







transfomer学习引言 | 大白话讲解Seq2Seq、Encoder-Decoder、Attention、词嵌入
前言
今天开始学习DataWhale组队学习fun-transformer,今天学习task1引言部分!
【教程地址】
【开源地址】
对于我这种小白,一些专业术语不熟悉,需要来回查询,特此先汇总一波:
专业术语
-
Seq2Seq:序列到序列模型,目标是将一个序列转换成另一个序列。
-
Encoder-Decoder:编码器-解码器模型,是实现 Seq2Seq 的一种架构。
-
上下文向量:编码器生成的固定长度的向量,用于传递输入序列的关键信息。
-
编码器(Encoder):负责将输入序列转换为上下文向量。
-
解码器(Decoder):负责利用上下文向量生成输出序列。
-
上下文向量(Context Vector):编码器生成的固定长度的向量,用于传递输入序列的关键信息。
-
注意力机制(Attention Mechanism):一种机制,允许解码器在生成每个输出时动态关注输入序列的不同部分。
-
循环神经网络(RNN):一种能够处理序列数据的神经网络,具有记忆功能。
-
长短期记忆网络(LSTM):一种改进的 RNN,能够更好地处理长序列数据。
-
门控循环单元(GRU):一种简化版的 LSTM,性能接近但计算更高效。
-
Attention:注意力机制,一种让模型能够动态关注重要信息的技术。
-
Transformer:一种基于自注意力机制的模型架构,用于处理序列数据。
-
多头注意力(Multi-head Attention):一种注意力机制的扩展,允许模型从多个角度关注信息。
-
BERT:一种基于 Transformer 的预训练语言模型,广泛应用于自然语言处理任务。
1. 序列到序列(Seq2Seq)模型概述
1.1 什么是Seq2Seq模型?
就像它的名字"序列到序列",吃进去一串东西(比如中文句子),吐出来另一串东西(比如英文句子)。最厉害的是输入和输出的长度可以不一样。比如输入5个字的中文,可能输出4个英文单词。
这里有两个特殊符号:
- 开头符
<bos>:像发令枪"砰"的一声,告诉模型"要开始说话了" - 结束符
<eos>:像裁判吹哨"哔——“,表示"我说完了”
比如:<bos>我有钢笔<eos>,模型看到这个就知道从哪开始处理,到哪结束。
学习遇到的问题:
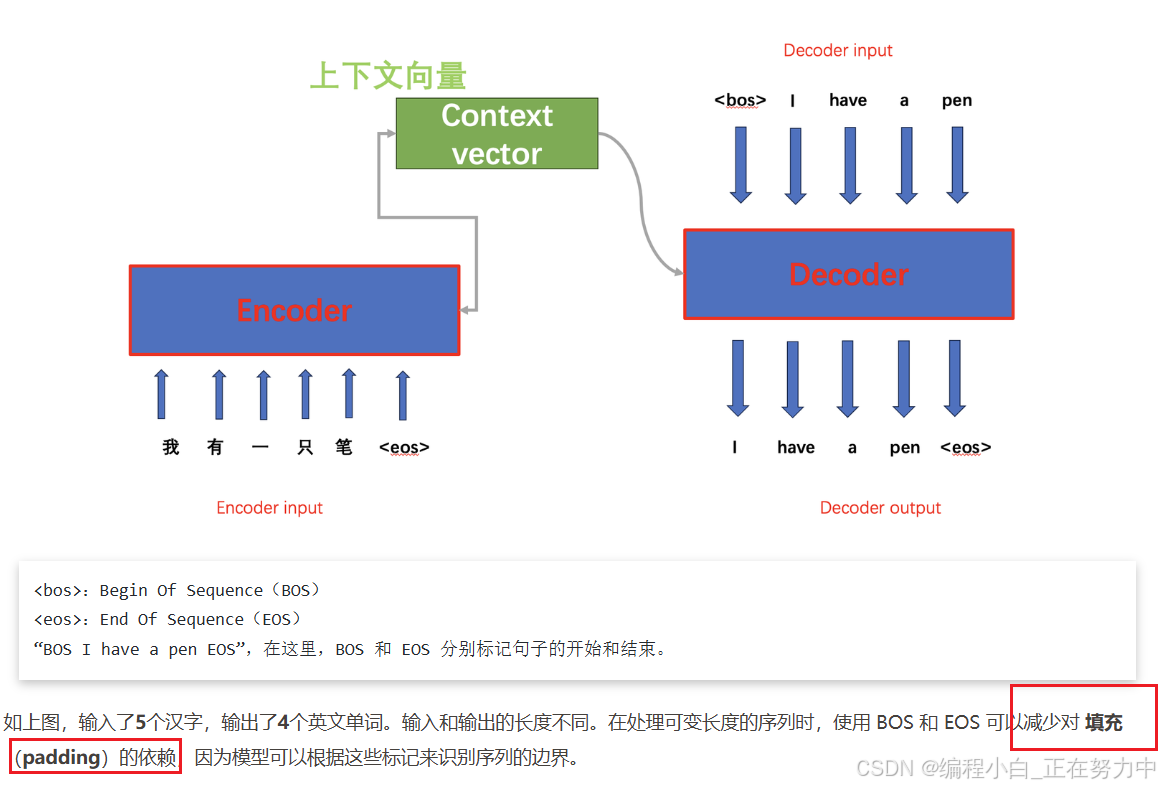
“可以减少对填充(padding)的依赖”:在处理不同长度的序列时,如果没有 BOS 和 EOS 标记,通常需要对较短的序列进行填充(padding),使其长度与最长的序列一致,这样模型才能统一处理。填充(padding)就是用一些无关的、占位的符号来填充较短的序列,让所有序列看起来长度一样。但填充可能会引入一些噪声,影响模型的性能。而使用 BOS 和 EOS 标记后,模型可以根据这些标记来识别序列的边界,知道序列是从哪里开始的,到哪里结束的,就不需要再依赖填充(padding)来统一序列长度了。
1.2 为什么要发明它?
以前的AI模型像死板的书呆子,必须把信息剪裁成固定长度才能处理。比如把3个词的句子硬凑成5个词,塞两个零占位:[1,2,3]变成[1,2,3,0,0]。但这样有两个问题:
- 处理时要专门忽略这些凑数的零
- 现实中的翻译/对话等内容,根本没法提前知道要多长
于是2013年左右,研究者们搞出了这个能"自由伸缩"的模型,像给AI装了弹簧鞋,让它能处理各种长短不一的句子。
1.3 这个模型有多厉害?
- 全自动学习:像智能厨房一体机,直接把生米(原始数据)倒进去,出来就是熟饭(翻译结果),不用人工洗米(特征工程)
- 记忆胶囊:编码器把整段话压缩成一个"精华胶囊"(上下文向量),解码器再把这个胶囊还原成目标语言,就像把长篇小说压缩成梗概再扩写
- 变形金刚体质:能和其他AI组件(如CNN、RNN)自由组合,像乐高积木一样拼出不同功能
- 长短通吃:不管输入是"你好"还是《战争与和平》那么长,都能处理
1.4 有什么短板?
- 记忆超载:就像要把《辞海》内容塞进小U盘,长文章的重要细节可能在压缩时丢失
- 金鱼脑:处理超长内容时,记不住开头说了啥(像我们看长电影中途走神)
- 考试作弊:训练时老师总给答案提示(teacher forcing),但实际应用时要自己发挥,容易出错(像平时开卷考的学生突然参加闭卷考试)
学习中的疑问:
“teacher forcing”直译为“教师强制”或“教师强迫”,在神经网络领域,特别是序列到序列(Seq2Seq)模型训练中,这是一种常用的训练策略。其核心思想是在模型训练的每个时间步上,不使用模型自身预测的输出作为下一个时间步的输入,而是直接将真实的目标输出(即训练数据集中正确的答案)强制提供给解码器,作为下一个时间步的输入。这种做法可以加速模型的训练过程,帮助模型更快地学习到从输入序列到目标序列的映射关系,因为它直接利用了正确的答案来指导模型的学习,减少了模型在训练过程中因自身错误预测而产生的偏差积累。
大白话理解“teacher forcing”:“teacher forcing”就好像是在教小孩学说话。假设你想教小孩说“早上好,我今天很开心”,正常情况下,小孩可能会先说“早上好”,然后自己想下一步该说什么。但如果用“teacher forcing”,就是直接把正确答案“早上好”、“我今天很开心”一句一句地喂给小孩,让他直接跟着学,而不是让他自己去猜。这样小孩学起来会更快,因为每次都是跟着正确的答案学,不会走弯路。
举个栗子:
想象你在同声传译,听到中文后要立刻翻译成英文。Seq2Seq就像个超级翻译员,但有时候遇到超长难句,可能记不住前半句的细节(信息丢失),或者因为平时训练总看参考答案,实战时自己翻译会卡壳。不过它最大的本事是能灵活处理各种长度的句子,这点传统翻译员可比不了。
2. Encoder-Decoder模型
2.1 Seq2Seq 和 Encoder-Decoder 的关系
Seq2Seq 模型的目标是将一个序列转换为另一个序列,例如将中文翻译成英文,或者将一段文字总结成摘要。这就像你试图将一个故事讲述给不懂中文的朋友听,但需要用英文来表达,这就是 Seq2Seq 的任务。
而 Encoder-Decoder 是实现这一目标的方法,就像烹饪时使用的食谱。该方法分为两个步骤:编码器(Encoder)和解码器(Decoder)。编码器的任务是将输入的内容(如一段中文)转化为一个“小本子”,其中记录了内容的关键信息。解码器则利用这个“小本子”将内容翻译成英文,讲给朋友听。
Seq2Seq 是 Encoder-Decoder 的一种应用,就像将一段文字翻译成另一种语言是 Seq2Seq 的目标,而 Encoder-Decoder 是实现这一目标的方法。无论输入和输出的长度如何,编码器和解码器之间传递的“小本子”(上下文向量)的大小是固定的。这就像用一个固定大小的盒子装东西,如果东西太多,就装不下,这是它的一个缺点。不过,你可以使用不同的工具(如 RNN、LSTM 或 GRU)来构建编码器和解码器,只要符合这个框架即可。
2.2 Encoder-Decoder 的工作流程
2.2.1 编码器(Encoder)
编码器就像一个“记笔记”的机器。它逐字逐句地处理输入内容(如句子),并将重要信息记录下来。这个过程分为三步:
-
词序列转换:
将输入内容中的每个词转换为一个“向量”,这个向量就像是词的“身份证”,能够代表这个词的含义。例如,“猫”这个词的向量可能表示它是一种会喵喵叫的动物。 -
序列处理:
使用循环神经网络(RNN)处理这些向量。RNN 就像一个具有记忆功能的小机器,它在处理当前词的同时,还能记住前面的词,从而理解整个句子的含义。例如,当它看到“猫”这个词时,还会记得前面的词是“一只”,从而理解“一只猫”这个短语的意思。 -
生成上下文向量:
RNN 将整个句子的信息总结成一个“小本子”(上下文向量),这个“小本子”就是解码器要使用的关键信息。它记录了句子的主题、情感等重要内容。
2.2.2 解码器(Decoder)
解码器的任务是利用编码器提供的“小本子”生成新的内容。它的工作流程如下:
-
初始化参数:
为解码器的大脑(RNN)和输出层设置初始参数,这些参数是学习的起点。 -
编码器输出:
编码器将“小本子”(上下文向量)传递给解码器,解码器利用这个“小本子”开始生成新的内容。 -
解码器输入:
- 初始隐藏状态:解码器使用“小本子”初始化自己的状态。
- 开始符号:解码器需要一个信号来开始生成,例如一个“开始”标记。
- 输入序列:在生成过程中,解码器的输入是上一步生成的内容。
- 上下文向量:解码器每次生成新内容时都会参考“小本子”。
- 注意力权重:如果使用了注意力机制,解码器会根据“小本子”中哪些部分更重要来生成内容。
-
遇到的问题:

Xavier初始化
- 定义:Xavier初始化是一种参数初始化方法,它根据输入和输出的维度来确定权重的初始值。具体来说,它假设权重是从一个均值为0、方差为 2 n in + n out \frac{2}{n_{\text{in}} + n_{\text{out}}} nin+nout2 的分布中随机抽取的,其中 n in 和 n out n_{\text{in}}和n_{\text{out}} nin和nout分别是输入和输出的维度。
- 适用场景:Xavier初始化适用于Sigmoid或Tanh激活函数。这是因为Sigmoid和Tanh函数的输出范围分别是(0,1)和(-1,1),它们对输入的非线性变换较为平滑,但容易受到输入值的大小影响。如果权重初始化过大或过小,会导致激活函数的梯度消失或爆炸,从而影响训练过程。
- 作用:Xavier初始化通过合理地设置权重的初始值,使得每一层的输入和输出的方差保持一致,从而维持各层激活值和梯度的大致稳定性。这有助于优化训练过程,使网络能够更有效地学习。
He初始化
- 定义:He初始化是另一种参数初始化方法,它假设权重是从一个均值为0、方差为 2 n in \frac{2}{n_{\text{in}}} nin2的分布中随机抽取的,其中 n in n_{\text{in}} nin是输入的维度。这种初始化方法是针对ReLU激活函数设计的。
- 适用场景:He初始化通常用于ReLU激活函数。ReLU函数的输出范围是[0, +∞),它对输入的非线性变换较为简单,但容易受到输入值的大小影响。如果权重初始化过大,会导致激活函数的梯度爆炸,从而影响训练过程。
- 作用:He初始化通过合理地设置权重的初始值,使得每一层的输入和输出的方差保持一致,从而维持各层激活值和梯度的大致稳定性。这有助于优化训练过程,使网络能够更有效地学习。
“Sigmoid或Tanh激活函数”指的是两种在神经网络等领域常用的激活函数。Sigmoid激活函数的数学表达式为 σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1 ,其输出值在0到1之间,呈现S形曲线,能够将输入映射到一个概率值的范围,常用于二分类问题的输出层。Tanh激活函数的表达式为 tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} tanh(x)=ex+e−xex−e−x,其输出值在-1到1之间,也是S形曲线,相比Sigmoid函数,它以0为中心,对称性更好,有助于提高神经网络的训练效率,通常用于隐藏层。
“ReLU激活函数”是一种在神经网络中常用的激活函数,其全称为“Rectified Linear Unit”,即修正线性单元。它的工作原理是:当输入值大于零时,输出等于输入;当输入值小于等于零时,输出为零。这种激活函数的优点包括计算简单、能够缓解梯度消失问题等,有助于加快神经网络的训练速度并提高模型性能。
2.2.3 Seq2Seq 模型的训练过程
训练 Seq2Seq 模型就像教一个学生复述故事:
-
准备数据:
将故事内容转化为学生能理解的词汇,并将其分成小段,方便学生学习。 -
初始化模型参数:
为学生的大脑和输出层设置初始学习参数。 -
编码器处理:
向学生讲述故事,让他们记下要点(生成上下文向量)。 -
解码器训练过程:
- 初始化隐藏状态:学生在复述前先查看记下的要点。
- 时间步迭代:学生根据开头标记开始复述,并根据记忆继续。
- 损失计算:比较学生复述的内容与原始故事,找出差异。
- 反向传播和参数更新:根据反馈调整学生的学习方法。
-
循环训练:
学生反复练习,直到能够熟练复述故事。 -
学习中遇到的问题:

多个epoch是指在机器学习或深度学习的训练过程中,数据集被多次完整地遍历以进行模型训练。一个epoch表示整个数据集被训练模型使用一次。例如,如果训练数据集有1000个样本,模型在每个epoch中会看到这1000个样本一次。进行多个epoch训练意味着模型会多次看到这些样本,目的是让模型更好地学习数据中的模式和特征,从而提高模型的性能。
“梯度裁剪(Gradient Clipping)”是一种在神经网络训练过程中,用于控制梯度大小的技术。在训练神经网络时,通过反向传播算法计算损失函数关于网络参数的梯度,然后利用这些梯度来更新网络参数。然而,在某些情况下,梯度可能会变得非常大,导致网络参数更新的幅度过大,从而使网络训练过程变得不稳定,甚至出现梯度爆炸(Gradient Explosion)的问题。梯度爆炸是指梯度值在反向传播过程中不断累积放大,最终导致数值溢出或网络参数更新失控的现象。
为了解决这个问题,梯度裁剪技术应运而生。其基本思想是,在每次参数更新之前,对计算得到的梯度进行检查和调整。如果梯度的大小(通常用梯度的范数来衡量)超过了预设的阈值,就将梯度按比例缩放,使其大小不超过该阈值。这样可以有效地限制梯度的最大值,避免梯度过大对网络训练造成不利影响,从而保证训练过程的稳定性和收敛性。
例如,在训练一个深度循环神经网络(RNN)时,由于RNN具有时间上的递归结构,梯度在时间序列上不断累积,很容易出现梯度爆炸的问题。此时,通过应用梯度裁剪技术,可以对每个时间步计算得到的梯度进行裁剪,确保梯度在合理的范围内,从而使网络能够稳定地学习到数据中的模式和规律,提高模型的性能和泛化能力。
大白话理解:
梯度裁剪就像是给梯度“剪指甲”。
在训练神经网络的时候,我们需要通过计算梯度来调整网络的参数,让网络变得更好。但是,有时候梯度会变得特别大,就像指甲长得太长一样,可能会把事情搞砸(比如让网络的参数更新得太大,导致训练不稳定,甚至直接“爆炸”)。
为了避免这种情况,我们就用梯度裁剪来“剪短”这些过大的梯度。具体来说,我们设定一个“长度”上限(阈值),如果梯度超过了这个上限,我们就把它按比例缩小,让它回到合理的范围内。这样,梯度就不会太大,网络的训练就能更稳定地进行。
简单来说,梯度裁剪就是一种“防过头”的技术,让梯度保持在一个合理的范围内,避免因为梯度过大而让训练出问题。
2.2.4 小故事讲解
想象你有一支翻译笔,它的工作原理如下:
- 编码器:翻译笔先逐字逐句地读取你输入的句子,并将重要信息记录在一个“小本子”(上下文向量)中。
- 解码器:翻译笔根据这个“小本子”开始生成新的句子,从第一个词开始,一边猜测一边生成,直到句子结束。
2.3 Encoder-Decoder 的应用
Encoder-Decoder 模型可以应用于以下场景:
- 机器翻译:将一种语言翻译成另一种语言。
- 对话机器人:根据输入的问题生成回答。
- 诗词生成:根据输入的内容生成诗词。
- 代码补全:根据代码的一部分生成剩余部分。
- 文章摘要:将长文章压缩成短摘要。
- 语音识别:将语音转换为文字。
- 图像描述生成:根据图片生成描述文字。
2.4 Encoder-Decoder 的缺陷
Encoder-Decoder 模型的一个主要缺点是“小本子”(上下文向量)的大小是固定的。如果输入内容过长,就像将一幅大画压缩到一个小盒子里,某些细节可能会丢失,从而导致生成的内容不够准确。
3. Attention 的提出与影响
3.1 Attention 的发展历程
| 时间 | 发展 | 描述 |
|---|---|---|
| 早期 | 循环神经网络(RNNs) 长短期记忆网络(LSTMs) | RNNs 能处理变长的序列数据,但长序列时容易“健忘”或“爆炸”。LSTMs 是升级版,加了“门”来控制信息流动,解决了“健忘”的问题。 |
| 2014年 | Seq2Seq模型的提出 | Seq2Seq 模型就像一个接力棒,编码器把信息编码成一个“小本子”,解码器拿着“小本子”去生成新内容。这个模型在机器翻译上很成功。 |
| 2015年 | 注意力机制的引入 | 在 Seq2Seq 的基础上,加入了“注意力”功能,让解码器可以根据需要去“看”编码器的不同部分,不再是死板地依赖一个“小本子”。 |
| 2017年 | 自注意力与Transformer模型 | Transformer 模型完全抛弃了传统的循环结构,用“自注意力”机制来处理序列,处理长距离信息时表现特别棒。 |
| 2018年 | 多头注意力与BERT | Transformer 进一步升级为多头注意力,就像一个人有多个脑袋,可以从不同角度关注信息。BERT 就是基于这个机制,成了 NLP 领域的“学霸”。 |
3.2 Attention 的 N 种类型
| 计算区域 | 所用信息 | 使用模型 | 权值计算方式 | 模型结构 |
|---|---|---|---|---|
| 1. Soft Attention (Global Attention) | 1. General Attention | 1. CNN + Attention | 1. 点乘算法 | 1. One-Head Attention |
| 2. Local Attention | 2. Self Attention | 2. RNN + Attention | 2. 矩阵相乘 | 2. Multi-layer Attention |
| 3. Hard Attention | 3. LSTM + Attention | 3. Cos 相似度 | 3. Multi-head Attention | |
| 4. Pure-Attention | 4. 串联方式 | |||
| 5. 多层感知 |
3.3 Attention 解决信息丢失问题
Attention 模型的特点是编码器不再把输入序列变成一个固定的“小本子”,而是变成一系列的“小卡片”(Context vector 序列)。这样,解码器在生成每个输出时,都可以根据需要去“看”这些“小卡片”,解决了“信息太长,容易丢掉”的问题。
3.4 Attention 的核心工作
Attention 的核心工作就是“挑重点”。就像你在一堆信息里找关键线索一样,Attention 机制能快速从大量信息中找出对解决问题最重要的部分。比如你看一张熊猫的图片,你的目光会自然地集中在熊猫身上,而不是背景的树叶。这就是 Attention 机制在做的事情——把有限的注意力集中在关键信息上,节省资源,快速找到最重要的东西。
3.5 Attention 的 3 大优点
引入 Attention 机制主要有 3 个好处:
- 参数少:Attention 模型比 CNN 和 RNN 更简单,参数更少,对算力要求也更低。
- 速度快:Attention 机制可以并行计算,不像 RNN 那样必须一步步来,所以处理速度更快。
- 效果好:Attention 机制解决了长距离信息容易丢失的问题,就像记忆力变强了,能记住更久远的事情。
低维映射到高维:词嵌入的通俗讲解
1. 什么是词嵌入?
想象一下,你有一堆玩具,每个玩具都有自己的名字,比如“小猫”“小狗”“小汽车”“小飞机”。如果你只是简单地给每个玩具贴上一个数字标签(比如“小猫”=1,“小狗”=2),别人可能很难理解这些数字到底代表什么,更别提知道这些玩具之间的关系了。
词嵌入就是一种“魔法”,它可以把这些玩具的名字变成一组数字,这些数字不仅能让计算机理解,还能体现出玩具之间的关系。比如,“小猫”和“小狗”都是动物,它们的数字可能就很接近;而“小汽车”和“小飞机”虽然都是交通工具,但和动物的数字就会比较远。
2. 词嵌入的例子
假设我们有一个简单的词汇表,里面有四个词:“猫”“狗”“爱”“跑”。在词嵌入之前,这些词可能只是用数字索引来表示,比如:
- “猫” = 0
- “狗” = 1
- “爱” = 2
- “跑” = 3
这种表示方式就像给玩具贴数字标签一样,没有体现出词的意思。
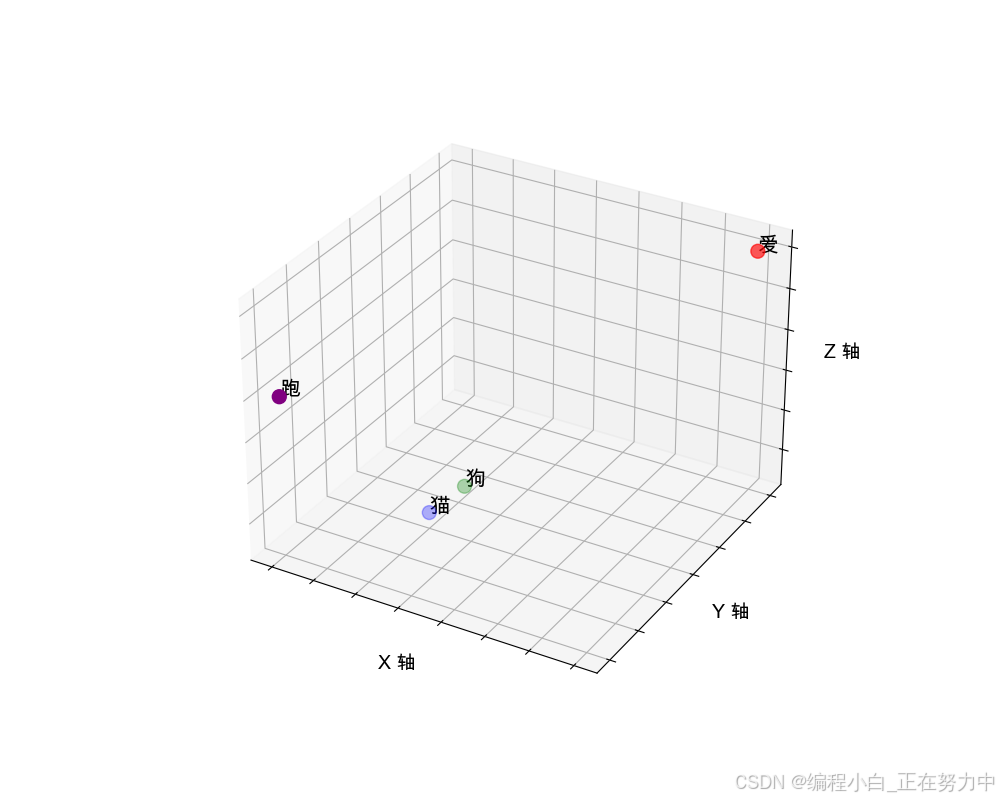
现在,我们用词嵌入把它们变成一组数字(向量),假设我们用三维空间来表示(实际中通常是更高维度的,这里为了简单用三维):
- “猫” = [0.3, 0.4, 0.25]
- “狗” = [0.35, 0.45, 0.3]
- “爱” = [0.8, 0.8, 0.8]
- “跑” = [0.1, 0.2, 0.6]
这些数字就像是每个词在“魔法空间”里的位置。比如,“猫”和“狗”在语义上比较接近(都是动物),它们的数字位置也比较接近;而“爱”和“跑”在语义上和“猫”“狗”差别很大,它们的位置就会比较远。
3. 词嵌入的作用
这种用数字向量表示词的方式有个好处,就是可以通过计算向量之间的距离或角度来判断词之间的关系。比如,“猫”和“狗”的向量距离比“猫”和“爱”的向量距离更近,这就说明“猫”和“狗”在意思上更相似。
4. 用代码画出词嵌入的三维图
我们用 Python 来画一个图,看看这些词在三维空间里的位置关系:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # matplotlib字体显示
from mpl_toolkits.mplot3d import Axes3D
# 定义词汇及其对应的三维向量
words = ["猫", "狗", "爱", "跑"]
vectors = [[0.3, 0.4, 0.25], [0.35, 0.45, 0.3], [0.8, 0.8, 0.8], [0.1, 0.2, 0.6]]
# 将嵌套列表转换为numpy数组
vectors = np.array(vectors)
# 创建3D图形
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
# 为每个词汇及其向量绘图
scatter = ax.scatter(vectors[:, 0], vectors[:, 1], vectors[:, 2],
c=['blue', 'green', 'red', 'purple'], s=100)
# 为每个点添加标签
for i, word in enumerate(words):
ax.text(vectors[i, 0], vectors[i, 1], vectors[i, 2], word, size=15, zorder=1)
# 设置图形属性
ax.set_xlabel('X 轴', fontsize=14)
ax.set_ylabel('Y 轴', fontsize=14)
ax.set_zlabel('Z 轴', fontsize=14)
# 移除坐标轴的数字标签
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_zticklabels([])
# 设置背景颜色和网格线
ax.set_facecolor('white')
ax.grid(True)
# 显示图形
plt.show()
5. 词嵌入的实际应用
词嵌入在自然语言处理中有着广泛的应用,比如:
- 文本分类:通过词嵌入,计算机可以理解文本的主题或情感。
- 机器翻译:词嵌入帮助模型理解不同语言之间的语义关系。
- 问答系统:通过词嵌入,系统可以更好地理解用户的问题并找到相关答案。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









