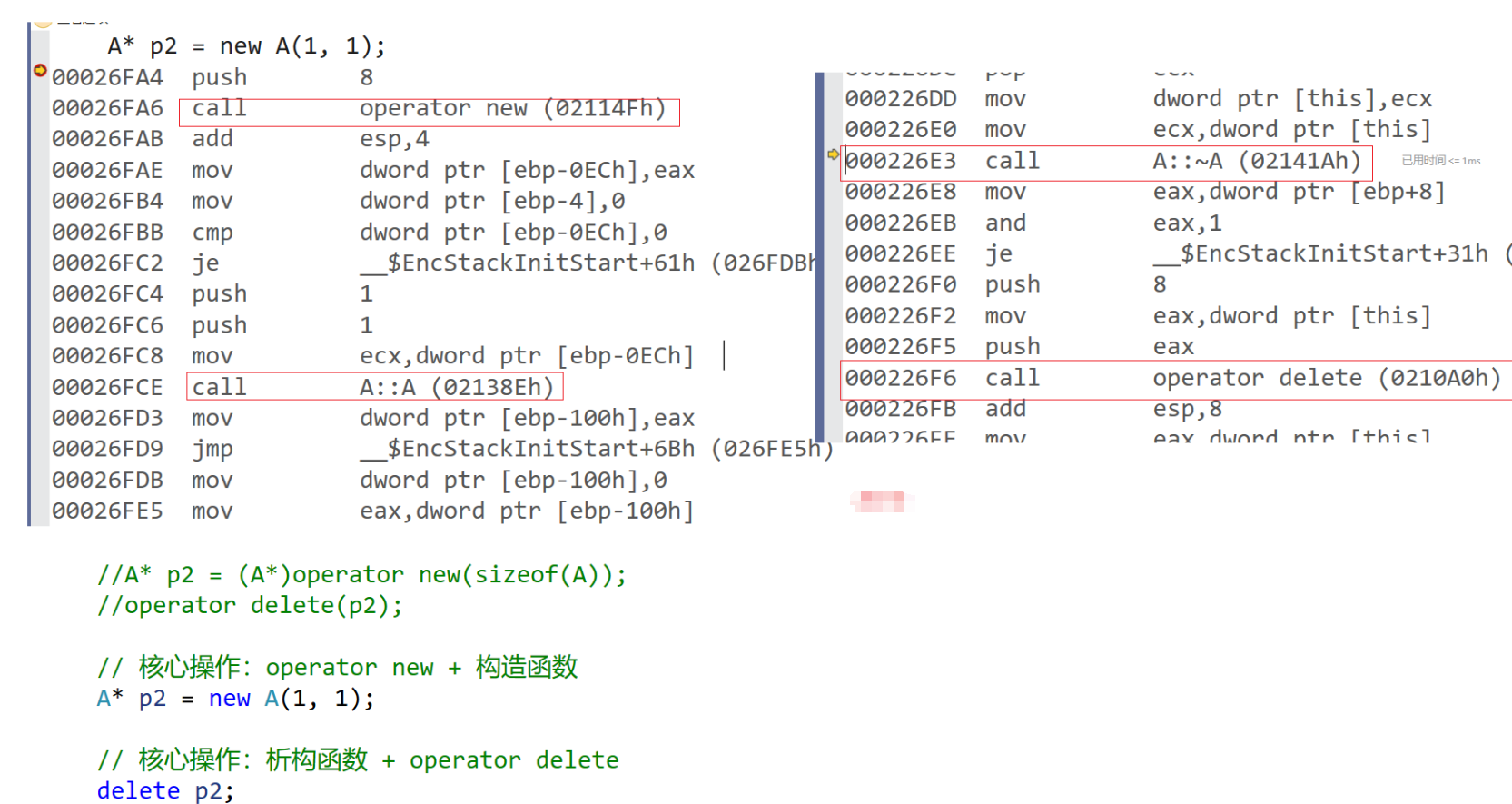
-
new和delete对于自定义类型时,一个调用构造函数,另一个调用析构函数。A *p = new A[3]{ a1, a2, a3 }; // 会构造临时变量 int *ptr1 = new int; int *ptr2 = new int[10]; int *ptr3 = new int(10); int *ptr4 = new int[10]{ 1, 2, 3 }; // 未完全初始化会补0 delete[] ptr4; // []相对应 delete ptr1; -
delete[]和delete的区别对于多对象释放空间,要用delete[]。单对象可以用delete
int *p6 = new int[10]; 内置类型只有40byte,在p6的地址前,会开辟4byte存储p6的信息——开辟了多少个对象(此时存10),调用delete[]时,[]会让析构起始位置向前移动4byte来析构存储信息的空间。
(对于自定义类型,结果也不同,debug和release结果也不同,不同编译器也不同,了解原理即可)
有些编译器会优化,delete对多对象使用也不会错误。
-
new和operator new,delete和operator delete的区别// operator new 和 operator delete 的使用 A *p1 = (A*)operator new(sizeof(A)); // 开辟空间 new(p1)A(10); // 初始化,调用构造函数 pi->~A(); // 调用析构 operator delete(p1); // 释放资源 -
operator new封装malloc operator;delete封装_free_dgb。operator new失败抛异常(更符合c++对异常处理的性质),malloc失败返回nullptr。new本身是调用operator new开空间,然后调用构造函数。 -
operator的工程用处-
捕获异常
-
operator向内存池高频申请和释放内存,内存池是类似于一个缓冲区。系统向堆中开辟一段空间给内存池,operator会对内存池进行操作,而不是对堆进行操作。如此,就可以提高效率
-
-
new和malloc,delete和free的区别-
malloc和free是函数,new和delete是操作符
-
malloc申请空间不会初始化,new可以初始化
-
malloc从申请空间要计算申请空间大小并传参,new直接跟上空间的类型和指定对象个数即可
-
malloc返回值是void*,使用时必须强转,new不用
-
malloc申请空间失败返回NULL,new则是抛异常
-
delete在释放空间前会调用析构函数
-
e `的区别
```c++
// operator new 和 operator delete 的使用
A *p1 = (A*)operator new(sizeof(A)); // 开辟空间
new(p1)A(10); // 初始化,调用构造函数
pi->~A(); // 调用析构
operator delete(p1); // 释放资源
```
-
operator new封装malloc operator;delete封装_free_dgb。operator new失败抛异常(更符合c++对异常处理的性质),malloc失败返回nullptr。new本身是调用operator new开空间,然后调用构造函数。 -
operator的工程用处-
捕获异常
-
operator向内存池高频申请和释放内存,内存池是类似于一个缓冲区。系统向堆中开辟一段空间给内存池,operator会对内存池进行操作,而不是对堆进行操作。如此,就可以提高效率
-
-
new和malloc,delete和free的区别-
malloc和free是函数,new和delete是操作符
-
malloc申请空间不会初始化,new可以初始化
-
malloc从申请空间要计算申请空间大小并传参,new直接跟上空间的类型和指定对象个数即可
-
malloc返回值是void*,使用时必须强转,new不用
-
malloc申请空间失败返回NULL,new则是抛异常
-
delete在释放空间前会调用析构函数
-

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









