






论文名:Scalable Diffusion Models with Transformers
DiT的核心思想:Diffusion Transformer的核心思想是使用Transformer作为扩散模型的骨干网络,而不是传统的卷积神经网络(如U-Net),以处理图像的潜在表示。
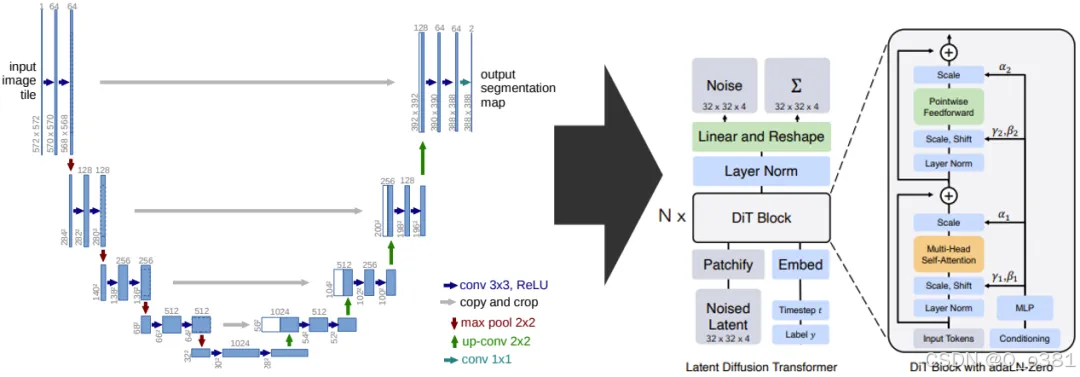
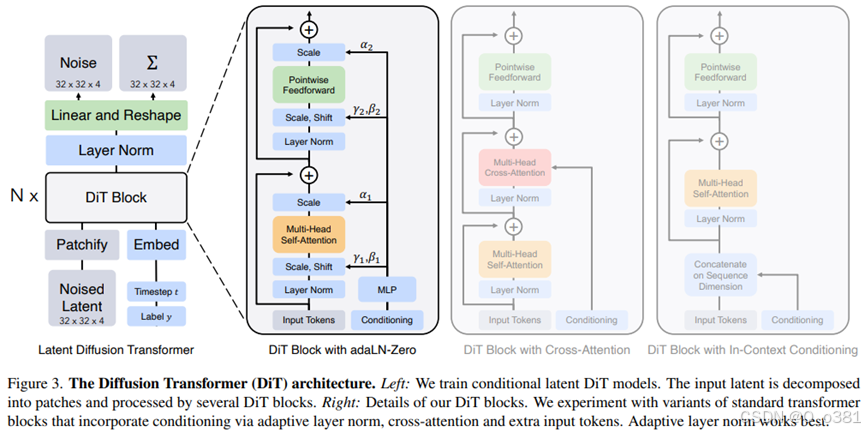
对标准 Transformer 块的变体进行了试验,这些变体通过自适应层归一化、交叉注意力和额外输入标记来纳入调节机制。自适应层归一化效果最佳也就是adaLN-Zero
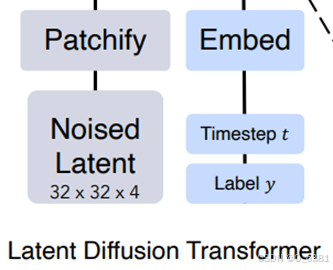
Noised Latent:表示扩散模型中的潜空间输入,它是经过加噪后的潜变量(也就是原始数据加噪)
Patchify(分块):将输入潜变量分割为小块(patches),每个小块可以被认为是一个token。
Timestep t:表示扩散过程的时间步
Label y:条件生成任务中的类别标签
Embed(嵌入):分块后的每个 patch 会通过一个嵌入层(通常是一个线性变换),被转换为一个高维 token 表示。
左侧是加噪的潜变量再经过patchify分成多个小块也就是token,类似vit将二维矩阵输入转化为序列化 token 表示。
右侧是时间步和条件任务标签(像是一种约束条件)再通过embed嵌入到高维方便和token结合。
左侧是一种主要输入,右侧像是一种辅助信息,进行融合也就是token和时间步和标签信息进行融合以便于更好的生成。
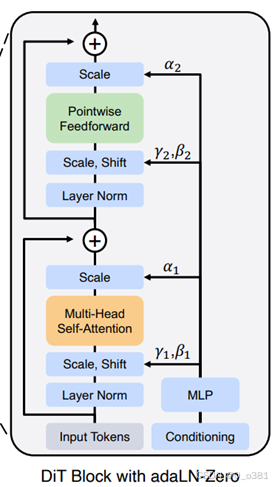
Input Tokens:加噪的潜变量分块 token
Conditioning:条件输入,包括扩散步骤(Timestep t)和可能的标签(Label y)。MLP:条件输入通过MLP(多层感知机)转换为条件向量Scale(α)全局缩放,Scale(γ)缩放向量和Shift(β)偏移向量。
主干第一部分:输入向量先经过LN层进行层归一化,再经过自适应缩放和位移作用是它们分别控制特征的幅度(范围)和中心(偏移),幅度也就是根据噪声强度进行调整,而中心的调整则是对条件类别标签的响应,再经过多头注意力机制融入全局信息,再经过全局缩放变量控制模块输出强度,最后经过残差链接保留原始输入特征并且融入全局特征
主干第二部分:拥有原始输入特征并且融入全局特征的输入,首先经过LN层归一化再经过自适应缩放和位移,再经过FFN也就是经过一个全连接层再经过一个激活函数再经过一个全连接层,作用是弥补了Attention的不足,专注于对每个Token的独立特征进行细粒度调整,再经过一个全局缩放变量控制模块输出强度,最后再经过一个残差确保Pointwise Feedforward模块的输出和输入特征的有效结合,同时增强模型的训练稳定性和特征表达能力。
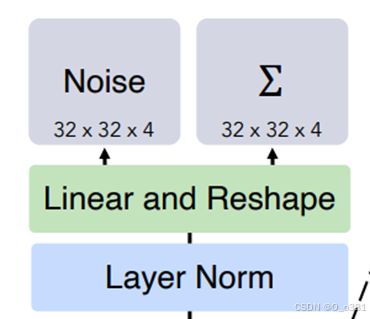
将经过DIT block的输入特征首先经过层归一化,再经过线性变换和reshape生成noise和Σ两个特征,
Noise:表示生成过程中需要的噪声分布
Σ:表示与输入特征相关联的结构化潜在特征,通常用于描述数据的潜在结构和语义信息
扩散模型中的 Noise 实际上是指模型需要从当前带噪状态中去除的噪声
传统的difussion model训练一般只有一个时间步,但在dit当中这个Σ就充当这个时间步的角色,只是它包含的信息更多不止有时间步还有其他信息例如类型标签

















 2508
2508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









