







从ELMO说起的预训练语言模型
我们先来看一张图:
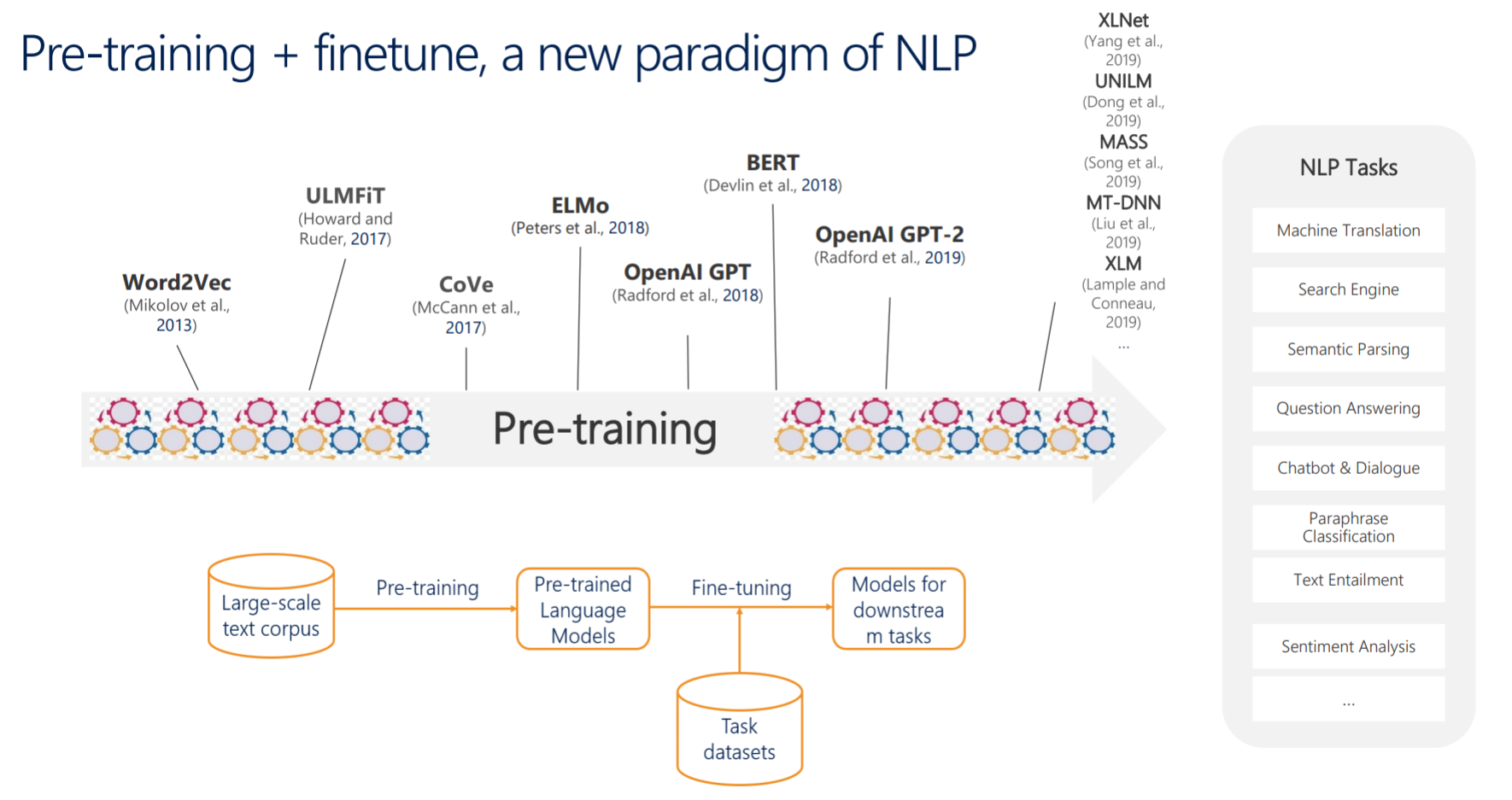
从图中可以看到,ELMO其实是NLP模型发展的一个转折点,从ELMO开始,Pre-training+finetune的模式开始崭露头角并逐渐流行起来。最初的ELMO也只是为了解决word2vec不能表达”一词多义“的问题提出来的,它所代表的动态词向量的思想更是被不少任务拿来借鉴。它最大的贡献还是提出的预训练+微调的模式,这种迁移学习的思想几乎是它作为NLP模型发展转折点的一个重要原因。
我们简单地看一下ELMO的模型结构(我加了红色标注便于直观理解):
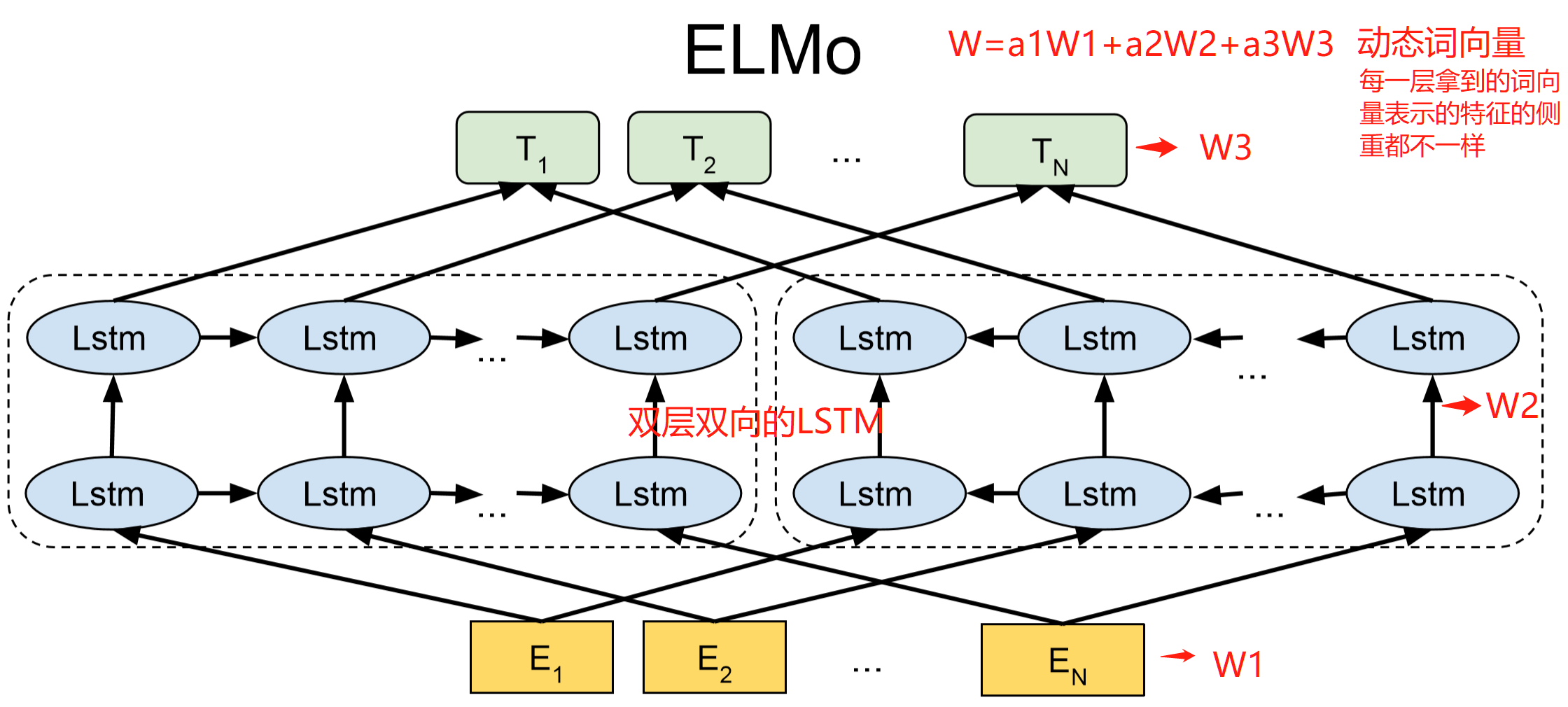
ELMO有一个很明显的特征就是它使用的是双层双向的LSTM,最后网络会产生一个动态词向量,它来自于不同的层输出的组合,由于不同层学习到的特征不一样,最后通过权重的调整向量表征的含义侧重点也不一样。与CV中的模型类似,越靠近输入层的层级学习到的特征越简单,比如W1可能是一些词性或字的特征;越靠近输出层的层级学习到的特征越高级,比如W3可能就是学习到一些句子级的特征。动态词向量偏重于哪一层取决于下游的任务,举个例子,序列标注任务多偏重于底层级一般效果就会更好一点。
ELMO在预训练阶段得到的网络参数再拿到具体任务中进行微调,这种迁移学习的思想大大降低了一些任务对大数据量的依赖性,在节约成本的同时效果也很不错,这为后面的BERT的出现铺平了道路,也慢慢引领了一个时代的潮流。
ELMO的缺点在其他文章中也有提及:ELMO 使用了 LSTM ,特征提取能力没有Transformer好;ELMO采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱。但这都是事后视角了,了解即可。
BERT详解
BERT的总体结构
先来看看BERT的结构框架:
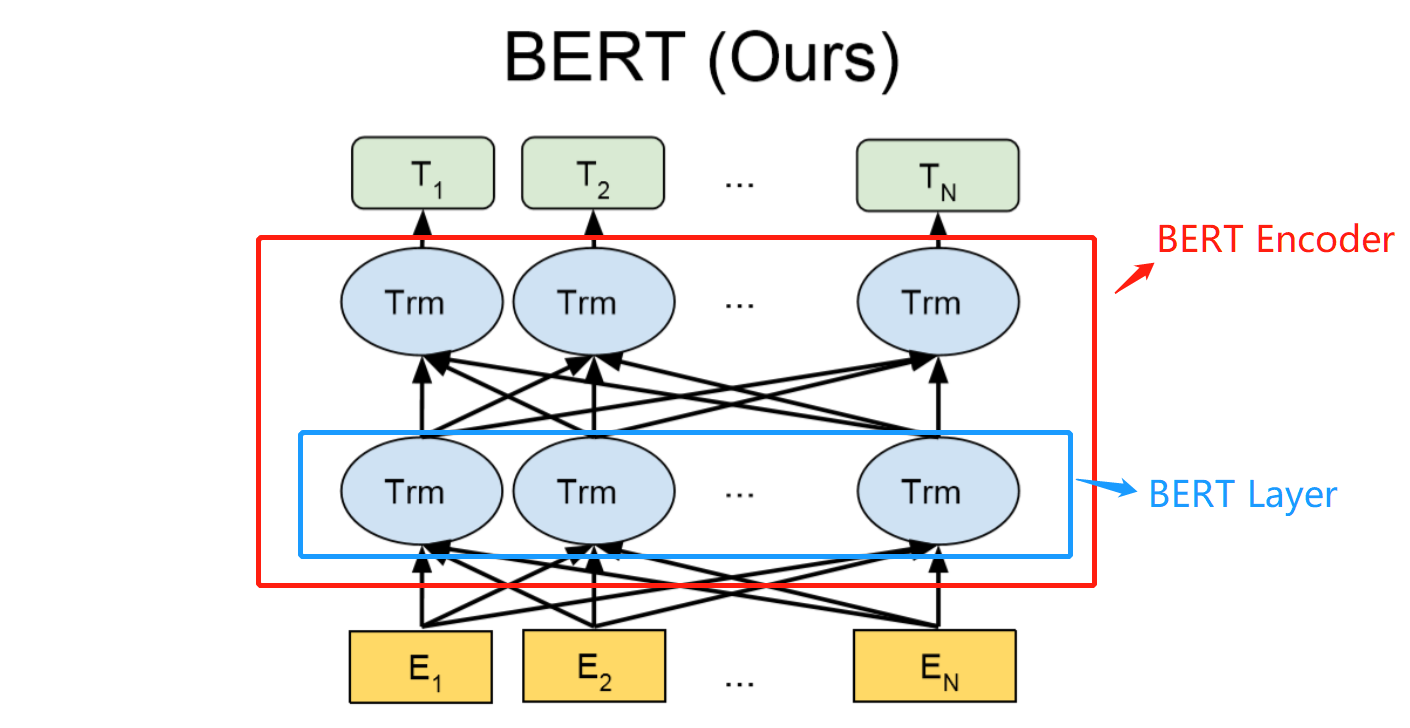
上面就是BERT的模型结构图了,是不是和ELMO长的有点像,模型的核心由BERT Encoder组成,BERT Encoder由多层BERT Layer组成,每一层的BERT Layer其实都是Transformer中的Encoder Block。再来回顾一下图:
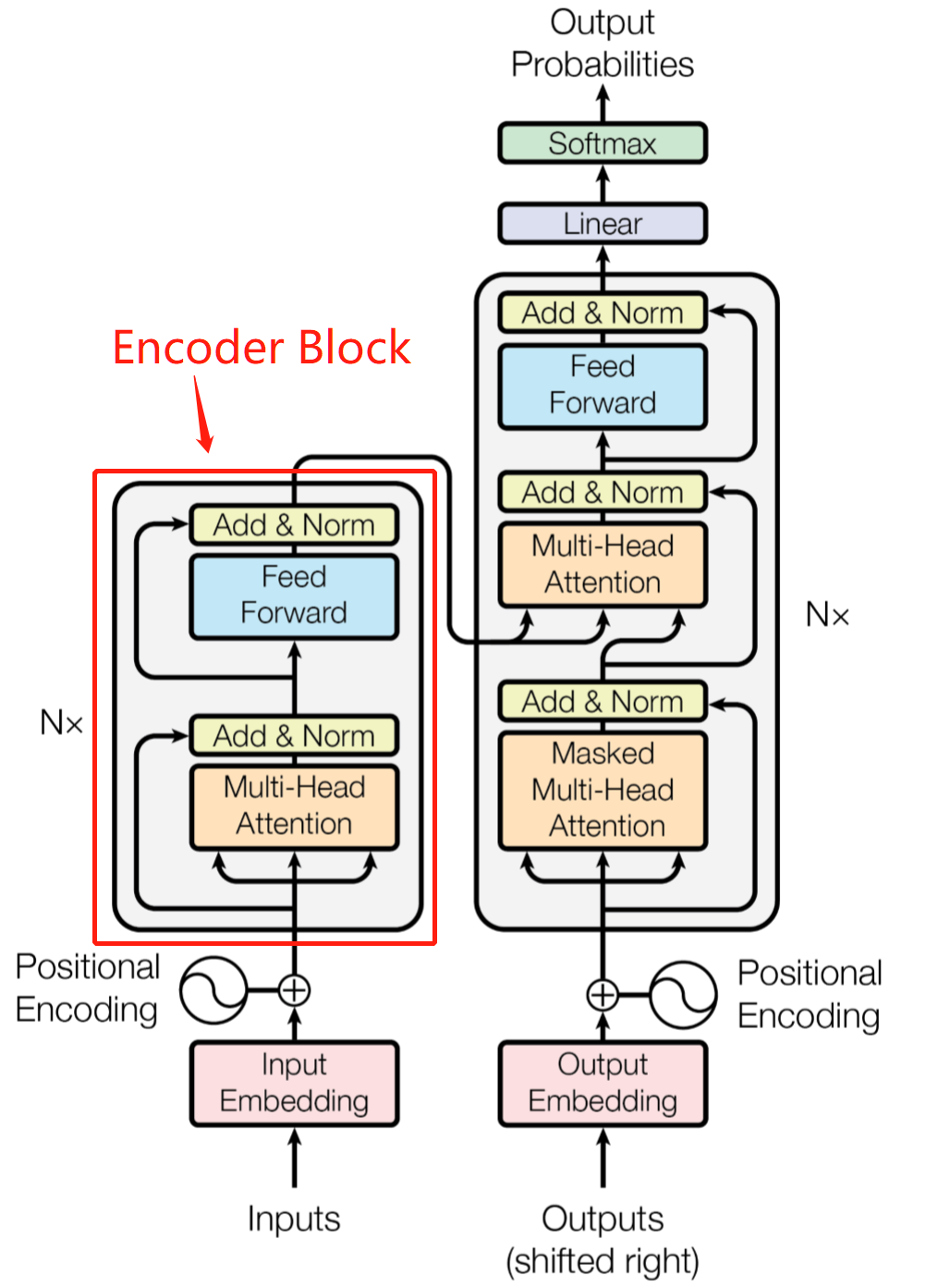
说到这里其实我们就已经了解到了BERT的一个大体形貌了,对于Transformer中的Encoder Block有点生疏的话可以再去回顾一下:Transformer 看这一篇就够了,相信可以回忆起来的。
由于BERT使用的是Transformer中的Encoder Block,所以其本质还是一个特征提取器,只不过由于网络较深和Self-Attention机制的帮衬,它的特征提取/模型学习能力更强。也正是由于它只是Encoder的缘故,所以BERT也不具备生成能力,没法单独用BERT来解决NLG的问题,只能解决NLU的问题。
BERT的输入
还是老规矩,对着图说:

如图所示,BERT模型输入的Embedding由Token Embeddings、Segment Embeddings和Position Embeddings相加而成,如下图。我们分别来看一下这三部分:
- Token Embeddings:最传统的词向量,与之前我们一起学习的语言模型的输入一样,它是将token嵌入到一个高维空间中表示的结果。对这一部分的Embeddings,有几点需要注意:
token的选取与之前的Transformer不太一样,在这里采用的一种新的token形式,是一种子词粒度的表现形式,称之为subword。说的大白话一点就是中文还是字符级别的token,英文不再按照传统的空格分词,而是将部分单词再拆分成字根的形式,比如playing拆成play+ing。这样做最大的好处就是字典变小了,计算量也变小了,同时也在一定程度上解决了OOV的问题。
常用的subword的方法可参见:深入理解NLP Subword算法:BPE、WordPiece、UL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









