




前言:
目标检测是计算机视觉一个重要的领域。物体检测(object detection)是计算机视觉中一个重要的分支,其大致功能是识别一组预定义的对象类,比如说人、汽车、自行车、动物。
并使用边界框(矩形框/bounding box)描述图像中每个检测到的图像位置。
通常我们会使用最小边界框(矩形框/bounding box)框出目标物体位置,并进行分类。
但是通常对象的形状往往是不规则的,所以另一种代替的方法是图像分割技术,图像分割技术一般会精确到像素级。(后话)
为了有效地给图片贴上标签,下面的文章介绍了一些策略,以确保你的数据集尽可能是高质量的。
虽然下面的最佳实践通常是正确的,但重要的是要注意,标签说明高度依赖于手头任务的性质。
此外,为一项任务标记的图像。可能不适合另一项任务——为了防止重新标记,我们应该考虑到这一点,下面让我们演练一些技巧。
不确定首先要标记哪些图像? 考虑如何在计算机视觉中使用主动学习。
最好把数据集及其标签看作是有生命的东西:不断地改变和改进,以适应手头的任务。
1. 在每张图片上标记每一个感兴趣的物体
计算机视觉模型的建立是为了,了解像素的哪些图案,对应一个感兴趣的对象。
正因为如此,如果我们训练一个模型,来识别一个对象,我们需要在我们的图像中,标记该对象的每一个外观。
如果我们在一些图像中,不给对象贴上标签,我们将会给我们的模型,引入错误的数据。
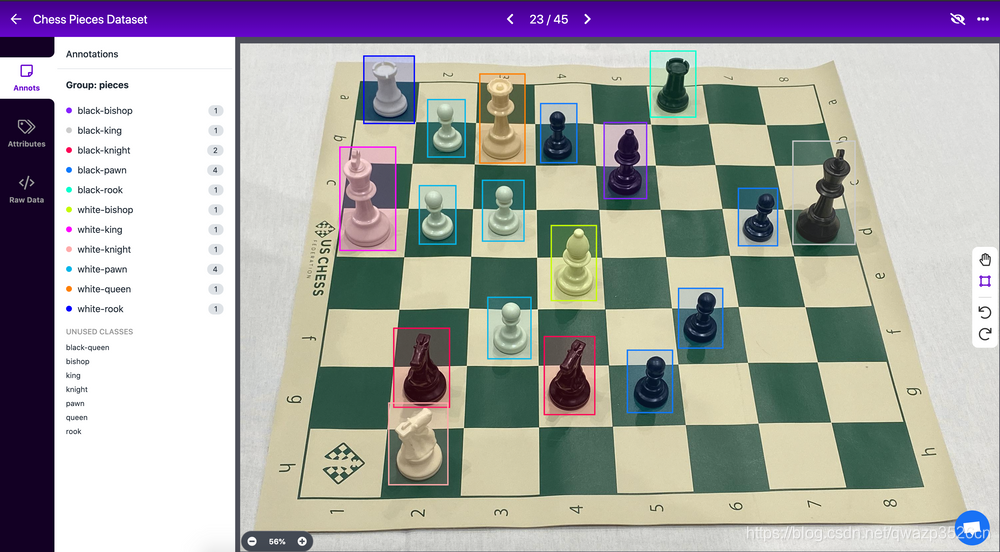
例如,在国际象棋棋子数据集中,我们需要标记棋盘上每个棋子的外观,我们不仅仅会标注其中的一部分,我们会给标记的对象添加一个名字比如说是白色的棋子。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











