







前置学习:详解Transformer中Self-Attention以及Multi-Head Attention_transformer multi head-优快云博客
图解:
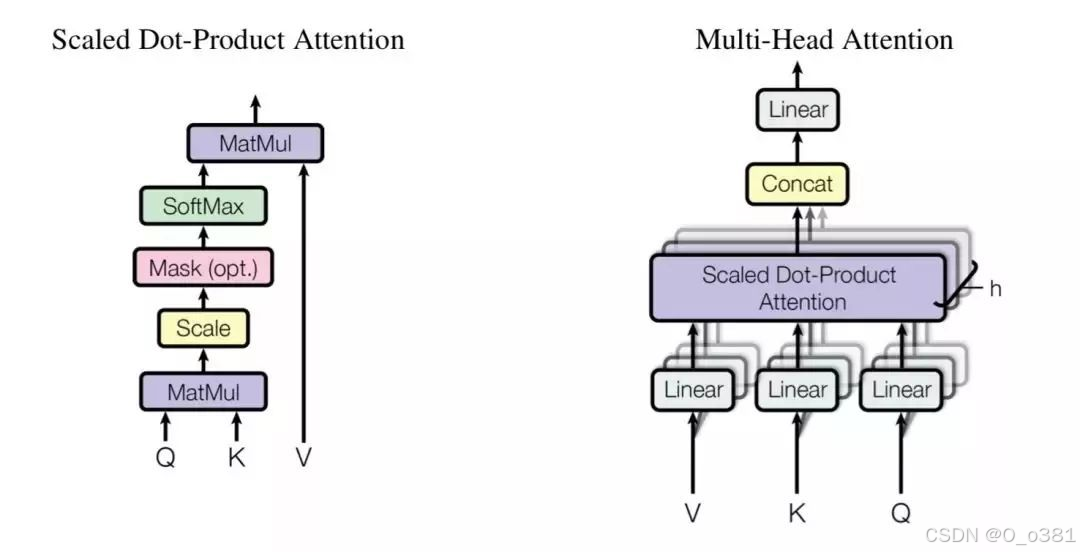
核心公式:
代码:
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的dim
num_heads=8, #多头注意力中的头数(默认值为 8)
qkv_bias=False, #是否在生成 Q、K、V 时使用偏置项(默认是 False)
qk_scale=None, #Q 和 K 之间的缩放因子(默认是None)
attn_drop_ratio=0., #注意力权重的 dropout 比率(默认为 0)
proj_drop_ratio=0.): #输出的投影后的 dropout 比率(默认为 0)
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
#将输入的维度 dim 等分成 num_heads 个头,每个头的维度就是 dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
#注意力的缩放因子,通常设置为 head_dim ** -0.5,即每个头的维度的倒数平方根。
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
#通过一个线性层将输入的特征维度 dim 映射到 dim * 3
#这三个维度分别对应生成 Q(查询),K(键),V(值)
self.attn_drop = nn.Dropout(attn_drop_ratio)
#定义了一个 Dropout 层,用于在计算注意力时丢 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









