







概述:知识蒸馏是一种模型压缩技术,通过让轻量化的学生模型模仿复杂教师模型的输出概率分布,结合软目标和硬目标进行训练,从而将教师模型的泛化能力迁移至学生模型,实现小模型的高效部署而不显著降低性能。
硬目标(hard targets):就是传统的one—hot编码,每个样本的标签严格对应一个类别,例如:狗 → [1, 0, 0],猫 → [0, 1, 0],车 → [0, 0, 1]。它只提供非黑即白的监督信号(即“是猫就不是狗或车”),不包含类别之间的关联信息。
软目标(soft targets): 是教师模型通过 带温度参数(T)的softmax 输出的概率分布。例如,一张狗的图片可能生成如下概率:
[狗: 0.55, 猫: 0.4, 车: 0.05]
关键信息:
-
类别间关系:概率分布不仅包含正确类别(狗),还隐含了不同类别的相似性(狗和猫概率较接近,说明视觉/语义特征可能存在部分相似;而车与狗差异显著,概率差距大)。
-
知识泛化:相比硬目标的绝对判断(One-Hot),软目标提供了更丰富的监督信号,帮助学生模型学习教师模型的决策边界和特征关联性。
知识:A more abstract view of the knowledge, that frees it from any particular instantiation, is that it is a learned mapping from input vectors to output vectors.(原文),这种理解从根本上解释了为何学生模型(即使结构不同)能通过匹配输入-输出映射来继承知识——因为真正迁移的是隐藏在概率分布中的特征空间几何结构,而非具体的参数实现方式。
-
传统认知:知识存储在模型参数中(权重/偏置)
-
蒸馏视角:知识体现为输入到输出向量的非线性映射关系,特别是:
-
类间相对概率(如"猫vs狗"=0.7:0.3)
-
错误类别的排序关系(如将卡车误判为汽车的概率高于误判为猫)
-
教师模型(Teacher Model)和学生模型(Student Model):在知识蒸馏中,教师模型(Teacher Model) 是一个复杂的高性能模型(如深度神经网络),它通过训练学习到了输入到输出的复杂映射关系;学生模型(Student Model) 则是一个更轻量化的模型(如浅层网络),通过模仿教师模型的输出概率分布(软目标)而非直接学习数据标签(硬目标),从而在保留较高准确率的同时显著降低计算复杂度。两者的核心区别在于:教师模型提供“知识”(概率分布中的类间关系),学生模型学习“提炼”后的知识,实现高效迁移。
温度(temperature,T):控制知识蒸馏中概率分布的平滑度,带温度的softmax:
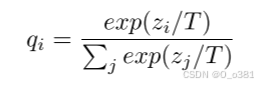
以[狗: 0.6, 猫: 0.3, 马: 0.08 车: 0.02]为例不同T的输出:
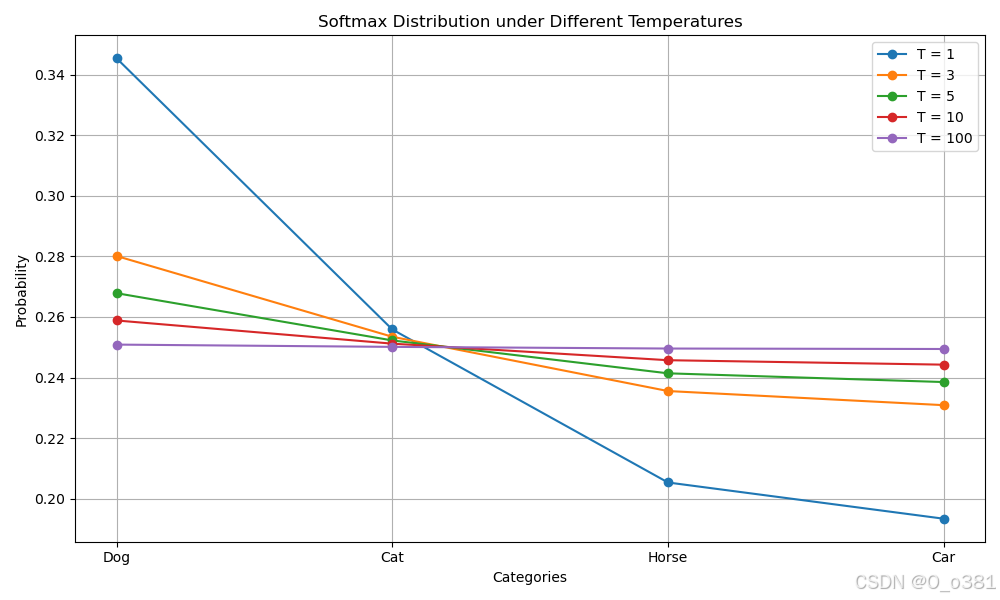
可以看出
-
T=1(蓝线):原始概率分布,差异明显(如"狗"概率最高,"车"最低)
-
T增大(3→100):分布逐渐平滑,次要类别(如猫/马)概率被拉高
-
极端高温(T=100):各类别概率趋近均匀(知识完全模糊化)
核心结论:温度T越高,模型输出的类别间差异越小,越能暴露潜在的"暗知识"(如狗/猫的相似性)。蒸馏时用高温(如T=3-10)训练,使小模型学到更多类别关系。
在知识蒸馏中采用高温(T>1)软化概率分布的核心目的在于:通过放大教师模型输出概率中次要类别的信号,使学生模型不仅能够学习到基础的正确分类结果(硬目标),更重要的是掌握教师模型对类别间相似性的深层理解(如"猫与狗的视觉特征比猫与汽车更接近")。这种 softened targets 本质是将教师模型隐式学习的特征空间拓扑结构显式地传递给学生模型,使得轻量化的学生网络在压缩参数量级的同时,仍能保留原模型的关键判别逻辑和泛化能力,实现"不仅知其然,更知其所以然"的知识迁移效果。但需注意的是,当温度T设置过大时,所有类别的概率会趋于均匀分布,导致原本有意义的类别关系信息被过度稀释,反而放大了噪声信号,使知识迁移失效。
训练过程:
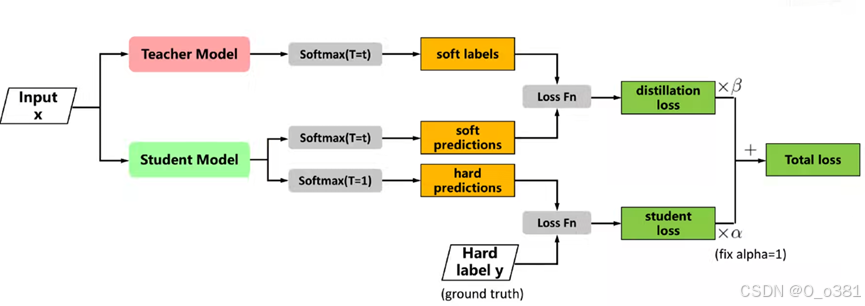
1. 输入阶段
-
输入数据:统一输入样本 x,同时喂入教师模型和学生模型,作为两者的处理对象。
2. 教师模型处理
-
生成软标签(Soft Labels): 教师模型对输入 x 进行推理,通过 Softmax(T=t) 计算输出。这里的 T 是温度参数,较高的 T 会软化概率分布(如平滑类别概率差异),生成包含更多类别关联信息的 软标签,传递教师模型的 “隐性知识”。
3. 学生模型处理
-
双输出机制:
-
软预测(Soft Predictions):学生模型对输入 x 同样通过 Softmax(T=t) 生成输出,与教师模型的软标签维度一致,用于匹配教师的知识。
-
硬预测(Hard Predictions):学生模型还通过 Softmax(T=1) 生成常规的硬预测结果,用于匹配真实标签 y(Hard Label,即样本的真实类别)。
-
4. 损失计算
-
蒸馏损失(Distillation Loss): 计算学生模型的软预测与教师模型软标签的差异(通过损失函数 (Loss Fn),如交叉熵),结果乘以超参数 (β),约束学生学习教师的泛化知识。
-
学生损失(Student Loss): 计算学生模型硬预测与真实标签 y 的差异(同样用损失函数),结果乘以超参数 (α)(图中固定 (α=1)),确保学生掌握基础分类任务。
5. 总损失整合
-
将蒸馏损失和学生损失加权求和,得到 Total Loss,用于优化学生模型的参数。通过这种方式,学生模型既能学习真实标签的监督信息,又能吸收教师模型的泛化知识,最终在轻量化的同时提升性能。
注意点:
- 超参数平衡:α,β协调硬标签损失与蒸馏损失权重,需依任务调参。
- 温度统一:教师生成软标签、学生输出软预测的温度 T 必须一致。
- 教师性能:教师模型需预训练至优,保证软标签知识可靠。
- 温度作用:T 调控分布平滑度,按任务特性选择。
- 教师参数固定:训练学生时,教师模型参数冻结,稳定学习目标。
- 输入一致:师生模型输入数据分布、预处理保持相同。
扩展:(基本到此核心思想就结束了)另外是文中的一些其他东西
1.Matching logits is a special case of distillation就是证明在特定条件下(高温极限 + logits 零均值化),知识蒸馏(KD)的优化目标会退化为直接匹配教师模型和学生模型的 logits(即最小化均方误差,MSE)。
2.Training ensembles of specialists on very big datasets,并行训练专家模型,集成模型可以得到更好的教师模型
3.Soft Targets as Regularizers,软目标可以作为正则化
4.
5.
原文链接:1503.02531
推荐讲解:【【精读AI论文】知识蒸馏】https://www.bilibili.com/video/BV1gS4y1k7vj?vd_source=faed798d49591a5777b139f1be75048b


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









