







transfomer学习|大白话讲解transformer 简述
0 前言
今天开始学习DataWhale组队学习fun-transformer,今天学习task2 transformer 简述!
【教程地址】
【开源地址】
1. Attention 机制
1.1 深度学习中如何引入Attention 机制
以前的翻译方法
想象一下,你要把一段话从中文翻译成英文,以前的方法是这样的:
- 编码器(读句子):有个机器(编码器)先把你要翻译的中文句子读一遍,然后它会把整个句子的意思压缩成一个“总结”,这个总结就像是把句子的核心意思打包成一个小包裹。
- 解码器(翻译句子):然后,另一个机器(解码器)拿到这个小包裹,开始一个词一个词地把英文翻译出来。
听起来好像还不错,对吧?但问题来了:
- 句子太长就懵了:如果中文句子很长,那个“总结”就会变得很糟糕,因为机器记不住前面的内容,只能记住最近看到的那点东西。这就像是你记笔记,只记得最后写的那几行,前面的全忘了。
- 分不清重点:还有一个问题是,机器在翻译的时候,不知道哪些词更重要。比如,翻译“我喜欢吃苹果”,它不知道“喜欢”这个词比“苹果”更重要,所以翻译出来可能就会很奇怪。
注意力机制的出现
后来,有个聪明的人(Bahdanau)想了个好办法,这个办法就叫“注意力机制”。
他觉得,能不能让机器在翻译的时候,不仅看那个“总结”,还能记住句子里的每个词,并且知道哪些词更重要。就好像你在翻译的时候,会重点看那些关键的词,而不是只看一个大概的意思。
具体来说,注意力机制是这样工作的:
- 看每个词:机器先把句子里的每个词都看一遍。
- 给每个词打分:然后,它会根据每个词的重要性给它们打分,重要的词就多给点分,不重要的就少给点。
- 集中注意力:当机器开始翻译的时候,它会根据这些分数,重点看那些重要的词,就像你翻译的时候会重点看那些关键的词一样。
- 加权求和:最后,它把所有词的信息加起来,但会给那些重要的词更多的权重,这样就能生成一个更好的翻译。
注意力机制的好处
这个新方法的好处很明显:
- 长句子也能翻译好:因为机器不再是只看一个“总结”,而是能记住句子里的每个词,所以长句子也能翻译得更准确。
- 知道重点在哪里:机器还能分清楚哪些词更重要,这样翻译出来的句子就会更自然、更准确。
注意力机制就像是给机器装了一双“会思考的眼睛”,让它在翻译的时候能更好地理解句子的意思,还能分清楚哪些地方更重要。
1.2 Attention 机制如何起作用?
Attention机制是怎么工作的
- 分解输入:就好比你有一篇文章,计算机先把这篇文章拆成一个个单词,这样方便它一个个去处理。
- 挑重点:计算机就像老师批改作业一样,看看这些单词里哪些是重要的。它是通过把每个单词和自己心里想的问题(也就是“查询”)对比,看看哪个单词和问题更相关。
- 打分:计算机给每个单词打个分,分数高就说明这个单词很重要,和问题关系大;分数低就说明不太重要。
- 分配注意力:计算机根据分数来决定对每个单词的关注程度。分数高的单词,它就多看几眼;分数低的单词,就少看几眼。
- 加权求和:最后,计算机把所有单词的信息加起来,但不是平均加,而是给分数高的单词多加点,分数低的少加点。这样,重要的信息就会在结果里占更大的比重,计算机就能更清楚地知道输入里最重要的内容是什么。
Attention机制为啥厉害
- 类比人类学语言:
- 死记硬背:就像你刚开始学英语,背单词、背语法,啥都背,但还不太懂意思,这就是RNN时代,模型也是一样,啥都记,但不太会筛选重点。
- 提纲挈领:等你学得差不多了,就能在聊天的时候抓住关键词,比如别人说了一大堆,你只要听懂几个关键的词,就能明白大概意思。Attention模型就是学会了这个本事,能找出重点。
- 融会贯通:再往后,你不仅能听懂关键词,还能理解上下文,知道前因后果,还能举一反三。Transformer模型就达到了这个水平,能更好地理解语言的复杂关系。
- 登峰造极:最后,你通过大量的练习,变得很厉害,能应对各种复杂的情况。GPT、BERT这些模型就是通过大量的学习和练习,变得很强大。
- 为啥Attention厉害:因为它让模型学会了抓重点,就像人一样,不是啥都记,而是挑重要的记,这样效率高多了。它让模型从“啥都记但不懂重点”,变成了“能抓住重点、理解关系”,就像人突然开窍了一样。
1.3 全局注意力与局部注意力
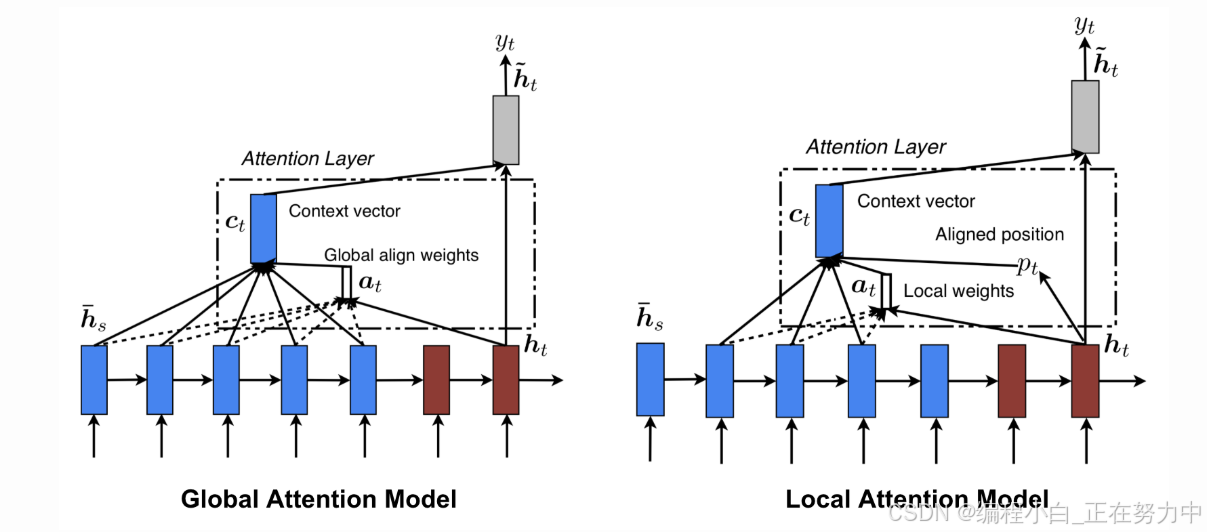
全局注意力和局部注意力是什么?
想象一下,你正在看一部电影,然后要给别人讲这部电影的内容。
- 全局注意力:就好像是你把电影的每一帧画面都仔细看了一遍,然后把所有画面的信息都综合起来讲给别人听。这种方法很仔细,但也很费时间,因为你得处理电影里的每一个细节。
- 局部注意力:就聪明多了,它只挑电影里最重要的几个片段来看,然后根据这些片段讲给别人听。这样既节省时间,又能抓住重点。
局部注意力是怎么工作的?
局部注意力主要分三步:
-
找重点位置(预测对齐位置):
- 假设你正在写一篇影评,现在要写到电影里的一个关键情节。局部注意力会先猜一猜,这个情节在电影的哪个时间点(位置)最重要。比如,它可能会猜这个情节在电影的第30分钟最精彩。
-
划重点范围(定义注意力窗口):
- 找到重点位置后,它不会只看那一秒的内容,而是会在这个位置周围划一个范围。比如,它会看从第25分钟到第35分钟的内容,这个范围就是“窗口”,窗口的大小可以根据需要调整。
-
总结重点内容(计算上下文向量):
- 在这个窗口里,它会看看哪些内容更重要,然后把重要的内容加权平均一下,总结出一个“重点内容”。比如,它可能会觉得第28分钟到第32分钟的内容最关键,就把这些内容的重点提取出来,用来写影评。
对齐方式
对齐方式就是怎么找到那个重点位置的方法,有两种:
-
单调对齐
-
大白话解释:
单调对齐的意思就是“按部就班”地对齐。
想象一下,你在翻译一篇文章,翻译到第3个词的时候,就只关注原文的第3个词或者第3个词附近的词,不会去考虑太远的内容。
换句话说,就是假设当前时间点 t t t时,只有 t t t附近的信息才是重要的。这种对齐方式比较简单,就像是按照顺序一步步来,不会跳来跳去。 -
公式:
单调对齐的公式是: p t = t p_t = t pt=t这里的 p t p_t pt表示对齐位置,而 t t t就是当前的时间步。也就是说,对齐位置就是当前的时间步,非常直接。
-
-
预测对齐
-
大白话解释:
预测对齐就更聪明一点了,它不是简单地按照顺序来,而是让模型自己去“猜”(预测)在源句子中哪个位置的词和当前目标词最相关。比如,你在翻译“我喜欢吃苹果”这句话,翻译到“苹果”这个词的时候,模型可能会预测源句子中“苹果”这个词的位置,而不是简单地按照顺序对齐。 -
公式:
预测对齐的公式是: p t = S ⋅ s i g m o i d ( v p ⊤ tanh ( W p h t ) ) p_t = S \cdot \mathrm{sigmoid}(v_p^\top \tanh(W_p h_t)) pt=S⋅sigmoid(vp⊤tanh(Wpht))
其中, h t h_t ht:这是解码器在当前时间步
t t t的隐藏状态,可以理解为模型当前的“状态”或“理解”。
W p W_p Wp和 v p v_p vp:这两个是模型训练过程中学到的参数,就像是模型用来做预测的“工具”。
tanh ( W p h t ) \tanh(W_p h_t) tanh(Wpht):这部分是把当前状态 h t h_t ht通过一个变换(用矩阵 W p W_p Wp乘以它,再通过 tanh \tanh tanh函数处理),得到一个“调整后的状态”。 v p ⊤ tanh ( W p h t ) v_p^\top \tanh(W_p h_t) vp⊤tanh(Wpht):然后用另一个参数 v p v_p vp和这个调整后的状态做一个点积,得到一个标量(一个数字)。
s i g m o i d ( ⋅ ) \mathrm{sigmoid}(\cdot) sigmoid(⋅):这个函数会把前面得到的数字“压缩”到0和1之间,这样可以表示一个概率或者比例。
S ⋅ s i g m o i d ( ⋅ ) S\cdot \mathrm{sigmoid}(\cdot) S⋅sigmoid(⋅):最后,乘以源句子的长度 S S S,得到一个具体的对齐位置 p t p_t pt。
-
全局和局部的区别
- 全局注意力:就像把整部电影都看完再写影评,很全面,但很费时间。
- 局部注意力:就像只看几个关键片段就写影评,既快又能抓住重点。
全局注意力考虑所有隐藏状态(蓝色),而局部注意力仅考虑一个子集。
2. Transformer概述

2.1 Transformer模型
你有个朋友,他特别厉害,能听懂你说的话,还能用另一种语言把意思准确地翻译出来。Transformer模型就像是这样一个超级聪明的“翻译官”,它能够理解语言,并且把一种语言转换成另一种语言,或者完成其他和语言相关的任务,比如总结文章、回答问题等等。
2.2 Transformer模型是怎么工作的?
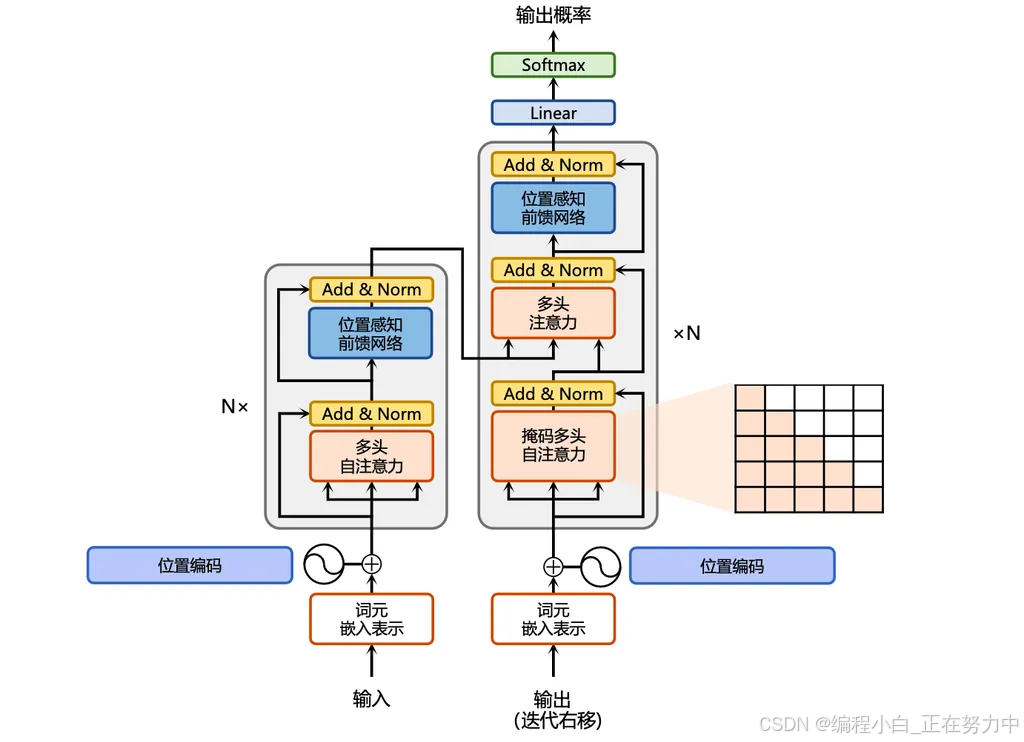
这个模型有点像一个“超级大脑”,它分为两个主要部分:编码器(Encoder)和解码器(Decoder)。
-
编码器(Encoder):理解输入
编码器的作用就是“听懂”你给它的内容。比如你给它一段英文,编码器会把这段英文“嚼碎”,变成它能理解的“内部语言”。这个过程有点像你把食材放进搅拌机,搅拌成糊糊一样,只不过编码器搅拌出来的是信息的精华。 -
解码器(Decoder):生成输出
解码器的作用是把编码器搅拌好的“信息精华”再“组装”成你需要的东西。比如,你希望把英文翻译成中文,解码器就会根据编码器的理解,把中文“拼出来”。
2.3 Transformer的几个关键点
Transformer模型有几样特别厉害的“工具”,让它能够很好地完成任务:
-
位置编码(Positional Encoding)
语言是有顺序的,比如“我吃饭”和“饭吃我”,意思完全不一样。Transformer模型本身不知道顺序,所以它需要一个“指南针”来记住每个词的位置。这个“指南针”就是位置编码,它会给每个词加上一个标记,告诉模型这个词在句子中的位置。 -
多头注意力(Multi-Head Attention)
想象一下,你同时看几本书,每本书都有一些重要的内容,但你的眼睛只能看一个地方。Transformer模型用“多头注意力”解决了这个问题,它就像有好几个脑袋,可以同时关注句子中的不同部分。比如,它在翻译“我吃饭”时,一个“脑袋”关注“我”,另一个“脑袋”关注“饭”,这样就能更好地理解整个句子的意思。 -
前馈网络(Feed-Forward Network)
这个东西有点像一个“超级处理器”,它会把编码器和解码器处理的信息再加工一下,让信息更准确。你可以把它想象成一个厨房里的搅拌机,把食材搅拌得更细腻。
2.4 Transformer模型的工作流程
假设你有两个句子:
- The cat drank the milk because it was hungry.
- The cat drank the milk because it was sweet.

在第一个句子中,“it”指的是“猫”,而在第二个句子中,“it”指的是“牛奶”。Transformer模型怎么知道“it”到底指什么?
-
编码器开始工作
编码器先把句子“嚼碎”,每个词都被转换成一个“信息块”,同时加上位置编码,让模型知道这个词的位置。 -
多头注意力发挥作用
多头注意力开始工作,它会同时关注句子中的不同部分。比如,一个“头”发现“it”和“cat”有关系,另一个“头”发现“it”和“hungry”有关系。通过这种方式,模型就能理解“it”到底指什么。 -
解码器生成输出
解码器根据编码器的输出和多头注意力的结果,开始“组装”翻译结果。它会根据上下文,把“it”翻译成正确的词。
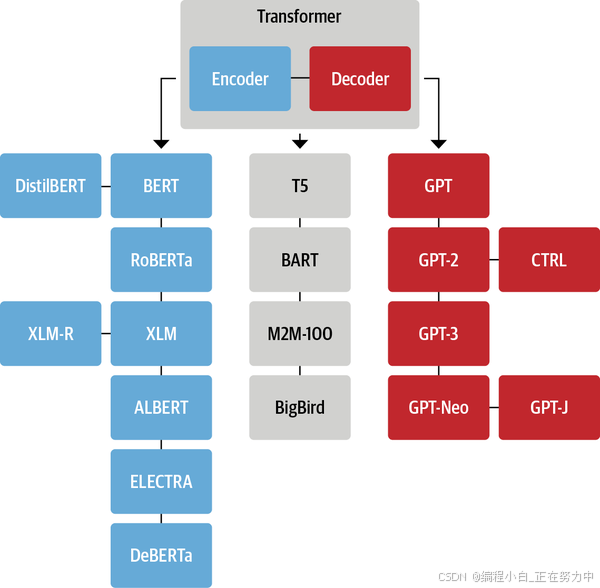
2.5 Transformer模型的发展
- 2013年:开始有了word Embedding,就是把词变成数字,方便计算机处理。
- 2017年:Transformer模型横空出世,它用一种全新的方式处理语言,效率高得多。
- 2018年:出现了很多基于Transformer的模型,比如BERT和GPT-1,它们在各种语言任务上表现超棒。
- 2019年:模型越来越大,也越来越厉害,比如GPT-2。
- 2020年:GPT-3出现,它的参数量超级大,能做的事情也更多。
2.6 Transformer对seq2seq模型的影响
-
摒弃了RNN结构
以前的seq2seq模型用的是RNN,就像你读一本书,必须从第一页开始,一页一页按顺序读下去,前面的内容会影响你对后面内容的理解。但RNN有个缺点,读得太慢,而且有时候读到后面就忘了前面的内容(长距离依赖问题)。Transformer就不一样了,它直接把RNN扔掉,改用一种新的方法来处理序列,就像你同时看到书的每一页,一下子就能把所有内容都处理完,效率高多了。 -
引入自注意力机制
Transformer用了一种叫“自注意力”的机制。想象一下,你在听一个故事,故事里有很多人物和情节。自注意力机制就像你一边听故事,一边能同时关注到故事里所有人物之间的关系,而不是只关注前面讲的内容。它会计算每个元素和其他所有元素之间的关系,给每个元素一个“加权表示”,这样就能更好地理解全局的情况,比如故事里的人物之间是怎么互动的。这就解决了RNN只能依赖前面信息的问题,让模型能更好地捕捉长距离的依赖关系。 -
位置编码
Transformer虽然能同时处理所有元素,但它不知道这些元素的顺序。比如,句子“我爱自然语言处理”和“自然语言处理爱我”,意思完全不同,因为单词的顺序不一样。为了解决这个问题,Transformer给每个元素加了一个“位置编码”,就像给每个单词贴了个标签,告诉模型这个词在句子中的位置。这样一来,模型就能同时知道元素的内容和顺序了。 -
编码器 - 解码器架构的改进
Transformer把编码器和解码器都堆叠了好几层,每层里面有自注意力和前馈网络两个部分。这就像是搭积木,一层一层往上搭,让模型变得更强大,能够学习到更复杂的东西。以前的模型可能只能搭一层两层,Transformer可以搭好多层,所以表达能力更强。 -
训练效率的提升
因为Transformer能同时处理所有元素,所以训练的时候速度特别快。以前用RNN训练,就像排队买票,一个人一个人慢慢来;Transformer就像同时开了很多个窗口,大家一起买票,效率高了很多。这样就能处理更长的序列,训练时间也大大缩短。 -
在NLP领域的广泛应用
Transformer在自然语言处理里特别厉害,就像一个超级英雄,到处解决问题。比如在机器翻译上,它能把一种语言很准确地翻译成另一种语言;在文本摘要上,它能把一篇长文章快速总结成几句话;在问答系统里,它能准确地回答问题。因为它效果好,所以大家都用它。 -
促进了预训练模型的发展
Transformer的成功还催生了像BERT这样的预训练模型。BERT就像是Transformer的“升级版”,它先在海量的数据上学习通用的语言知识,然后再去解决具体的问题。这就像是你先在学校里学了很多基础知识,然后去参加各种考试,成绩肯定比直接去考试好得多。BERT等预训练模型让自然语言处理的效果又上了一个台阶。
2.7 迁移学习
迁移学习就像是“借力打力”。你有个朋友,他花了很长时间学会了做一道复杂的菜。现在你想做这道菜,但不想从头学起,所以你直接请教他,让他教你怎么做。这样你就能少走很多弯路。
在Transformer模型中,迁移学习就是用别人已经训练好的模型,然后在自己的任务上稍微调整一下。比如,BERT是一个很厉害的预训练模型,它已经学会了语言的很多规律。你可以直接用BERT,然后在自己的任务上(比如翻译或者问答)稍微调整一下参数,就能得到很好的结果。
3 Transformer vs CNN vs RNN:三巨头的工作方式大揭秘

3.1 生活案例
假设你是一个快递站站长,要处理三种不同的包裹分拣需求:
- Transformer分拣法:同时拆开所有包裹,直接扫描每个包裹的关键信息
- CNN(卷积神经网络)分拣法:用扫描仪逐个区域检查包裹外观
- RNN(循环神经网络)分拣法:必须按顺序拆包裹,拆完第一个才能拆第二个
这恰好对应了三种模型处理数据的核心差异,接下来用具体参数拆解。
3.2 计算复杂度:谁更省力?
假设处理10个单词的句子(n=10),每个单词用300维向量表示(d=300):
| 模型 | 计算量公式 | 实际计算量 | 类比解释 |
|---|---|---|---|
| Transformer | O(n²·d) =10²×300 | 30,000 | 同时对比所有词的关系,像10人开会讨论 |
| RNN | O(n·d²) =10×300² | 900,000 | 逐个传递信息,像10人传话游戏 |
| CNN | O(k·n·d²) =3×10×300² | 2,700,000 | 用3种滤镜扫描每个位置 |
关键发现:
- 当句子长度n < 维度d时(常见情况),Transformer最快
- 处理1000字长文时,Transformer计算量暴涨(1000²×300=3亿),此时可用受限注意力(只关注前后r个词),复杂度降为O(r·n·d)

3.3 并行能力:谁能多线程工作?
用工厂流水线比喻并行能力:
| 模型 | 并行能力 | 现实类比 | GPU加速效果 |
|---|---|---|---|
| Transformer | 全并行(O(1)) | 所有工人同时组装不同零件 | ⚡️ 10倍提速 |
| CNN | 部分并行 | 多个扫描仪同时工作 | ⚡️ 5倍提速 |
| RNN | 完全串行(O(n)) | 必须等A工人干完B才能接着干 | 🐢 难以加速 |
技术内幕:
- Transformer的自注意力机制允许同时计算所有位置关系
- RNN因依赖前序状态,如同多米诺骨牌必须依次倒下
3.4 长距离关联:谁能记住全局?
假设要理解这句话:“尽管昨天下雨导致交通堵塞,我还是准时参加了那个关于人工智能发展趋势的会议”
| 模型 | 关联能力 | 传递次数 | 现实类比 |
|---|---|---|---|
| Transformer | 一步到位(O(1)) | 1次 | 直接视频会议,全员同时沟通 |
| CNN | 逐步传递 | 每层覆盖k个词 | 需要6层卷积才能关联首尾 |
| RNN | 逐字传递 | n次 | 像传话游戏,传到最后已变味 |
实验数据:
- 在100词文本中,"会议"与开头"下雨"的关联权重:
- Transformer:0.28(直接关联)
- CNN经过5层后:0.15
- RNN:0.07(信息衰减严重)
3.5 Q/K/V机制:智能搜索的三要素
用找餐厅比喻自注意力机制:
# 搜索条件(Query)
我的需求 = {
"人均预算": 150元,
"菜品类型": "川菜",
"距离范围": "3公里内"
}
# 餐厅数据库(Key-Value对)
餐厅1 = {
"Key": ["人均120元", "水煮鱼招牌", "2.5公里"],
"Value": "★★★★☆ 口味4.5分"
}
餐厅2 = {
"Key": ["人均180元", "粤式点心", "1.8公里"],
"Value": "★★★★★ 环境5分"
}
# 计算匹配度(点积相似度)
匹配度1 = 计算(我的需求, 餐厅1.Key) → 0.92
匹配度2 = 计算(我的需求, 餐厅2.Key) → 0.65
# 最终结果 = Σ(匹配度 × Value)
推荐结果 = 0.92×"4.5分川菜" + 0.65×"5分粤菜" → 综合推荐
技术映射:
- 每个单词生成自己的Q/K/V向量(维度拆分)
- 通过Q·K^T计算关联权重,加权求和V得到新表示
3.6 选型指南:什么场景用谁?
| 场景 | 推荐模型 | 原因说明 |
|---|---|---|
| 长文本理解(论文分析) | Transformer | 全局关联能力强,适合长距离依赖 |
| 图像识别 | CNN | 局部特征捕捉效率高 |
| 实时语音处理 | RNN变体(LSTM) | 流式数据处理有优势 |
| 多模态任务 | Transformer | 天然支持文本/图像/语音对齐 |
性能对比(1小时训练数据量):
- Transformer(8卡A100):处理800万token
- CNN同配置:处理1200万token
- RNN同配置:仅处理150万token
4. 输入嵌入(Input Embedding):给句子中的词穿上“外衣”
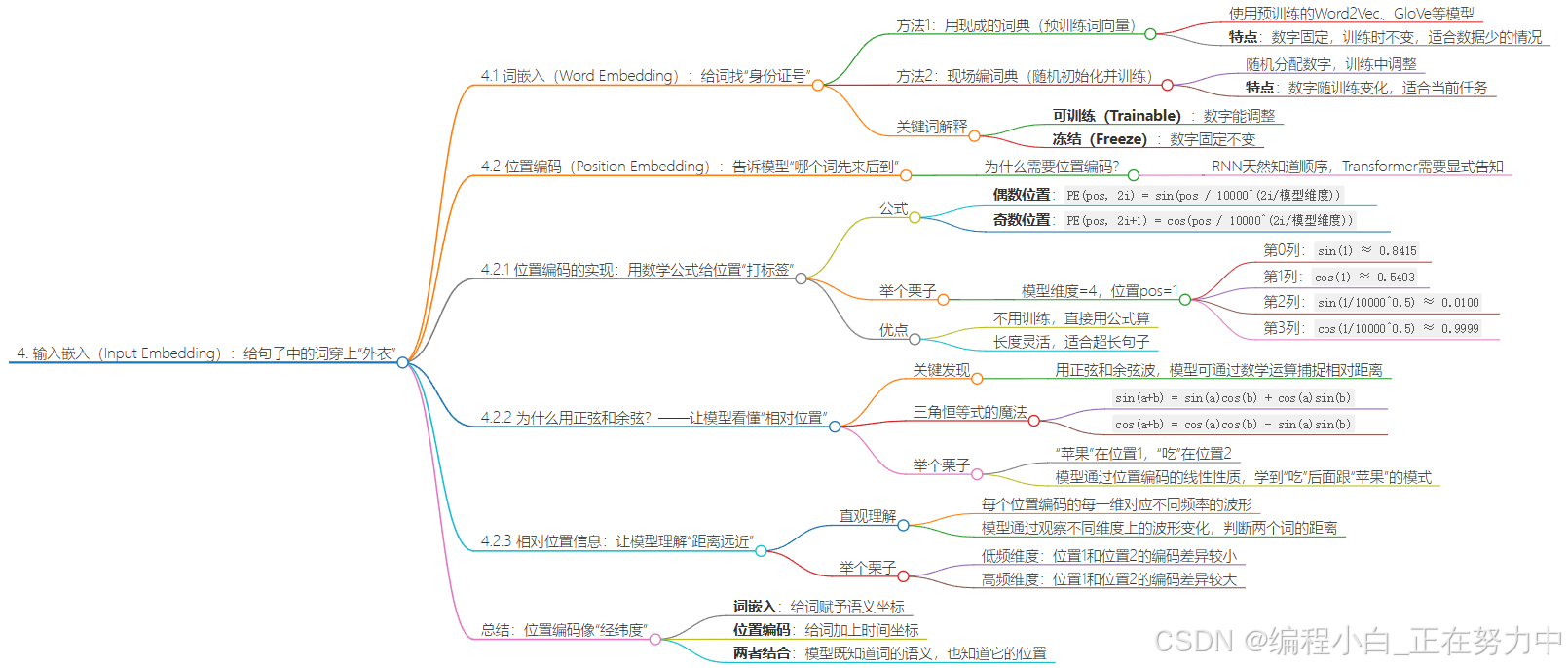
Transformer模型处理句子时,需要先给每个词穿上两件“外衣”:
- 词的外衣(Word Embedding):用一串数字表示词的语义(比如“猫”对应[0.2, -0.5, 1.3…])。
- 位置的外衣(Position Embedding):用另一串数字表示词的位置(比如第一个词加[0.1, 0.3…],第二个词加[0.2, 0.5…])。
这两件“外衣”会被叠穿在一起(相加),让模型既知道词的意思,又知道它的位置。
4.1 词嵌入(Word Embedding):给词找“身份证号”
假设我们要把词语变成计算机能理解的数字,有两种方法:
方法1:用现成的词典(预训练词向量)
- 比如用《新华字典》里的解释(预训练的Word2Vec、GloVe等模型),直接把“猫”对应的数字拿过来用。
- 特点:这些数字是固定的,训练模型时不会改动。适合数据少的情况,直接借用现成的知识。
方法2:现场编词典(随机初始化并训练)
- 比如给每个词随机分配一串数字(如“猫”初始化为[0.1, -0.2, 0.4…]),然后让模型在训练中自己调整这些数字。
- 特点:数字会随着训练不断变化,最终更适合当前任务(比如专门识别动物名的任务)。
关键词解释:
- 可训练(Trainable):数字能调整(比如从[0.1]变成[0.15])。
- 冻结(Freeze):数字固定不变。
4.2 位置编码(Position Embedding):告诉模型“哪个词先来后到”
为什么需要位置编码?
- RNN像人读书一样逐字看句子,天然知道顺序。
- Transformer像同时摊开所有字,必须显式告诉它顺序,否则会认为“猫抓老鼠”和“老鼠抓猫”是一样的。
4.2.1 位置编码的实现:用数学公式给位置“打标签”
不用学习位置信息,而是用固定公式生成位置编码。公式长这样:
-
偶数位置(第0、2、4…列):用正弦波
PE(pos, 2i) = sin(pos / 10000^(2i/模型维度)) -
奇数位置(第1、3、5…列):用余弦波
PE(pos, 2i+1) = cos(pos / 10000^(2i/模型维度))
🌰 举个栗子:
假设模型维度是4(即每个词用4个数字表示),位置pos=1(第二个词)的位置编码计算如下:
- 第0列(i=0):
sin(1 / 10000^(0/4)) = sin(1) ≈ 0.8415 - 第1列(i=0):
cos(1 / 10000^(0/4)) = cos(1) ≈ 0.5403 - 第2列(i=1):
sin(1 / 10000^(2/4)) = sin(1/10000^0.5) ≈ sin(0.01) ≈ 0.0100 - 第3列(i=1):
cos(1 / 10000^(2/4)) ≈ cos(0.01) ≈ 0.9999
这样做的优点:
- 不用训练:直接用公式算,省事。
- 长度灵活:即使遇到超长句子(比如训练时没见过1000字的句子),也能现场计算位置编码。
4.2.2 为什么用正弦和余弦?——让模型看懂“相对位置”
关键发现:用正弦和余弦波,可以让模型通过数学运算捕捉词与词之间的相对距离。
三角恒等式的魔法:
-
公式中的正弦和余弦波满足:
sin(a+b) = sin(a)cos(b) + cos(a)sin(b)
cos(a+b) = cos(a)cos(b) - sin(a)sin(b) -
这意味着:位置(pos + k)的编码,可以通过位置(pos)的编码线性变换得到。
例如,模型想计算“第3个词和第5个词的位置关系”(k=2),它不需要记住绝对位置,只需用已有的编码做加减乘除就能推导出来。
🌰 举个栗子:
- 假设“苹果”在位置1,“吃”在位置2,模型想学“吃苹果”这个短语。
- 通过位置编码的线性性质,模型更容易学到“吃”后面跟“苹果”(位置差1)的模式。
4.2.3 相对位置信息:让模型理解“距离远近”
直观理解:
- 每个位置编码的每一维对应不同频率的波形(高频维度变化快,低频维度变化慢)。
- 模型通过观察不同维度上的波形变化,就能知道两个词之间的距离是远是近。
🌰 举个栗子:
- 在低频维度(如i=0),位置1和位置2的编码差异较小。
- 在高频维度(如i=50),位置1和位置2的编码差异较大。
- 模型综合所有维度的差异,就能判断两个词是相邻还是隔了很远。
总结:位置编码像“经纬度”
- 词嵌入:给词赋予语义坐标(如“猫”=北纬30度,东经120度)。
- 位置编码:给词加上时间坐标(如“第1个词”=上午8点,“第2个词”=上午9点)。
- 两者结合:模型既知道“猫”在哪里(语义),也知道它出现的时刻(位置),从而理解完整的句子。
5. 词向量生成过程
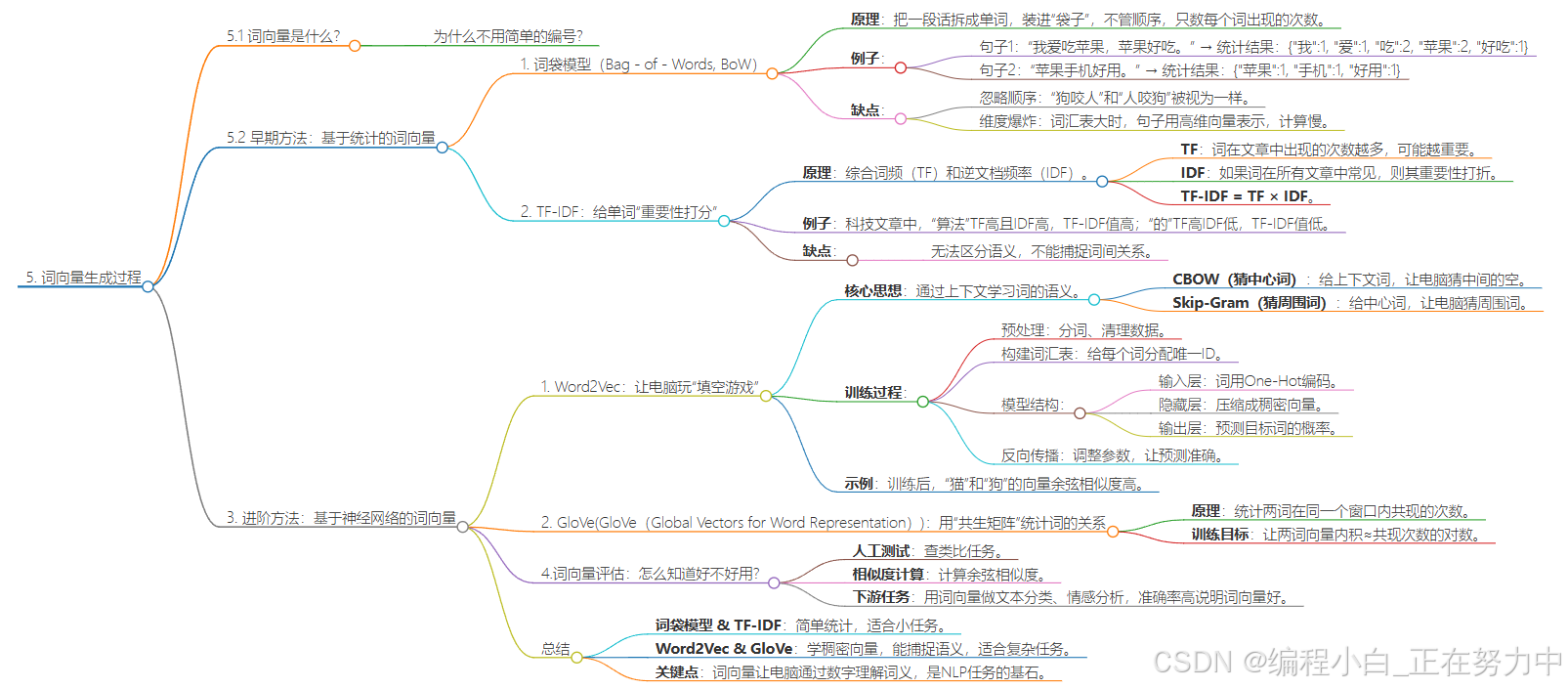
5.1 词向量是什么?
想象你要教电脑理解人类的语言。但电脑只认数字,所以得把文字变成数字。词向量就像给每个词发一张“身份证”,身份证上的数字编码能体现这个词的“性格特点”。比如“猫”和“狗”的身份证数字比较接近,而“猫”和“汽车”的数字差别就大。
为什么不用简单的编号?
比如给“猫=1,狗=2,汽车=3”,这种编号没有意义。电脑看到“猫(1)”和“狗(2)”的距离是1,但实际它们的语义更接近,和“汽车(3)”的距离反而更远。所以需要更聪明的编码方式——这就是词向量。
5.2 早期方法:基于统计的词向量
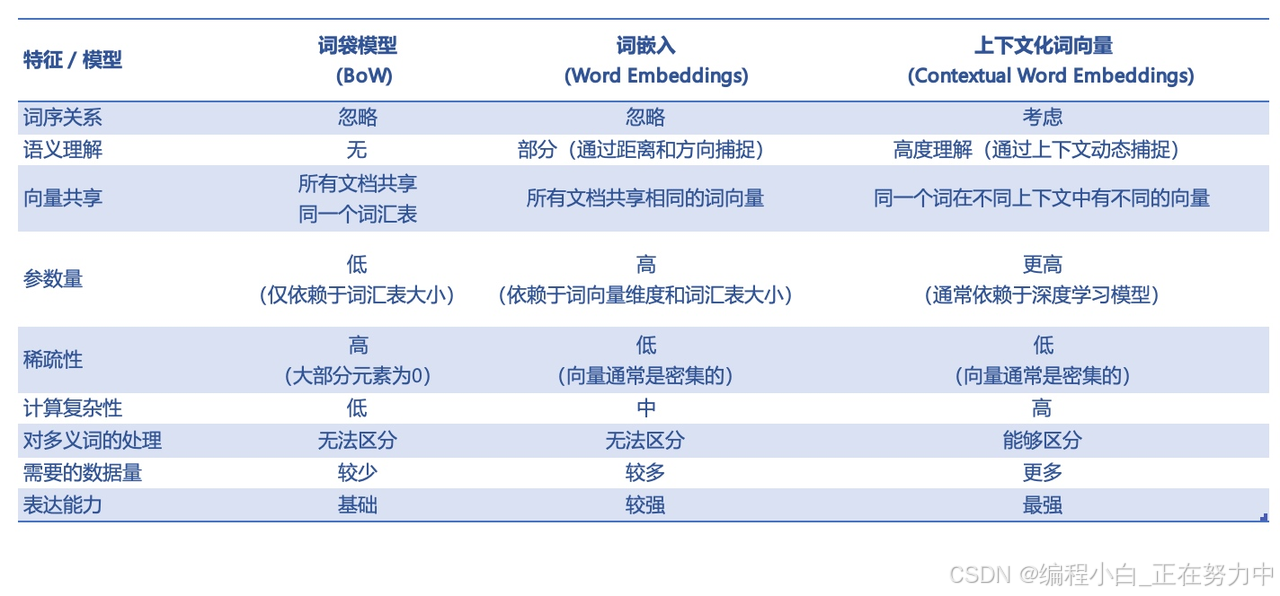
1. 词袋模型(Bag - of - Words, BoW)
原理:
把一段话拆成单词,装进一个“袋子”,不管顺序,只数每个词出现的次数。
例子:
- 句子1:“我爱吃苹果,苹果好吃。” → 统计结果:{“我”:1, “爱”:1, “吃”:2, “苹果”:2, “好吃”:1}
- 句子2:“苹果手机好用。” → 统计结果:{“苹果”:1, “手机”:1, “好用”:1}
缺点:
- 忽略顺序:“狗咬人”和“人咬狗”会被认为一样。
- 维度爆炸:如果词汇表有10万词,每个句子都要用10万维的向量表示,大部分是0,计算慢。
2. TF-IDF:给单词“重要性打分”
原理:
- 词频(TF):一个词在文章里出现的次数越多,可能越重要。比如“苹果”在一篇讲水果的文章里出现10次,TF=10。
- 逆文档频率(IDF):如果一个词在所有文章里都很常见(比如“的”“是”),它的重要性应该打折。比如“苹果”在100篇文章中出现过5次,IDF = log(100/5) ≈ 3。
- TF-IDF = TF × IDF:综合这两个值,给单词打分。
例子:
- 在科技文章中,“算法”可能TF高,且IDF也高(因为只在科技文章出现),所以TF-IDF值高。
- “的”虽然TF高,但IDF极低(几乎所有文章都有),所以TF-IDF值低。
缺点:
- 还是不懂语义:“苹果”是水果还是手机品牌?无法区分。
- 无法捕捉词之间的关系(比如“猫”和“狗”都是宠物)。
3. 进阶方法:基于神经网络的词向量
1. Word2Vec:让电脑玩“填空游戏”
核心思想:
通过上下文学习词的语义。比如“猫吃鱼”,电脑发现“猫”常和“吃”“鱼”一起出现,就把它们的向量设计得靠近。
两种玩法:
- CBOW(猜中心词):给上下文(如“我 爱 __ 处理”),让电脑猜中间的空是“自然语言”。
- Skip-Gram(猜周围词):给中心词“自然语言”,让电脑猜周围可能有“我”“爱”“处理”。
补充:
CBOW(Continuous Bag - of - Words)的全称是连续词袋模型,其核心思想是根据上下文词来预测目标词。它将上下文词的词向量相加或拼接后,通过训练学习目标词的词向量。例如,对于句子“我 爱 学习”,如果目标词是“爱”,上下文词是“我”和“学习”,模型会根据“我”和“学习”的词向量来预测“爱”的词向量。这种模型适用于处理大规模文本数据,能够快速生成词向量,但可能会丢失一些词序信息。Skip - Gram模型则是根据目标词来预测上下文词。它通过目标词的词向量来预测上下文词的词向量,能够更好地捕捉词之间的语义关系。例如,对于句子“我 爱 学习”,如果目标词是“爱”,模型会根据“爱”的词向量来预测“我”和“学习”的词向量。Skip - Gram模型在处理小规模文本数据时表现更好,能够生成更精确的词向量,但训练速度相对较慢。
训练过程:
- 预处理:分词、清理数据(比如去掉标点)。
- 构建词汇表:给每个词分配唯一ID,比如“苹果=0,香蕉=1”。
- 模型结构:
- 输入层:一个词用One-Hot编码(比如“苹果”是[1,0,0,…])。
- 隐藏层:把One-Hot编码压缩成稠密向量(比如100维)。
- 输出层:预测目标词的概率。
- 反向传播:不断调整参数,让预测越来越准。最终,隐藏层的权重就是词向量!
举个栗子:
假设训练后,“猫”的向量是[0.2, -0.5, 0.8],“狗”是[0.3, -0.4, 0.7],它们的余弦相似度高,说明语义接近。
深入浅出讲解Word2Vec:点击播放
2. GloVe(GloVe(Global Vectors for Word Representation)):用“共生矩阵”统计词的关系
原理:
统计两个词在同一个窗口内共现的次数。比如“苹果”和“吃”常一起出现,就给它们高的共生分数。
训练目标:
让两个词的向量内积 ≈ 它们共现次数的对数。公式:
词向量
i
⋅
词向量
j
=
log
(
共现次数
i
j
)
\text{词向量}_i \cdot \text{词向量}_j = \log(\text{共现次数}_{ij})
词向量i⋅词向量j=log(共现次数ij)
这样,共现多的词向量会更接近。
4.词向量评估:怎么知道好不好用?
- 人工测试:查“国王-男人+女人≈女王”这类类比任务。
- 相似度计算:计算“猫”和“狗”的余弦相似度,看是否接近。
- 下游任务:用词向量做文本分类、情感分析,准确率高说明词向量好。
总结
- 词袋模型 & TF-IDF:简单统计,适合小任务,但不懂语义。
- Word2Vec & GloVe:用上下文或共生关系学习稠密向量,能捕捉语义,适合复杂任务。
- 关键点:词向量让电脑通过数字“理解”词义,是NLP任务的基石。
6. 代码实现Word2Vec
# 前期准备工作 安装依赖
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
# pip install genism
# pip install jieba
# pip install matplotlib
# ====================
# 第一部分:基础示例
# ====================
# 导入必要的包
import jieba # jieba分词库,用于对中文文本进行分词处理
# 准备训练数据
# jieba.cut()函数
# 可以对中文文本进行分词处理
# 返回一个可迭代的generator对象
# 可以用list()函数转换为列表
sentences = [
list(jieba.cut( '我喜欢吃苹果' )),
list(jieba.cut( '苹果很好吃' )),
list(jieba.cut( '水果是健康的' )),
list(jieba.cut( '梨子也很好吃' )),
list(jieba.cut( '我也喜欢吃凤梨' )),
list(jieba.cut( '苹果凤梨都是一种水果' )) ,
list(jieba.cut( '苹果是一种又香又甜的水果' )),
list(jieba.cut( '梨子跟凤梨也是一种又香又甜的水果' )),
]
# print(sentences)
# 使用gensim库中的Word2Vec模型来训练词向量,并且获取训练后的词向量和词汇表
from gensim.models import Word2Vec
# 训练词向量模型
# window:窗口大小,词向量上下文的大小
# min_count:词频阈值,词频低于该阈值的词将会被丢弃
# workers:并行训练的线程数
model = Word2Vec(sentences, window=5, min_count=1, workers=4)
# 获取所有词
# model.wv.index_to_key 用于获取词汇表
vacab = model.wv.index_to_key
# 获取所有词向量
vectors = model.wv[vacab]
# print(vectors)
# ====================
# 第二部分:《红楼梦》应用
# ====================
# 导入必要的包
import gensim # gensim包,用于训练词向量模型
import jieba # jieba分词库,用于对中文文本进行分词处理
import re # 正则表达式库
import numpy as np # numpy库,用于矩阵运算
from sklearn.decomposition import PCA # 主成分分析库,用于降维
from gensim.models import Word2Vec # gensim包中的Word2Vec模型
import matplotlib.pyplot as plt # 绘图库,用于可视化
import matplotlib
# 数据预处理
# 读取红楼梦文本
f = open(r'hongloumeng.txt', encoding='utf-8')
lines = []
for line in f:
# jieba.lcut()函数 用于对中文文本进行分词处理,返回一个列表
temp = jieba.lcut(line)
words = []
for i in temp:
# 正则表达式去除不必要符号
i = re.sub("[\s+\.\!\/_.$%^*(++\"\'“”《》]+|[+——!,。?、\
~·@#¥%……&* ( ) '------------';:‘]+", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)
print(lines[:3]) # 打印前3行分词结果
# 调用 Word2Vec 建议模型
# 采用参数
# vector_size:词向量维度
# window:上下文窗口长度
# min_count:少于该字段的次数的单词会被丢弃
# epochs:训练的轮数
# negative:负采样的数量
model = Word2Vec(lines, vector_size= 20, window = 3, min_count = 3, \
epochs = 7, negative= 10) #这里为了训练速度,对参数设置较低
# 输入一个路径,保存训练好的模型,这里保存在同目录下
model.save('word2vec_gensim')
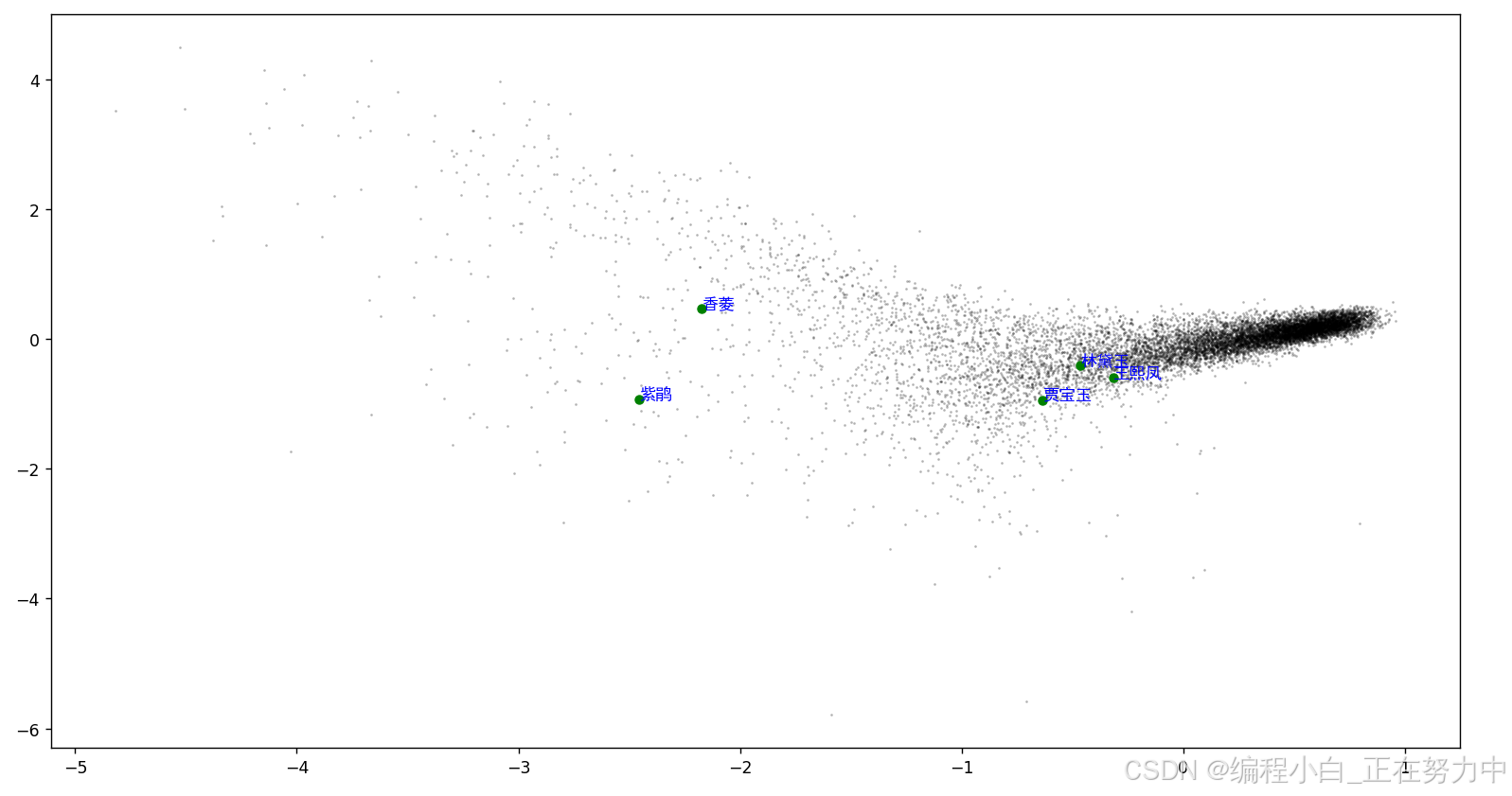
# 查看"林黛玉"的词向量
print(model.wv.get_vector('林黛玉'))
# 查看与"林黛玉"最相关的前10个词
# model.wv.most_similar()函数 用于获取与给定词最相关的词
# topn:返回的最相关的词的数量
print(model.wv.most_similar('林黛玉', topn=10))
# 查看"林黛玉"与"贾宝玉"的相似度
print(model.wv.similarity('林黛玉', '贾宝玉'))
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import matplotlib.font_manager as fm
def plot_word_vectors(model, words_to_plot):
rawWordVec = [] # 存放原始词向量
word2ind = {} # 词到索引的映射
for i, w in enumerate(model.wv.index_to_key):
rawWordVec.append(model.wv[w])
word2ind[w] = i
rawWordVec = np.array(rawWordVec) # 转换为numpy数组
# PCA(n_components=2) pca # 实例化PCA对象
# pca.fit(rawWordVec) # 训练PCA模型
X_reduced = PCA(n_components=2).fit_transform(rawWordVec) # 降维
fig = plt.figure(figsize=(16, 16)) # 实例化画布
ax = fig.gca() # 获取画布坐标轴
ax.set_facecolor('white') # 设置背景颜色
# 绘制词向量
ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize=1, alpha=0.3, color='black')
# 设置字体
try:
font_path = fm.findfont(fm.FontProperties(family=['SimHei']))
font = fm.FontProperties(fname=font_path, size=10)
except:
font = None
print("SimHei字体不存在")
for w in words_to_plot:
if w in word2ind:
# 获取词索引
ind = word2ind[w]
# 获取词向量
xy = X_reduced[ind]
# 绘制词向量
plt.plot(xy[0], xy[1], '.', alpha=1, color='green', markersize=10)
# 绘制词
plt.text(xy[0], xy[1], w, alpha=1, color='blue', fontproperties=font)
plt.show()
# 假设已经加载了词向量模型
# 这里需要根据实际情况加载模型,例如:
# from gensim.models import Word2Vec
# model = Word2Vec.load('your_model.bin')
words = ['紫鹃', '香菱', '王熙凤', '林黛玉', '贾宝玉']
plot_word_vectors(model, words)
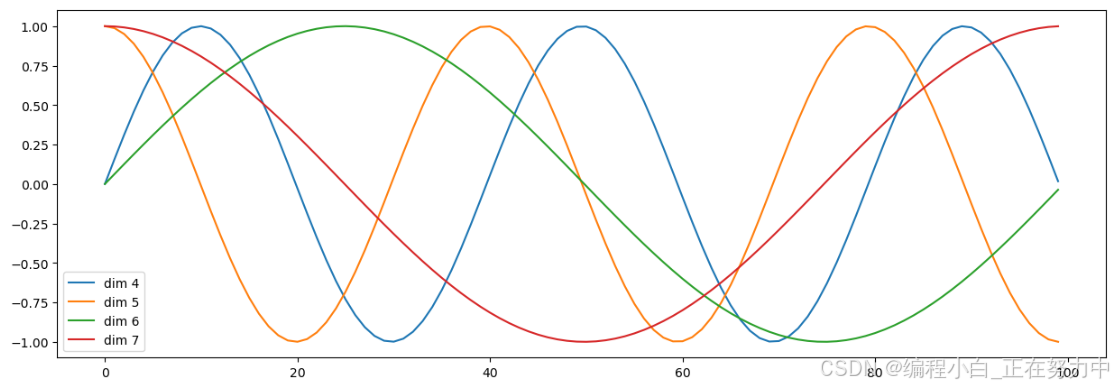
7. 相对位置向量代码实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import math
# 定义 PositionalEncoding 类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 创建一个足够长的位置编码张量,初始化为0
# max_len 是位置编码的最大长度,d_model 是编码的维度
self.encoding = torch.zeros(max_len, d_model)
# 创建位置张量,形状为 (max_len, 1)
position = torch.arange(0, max_len).unsqueeze(1)
# 计算正弦和余弦函数中的分母部分,形状为 (d_model // 2,)
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 计算正弦编码,并填充到偶数索引位置
self.encoding[:, 0::2] = torch.sin(position * div_term)
# 计算余弦编码,并填充到奇数索引位置
self.encoding[:, 1::2] = torch.cos(position * div_term)
# 增加一个批次维度,以便于广播操作
self.encoding = self.encoding.unsqueeze(0)
def forward(self, x):
# 将位置编码与输入张量相加
# x 的形状为 (batch_size, seq_len, d_model)
# 我们只取位置编码的前 seq_len 个位置
return x + self.encoding[:, :x.size(1)]
# 创建 PositionalEncoding 实例,设置编码维度为20,最大长度为100
pe = PositionalEncoding(20, max_len=100) # max_len 应该至少与输入序列长度相等
# 创建一个全零张量来模拟输入序列,形状为 (1, 100, 20)
# 这代表一个批次大小为1的序列,序列长度为100,编码维度为20
y = pe.forward(torch.zeros(1, 100, 20))
# 绘制位置编码
plt.figure(figsize=(15, 5))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" % p for p in [4, 5, 6, 7]])
plt.show()

















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









