







Transformer | 大白话讲解Decoder
- 1. 解码器(Decoder)
- 2. 掩码(Mask)
- 3. Decoder在不同阶段的信息传递机制
- 4. 模型的训练与评估
- 5. 高级主题和应用
- Tokenization
- apply-gpt代码实现
- apply-bert 代码实现
1. 解码器(Decoder)
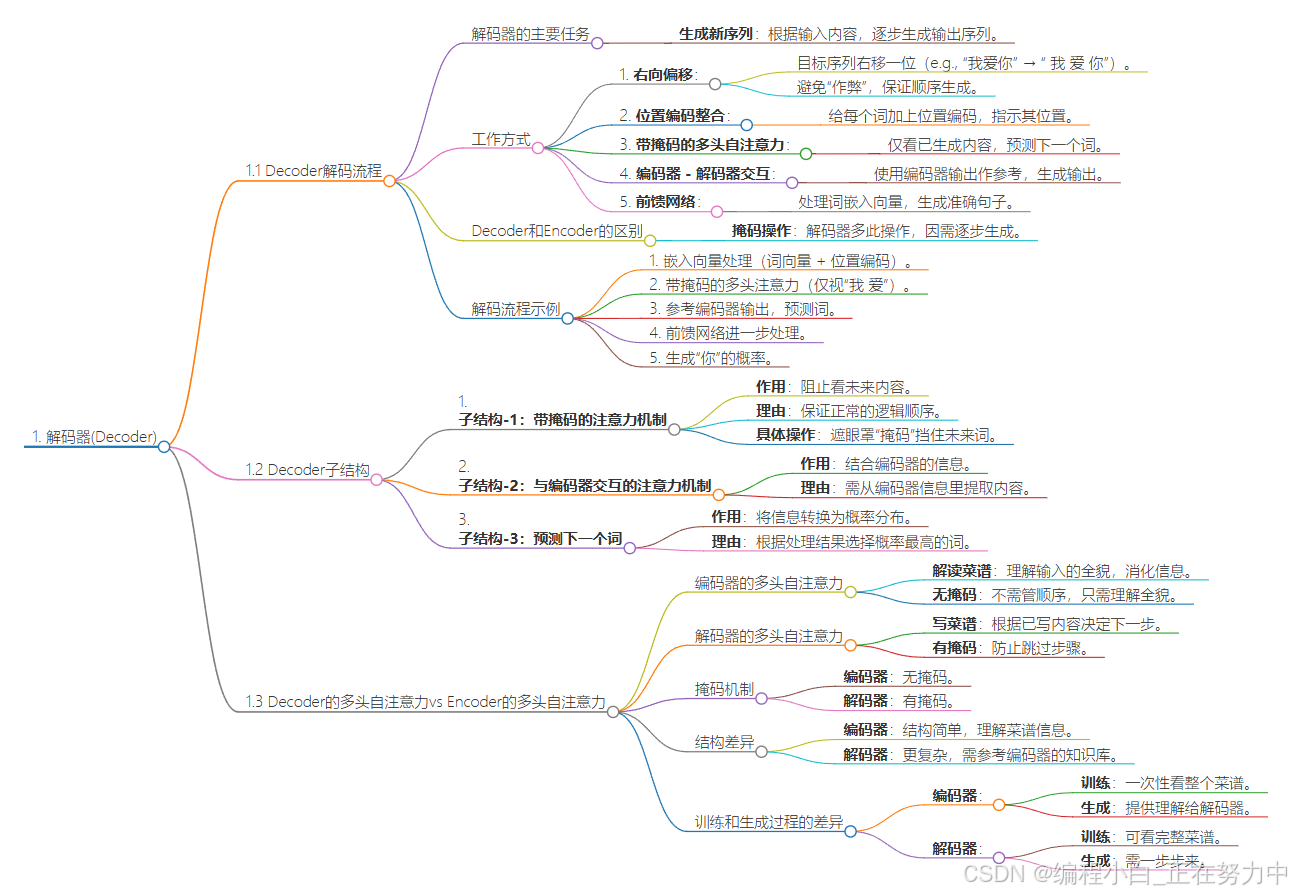
1.1 Decoder解码流程
解码器的目的是什么?
解码器的主要任务是根据输入的内容(比如一句话或者一段文字),生成一个新的输出序列(比如翻译后的句子或者生成的回复)。它的工作方式是逐步生成的,每次生成一个词,直到生成完整的句子。
解码器是怎么工作的?
-
输出嵌入的右向偏移
解码器在开始工作之前,会把目标序列(也就是它要生成的句子)向右移动一个位置。比如,目标句子是“我爱你”,它会变成“ 我 爱 你”。为什么要这么做呢?因为解码器是逐步生成句子的,每次只能看到之前生成的内容,不能“作弊”看到后面的内容。这样就能保证生成的句子是按照顺序一步步来的。 -
位置编码的整合
解码器还要给每个词加上一个“位置编码”,这个编码的作用是告诉模型这个词在句子中的位置。比如,“我”在第一个位置,“爱”在第二个位置。这样模型就能知道词的顺序,而不仅仅是词本身。 -
带掩码的多头自注意力机制
解码器用一种特殊的注意力机制(带掩码的多头注意力),它的作用是让模型在生成每个词的时候,只能看到之前生成的词,而看不到后面的词。比如,当生成“爱”的时候,它只能看到“ 我”,不能看到“你”。这个“掩码”就是用来挡住后面的词的。 -
编码器-解码器注意力交互
解码器还会和编码器(处理输入内容的部分)进行交互。它会用编码器的输出(也就是输入内容的编码)来帮助自己生成输出。比如,输入是“你爱我”,解码器会根据这个输入的编码,结合自己已经生成的内容,来决定下一步生成什么词。 -
基于位置的前馈网络
最后,解码器还会用一个前馈网络来进一步处理每个词的嵌入向量。这个网络的作用是帮助模型更好地理解词之间的关系,从而生成更准确的句子。
Decoder和Encoder的区别
解码器和编码器的结构差不多,但解码器多了一个“掩码”的操作。这是因为解码器是逐步生成句子的,不能看到未来的内容,所以需要用掩码来挡住后面的词。而编码器处理输入的时候,可以一次性看到整个句子,所以不需要掩码。
解码时的具体流程
假设解码器已经生成了“我 爱”,下一步要生成“你”。它的流程是这样的:
- 把“我 爱”变成嵌入向量(加上词向量和位置编码)。
- 用带掩码的多头注意力处理这些向量,确保只能看到“我 爱”。
- 把编码器的输出(输入句子的编码)作为参考,结合前面的结果,决定下一步生成什么词。
- 再通过前馈网络进一步处理,最后生成“你”的概率。
- 重复这个过程,直到生成完整的句子。
1.2 Decoder子结构
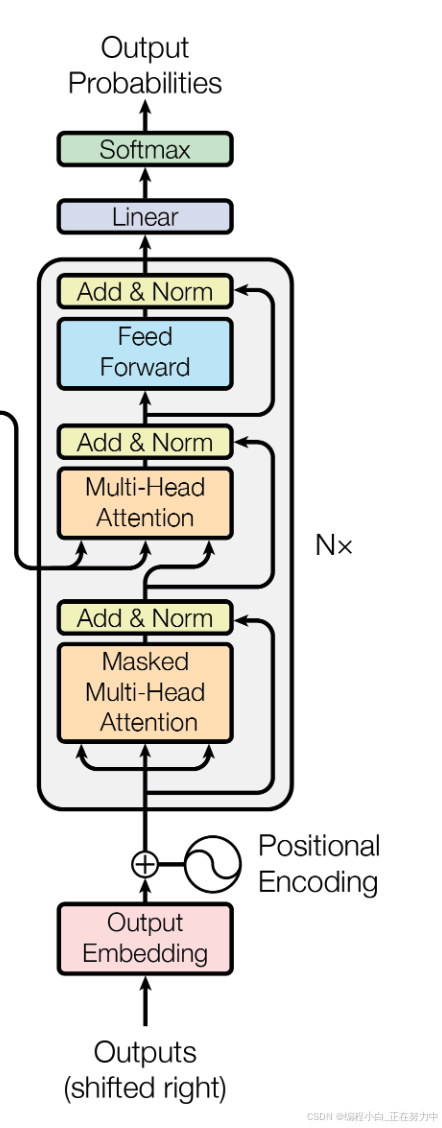
解码器是生成输出内容的关键部分,它也有6层,每层有三个重要的小部件(子结构)。这三层的作用分别是:
- 子结构-1:加了“遮眼罩”的注意力机制
- 简单说:这个部件的作用是让模型在生成句子的时候,不能“作弊”看到未来的内容。
- 为啥需要:比如我们写作文,只能根据前面已经写的内容来写下一个词,不能提前看到后面的内容。如果能看到后面的内容,就违反了正常的逻辑顺序。
- 具体操作:这个部件会用一个“遮眼罩”(Mask)来挡住未来的内容,确保模型只能用已经生成的部分来预测下一个词。
- 子结构-2:和编码器“沟通”的注意力机制
- 简单说:这个部件的作用是让解码器和编码器“聊天”,把编码器提供的信息用起来。
- 为啥需要:编码器已经把输入的内容(比如翻译任务中的原文)变成了一个“信息包”。解码器需要从这个“信息包”里提取有用的内容,才能生成合理的输出(比如翻译后的句子)。
- 具体操作:解码器通过这个部件,可以去关注编码器提供的信息里最重要的部分,然后用这些信息来生成输出。
- 子结构-3:预测下一个词
- 简单说:这个部件的作用是把前面两层处理好的信息,变成一个概率分布,然后猜出下一个最可能的词。
- 为啥需要:解码器最终的任务是生成一个词,但模型不能直接“拍脑袋”决定,而是要根据前面的处理结果,计算出每个词出现的概率,然后选择概率最高的词。
- 具体操作:先通过一个线性层把信息转换一下,然后用softmax函数把结果变成概率分布。比如,如果下一个词是“猫”的概率是0.8,是“狗”的概率是0.2,那么模型就会选“猫”。
这三层一起工作,让解码器能生成合理、符合逻辑的输出内容。
1.3 Decoder的多头自注意力vs Encoder的多头自注意力
编码器和解码器的工作方式不一样,编码器负责理解整个输入(菜谱),解码器负责根据编码器的理解一步步生成输出(写菜谱)。解码器需要一个掩码来防止它跳过步骤,而编码器不需要。解码器的结构更复杂,因为它需要参考编码器的知识库。训练的时候,编码器和解码器都能看到完整的输入,但生成的时候,解码器必须一步步来。
1.3.1 编码器的多头自注意力
想象你手里有一份菜谱,上面写满了食材和步骤。编码器的工作就是把这份菜谱看一遍,搞清楚每个食材和步骤是干嘛的,它们是怎么配合的。比如,它会发现番茄酱是用来调味的,面条要煮到合适的软硬,香草是用来增香的。
编码器不需要管顺序,因为它只需要理解整个菜谱的全貌。它就像一个超级聪明的助手,把菜谱里的信息全部消化,然后变成一个“知识库”,方便后面用。
1.3.2 解码器的多头自注意力
解码器的工作就有点不一样了。它要根据编码器的理解,一步步写出自己的菜谱。比如,它不能在还没写“煮面条”之前就写“做番茄酱”,因为这不符合烹饪顺序。
解码器的多头自注意力机制就像是它在写菜谱时,会一直提醒自己:“我已经写到哪一步了?下一步该写啥?”它会根据已经写好的部分,决定下一步该写什么,而且不能偷看后面的内容。这就像是你做饭时,只能按照已经完成的步骤来决定下一步,不能跳过步骤。
1.3.3 掩码机制
- 编码器:编码器没有掩码,因为它不需要管顺序,只需要理解整个菜谱。
- 解码器:解码器有掩码,这个掩码的作用就是防止它偷看后面的内容。比如,你写到“煮面条”这一步,掩码会挡住后面的内容,让你只能根据已经写好的部分来决定下一步。
1.3.4 编码器和解码器的结构差异
- 编码器:编码器的结构比较简单,它只需要理解菜谱里的食材和步骤,不需要管顺序。它就像一个“读心者”,把菜谱里的信息全部读出来,变成一个知识库。
- 解码器:解码器的结构更复杂。它不仅有自己的“读心”部分(理解已经写好的内容),还有一个“参考”部分,可以随时查看编码器的知识库。比如,它写到“调味”这一步时,可以参考编码器的知识库,看看番茄酱是怎么调味的。
1.3.5 训练和生成过程的差异
- 编码器:
- 训练:训练的时候,编码器可以一次性看到整个菜谱,然后学习怎么理解它。
- 生成:生成的时候,它只需要把菜谱的理解提供给解码器,不用管后面的步骤。
- 解码器:
- 训练:训练的时候,解码器可以一次性看到完整的菜谱,因为这时候它知道最终结果是什么。
- 生成:生成的时候,解码器必须一步步来,每次只能根据已经写好的内容决定下一步。比如,你做饭的时候,只能根据已经完成的步骤决定下一步,不能跳过步骤。
2. 掩码(Mask)

2.1 Decoder 为什么要加 Mask?
掩码的作用就是让解码器老老实实地按顺序生成内容,不能“作弊”看未来的信息,这样生成的结果才会更合理、更符合逻辑。
为啥要用掩码?
想象一下,你正在写一篇作文,写到一半的时候,你只能根据前面已经写好的内容来决定下一步写啥,而不能提前知道后面要写的内容。解码器也是一样,它在生成一个序列(比如翻译一句话或者生成一段文字)的时候,只能用已经生成的部分来推断下一个词,不能“作弊”去看未来还没生成的部分。
如果不加掩码,解码器就会“作弊”,看到未来的信息,这样生成的东西就不对了。所以,掩码的作用就是防止解码器“作弊”,让它老老实实地按照顺序生成内容。
掩码的作用
- 因果关系:就像写作文一样,你写下一个词,必须是基于前面已经写好的内容,不能跳过前面直接写后面的。掩码就是用来保证这种顺序的。
- 训练和推理要一致:在训练的时候,我们希望解码器能模拟真实生成的过程。如果不加掩码,训练的时候它会“作弊”,但实际用的时候(推理)它又不能作弊,这样就会导致训练和实际使用不一致。掩码能让训练过程更接近真实情况。
- 防止信息泄露:如果不加掩码,解码器会“看到”未来的信息,这就像是考试作弊一样,会影响模型的学习效果。掩码就是用来防止这种“作弊”的。
掩码是怎么实现的?
掩码其实就是一个矩阵,形状像一个上三角(对角线以上都是0,对角线以下都是负无穷)。当解码器计算注意力分数的时候,把这个掩码加进去,上三角部分的分数就会变成负无穷。经过softmax函数处理后,负无穷的值就会变成0,这样就相当于把未来的信息“遮住”了。
举个栗子:
假设解码器正在生成一个句子,已经生成了“我”和“喜”,下一步要生成“欢”。掩码会确保它只能用“我”和“喜”来推断“欢”,而不能提前知道“欢”后面的内容。
2.2 填充(padding)和掩码(masking)机制
填充(Padding)就是给短句子“凑数”,让所有句子长度一样;掩码(Masking)就是给模型一个“提示”,告诉它哪些是凑数的,哪些是真正的词。这样,模型就能正确地处理这些句子,不会被凑数的词干扰。
背景
想象一下,我们有一堆句子,这些句子的长度都不一样。比如:
- “我喜欢猫猫”(5个字)
- “我喜欢打羽毛球”(7个字)
但是,我们的模型在处理这些句子的时候,需要它们的长度是一样的。不然它会懵圈,不知道怎么处理。所以,我们需要把所有句子都变成一样的长度。
怎么做呢?分三步:
第一步:分词
先把句子拆成一个个单独的“词块”,也就是“token”。比如:
- “我喜欢猫猫” → “我”、“喜”、“欢”、“猫”、“猫”
- “我喜欢打羽毛球” → “我”、“喜”、“欢”、“打”、“羽”、“毛”、“球”
第二步:填充(Padding)
我们假设最长的句子有10个词块。为了让所有句子长度一样,短的句子就得“凑数”,在后面加上一些没意义的“占位符”,比如“”。这样:
- “我”、“喜”、“欢”、“猫”、“猫” → “我”、“喜”、“欢”、“猫”、“猫”、“”、“”、“”、“”、“”
- “我”、“喜”、“欢”、“打”、“羽”、“毛”、“球” → “我”、“喜”、“欢”、“打”、“羽”、“毛”、“球”、“”、“”、“”
这样,所有句子都变成了10个词块的长度。
第三步:掩码(Masking)
但是,模型很“傻”,它不知道哪些是真正的词,哪些是凑数的“”。所以我们得给它一个“提示”,告诉它哪些位置是凑数的。这个“提示”就是掩码。
我们用一个数字列表来表示掩码,0表示“这是真正的词”,1表示“这是凑数的”。比如:
- 对于“我、喜、欢、猫、猫、、、、、”,掩码就是 [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
- 对于“我、喜、欢、打、羽、毛、球、、、”,掩码就是 [0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
掩码的作用
模型在处理这些句子的时候,会用到一种“注意力机制”,就像人的眼睛一样,会关注句子中的每个词。但是,我们不希望它关注那些凑数的“”,因为它们没意义。
所以,我们在模型计算的时候,把掩码用上。凡是掩码为1的地方,就给它一个“超级大的负数”,让模型觉得这些地方“不值得看”。最后,模型在处理的时候,就会自动忽略这些凑数的词,只关注真正的内容。
掩码的三个位置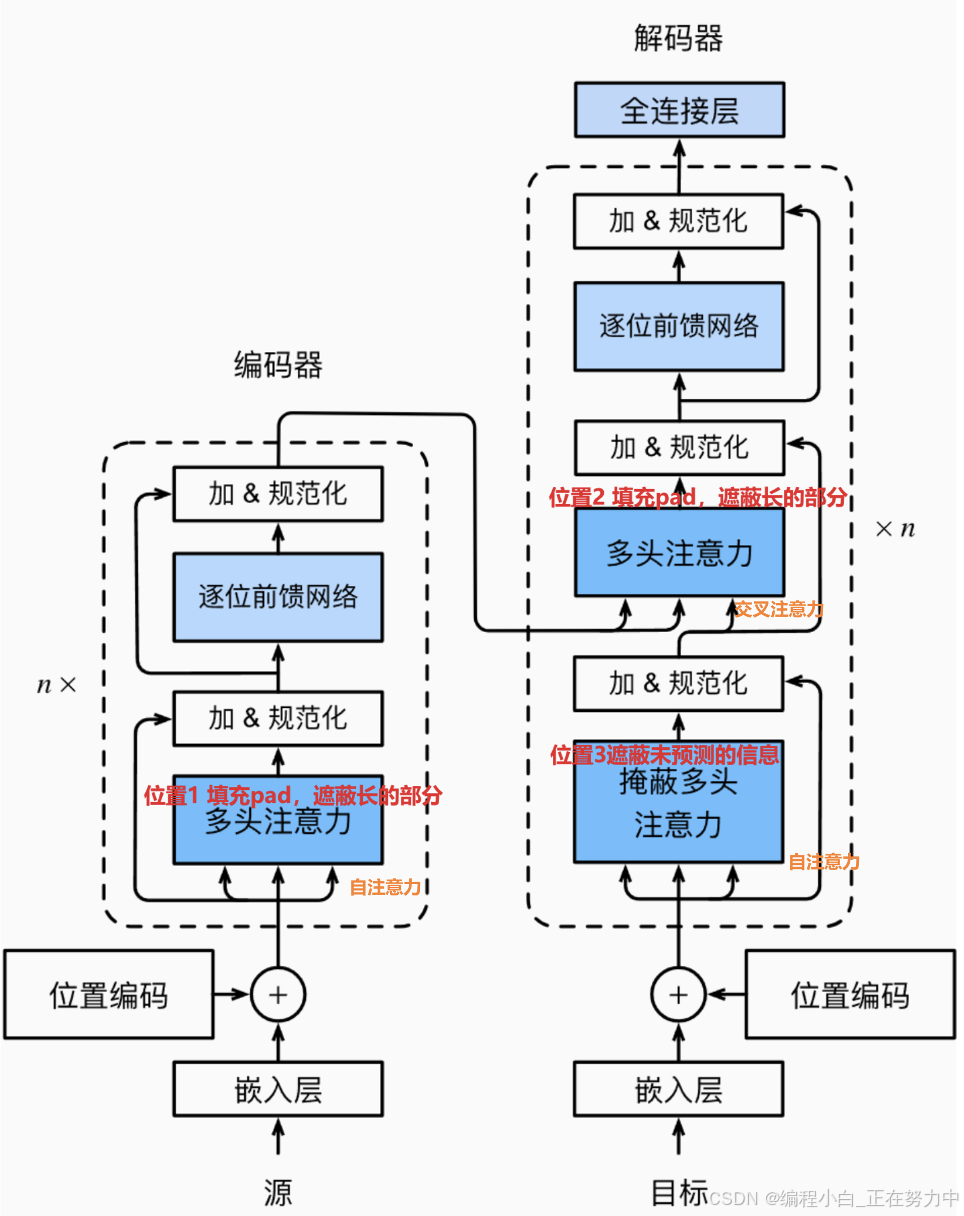
图中标注了三个位置,分别是:
位置1:编码器的多头注意力机制
位置2:解码器的多头注意力机制
位置3:解码器的掩蔽多头注意力机制
咱们一个一个进行分析。
1. 位置1:编码器的多头注意力机制
作用: 这里的掩码是用来处理 填充(Padding) 的部分。
为什么要掩码?
编码器处理的输入句子长度可能不一样,比如:
句子A:“我喜欢猫猫”(5个词)
句子B:“我喜欢打羽毛球”(7个词)
为了让模型处理方便,我们会把短的句子填充(Padding)到最长句子的长度,比如填充到10个词。
问题来了: 填充的部分是没有实际意义的,模型不应该把注意力浪费在这些填充的部分上。
解决方法:
在多头注意力机制中,我们会给填充的部分加上一个掩码(通常是1),告诉模型这些位置的注意力权重应该被忽略(比如通过设置为负无穷大)。这样模型在计算注意力的时候,就会自动忽略这些填充的部分。
2. 位置2:解码器的多头注意力机制
作用: 这里的掩码也是用来处理 填充(Padding) 的部分。
为什么要掩码?
解码器处理的目标句子也可能有填充的部分,比如:
目标句子A:“I like cats”(4个词)
目标句子B:“I like playing badminton”(6个词)
同样需要填充到最长句子的长度,比如10个词。
问题来了: 填充的部分是没有实际意义的,模型不应该把注意力浪费在这些填充的部分上。
解决方法:
和编码器一样,在多头注意力机制中,我们会给填充的部分加上一个掩码(通常是1),告诉模型这些位置的注意力权重应该被忽略。这样模型在计算注意力的时候,就会自动忽略这些填充的部分。
3. 位置3:解码器的掩蔽多头注意力机制
作用: 这里的掩码是用来防止 信息泄露,也就是防止模型看到未来的信息。
为什么要掩码?
解码器在生成句子的时候,是逐个词生成的。比如生成句子“I like cats”时,模型在生成“like”的时候,不应该看到后面的“cats”。否则模型就“作弊”了,因为它提前知道了未来的信息。
解决方法:
我们会给解码器的多头注意力机制加上一个 掩蔽(Masking),这个掩蔽是一个上三角矩阵,表示模型只能看到当前位置及之前的信息,不能看到未来的信息。比如:
当生成第1个词时,只能看到第1个位置的信息。
当生成第2个词时,只能看到第1和第2个位置的信息。
以此类推。
2.3 Mask-Multi-Head-Attention
Mask是干啥的?
在解码器(Decoder)里,Mask的作用就是防止“作弊”。就好比你在考试的时候,老师不让你偷看后面题目的答案,不然你就乱写了。在解码器里,模型也不能“偷看”未来的信息,不然生成的内容就会乱七八糟。
Mask长啥样?
Mask是一个下三角矩阵。简单来说,就是一个方阵,对角线和对角线左下角的格子是1,其他格子是0。比如5×5的矩阵,看起来就像这样:
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
1 1 1 1 1
Mask怎么用?
在解码器里,模型会计算每个位置的注意力分数,看看哪些位置更重要。Mask的作用就是在计算这些分数的时候,把“未来”的位置(也就是上三角部分)挡住,让模型只能看到“现在”和“过去”的位置。
具体来说,Mask会把上三角部分的分数变成负无穷,这样计算概率的时候,这些位置的概率就会接近0。换句话说,模型就看不到这些位置了。
为啥要用Mask?
因为解码器是生成序列的,比如生成句子或者翻译的时候,你得一个词一个词地生成,不能一下子看到后面的内容。比如,你写作文的时候,不能还没写第一句话就看到最后一句话,不然逻辑就乱了。
2.4 Linear 和 Softmax 来生成输出概率
模型根据提示猜词,用概率选最可能的词,一步步生成完整的句子,训练时用损失函数来调整模型,让它猜得更准。
想象一下,你手里有一个机器(解码器),它的任务是根据一些提示(编码器的输出)来猜下一个词是什么。这个机器在猜词之前,会先用一个工具(线性层)把提示整理一下,让这些提示和词汇表的大小对齐。比如,词汇表里有10000个词,那它就会把提示变成一个有10000个数字的列表,每个数字对应一个词。
然后,它会用另一个工具(Softmax函数)把这个数字列表变成概率,意思是每个词被选中的可能性。比如,它算出来“苹果”的概率是70%,而“香蕉”的概率是30%。最后,它就选概率最高的那个词(比如“苹果”)作为它的猜测结果。
2.4.1 预测过程
(1)初始步骤:输入准备
编码器的工作是把一篇文章读完,提取出重要的信息。解码器一开始会拿到两样东西:一是编码器提取的信息;二是一个“开始”的信号(比如一个特殊的符号“”),告诉它“开始猜词吧”。
(2)生成序列
- 预测第一个词:解码器根据编码器的信息和“开始”信号,猜第一个词。比如它猜出了“Summary”。
- 迭代生成:接下来,它把刚刚猜的“Summary”再放进去,猜下一个词,比如猜出了“of”。然后把“Summary of”再放进去,接着猜“the”,就这样一步步往下猜。
- 逐步构建:每次猜词的时候,它都会先用线性层整理提示,再用Softmax算概率,选概率最高的词。然后把新猜的词加到前面的词里,继续猜下一个。
(3)结束条件
当解码器猜出一个“结束”的信号(比如“”)时,它就知道自己已经猜完所有词了,整个过程就结束了。
(4)完整示例
假设我们要生成一个文章的摘要:
- 第一步,输入“”,猜出“Summary”。
- 第二步,输入“Summary”,猜出“of”。
- 第三步,输入“Summary of”,猜出“the”。
- 第四步,输入“Summary of the”,猜出“key”。
- 第五步,输入“Summary of the key”,猜出“points”。
- 最后,输入“Summary of the key points”,猜出“”,表示摘要生成完了。
2.4.2 训练过程
如果模型还没训练好,解码器就会瞎猜,猜出来的词可能完全不对。如果这时候还把错误的词继续喂给它,它就会越猜越离谱,就像一个小孩做错题,你还不纠正他,让他继续错下去。
2.4.3 训练和损失函数
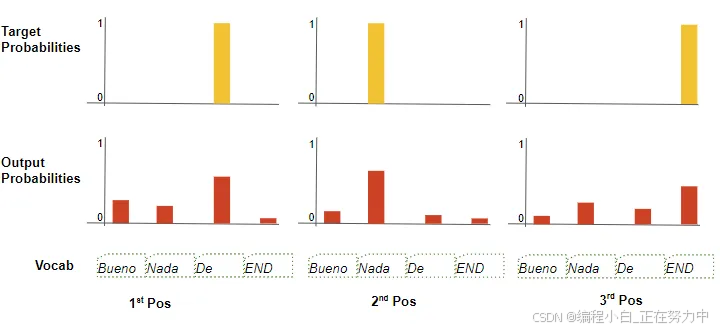
训练的时候,我们用一个“打分器”(损失函数)来比较模型猜的词和正确的词之间的差距。比如,我们希望模型在第一个位置猜“De”,那么“De”的概率应该是100%,其他词的概率是0。如果模型猜的概率分布不符合这个要求,我们就用损失函数来算一个分数,然后通过反向传播调整模型的参数,让它下次猜得更准。
3. Decoder在不同阶段的信息传递机制
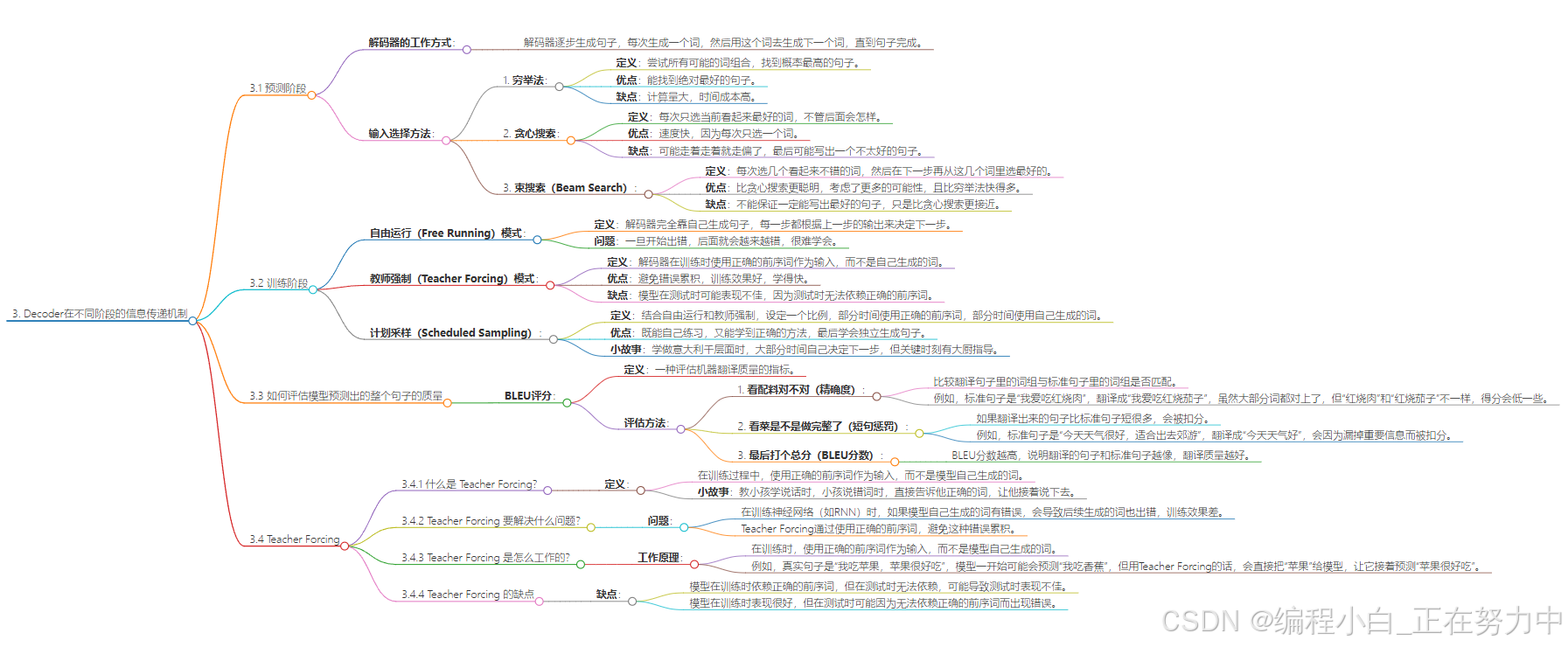
3.1 预测阶段
解码器(Decoder)就像是一个“写作文”的机器,它要一步步写出一个句子。每次写一个词,然后用这个词去写下一个词,直到句子写完。
输入选择方法
解码器在写作文的时候,有几种不同的方法来决定写哪个词。这些方法各有优缺点:
-
穷举法
这种方法就是“暴力破解”,解码器会把所有可能的词都试一遍,然后算出哪一种组合的概率最高。比如写一个句子,它会把所有可能的词排列组合,然后找出最有可能的句子。
优点:能找到绝对最好的句子。
缺点:太慢了,因为要试的东西太多了,就像在大海里捞针一样,时间成本太高。 -
贪心搜索
这种方法就是“走一步看一步”。解码器每次只选当前看起来最好的词,不管后面会怎样。比如写句子的时候,它每次只选最有可能的词,然后接着写下一个词。
优点:快,因为每次只选一个词,不用考虑太多。
缺点:可能走着走着就走偏了,因为没有考虑后面的情况,最后可能写出一个不太好的句子。 -
束搜索(Beam Search)
这种方法是贪心搜索的升级版。它每次不是只选一个词,而是选几个看起来不错的词(比如选2个或3个),然后在下一步再从这几个词里选最好的。比如,第一步选了两个词,第二步就分别试试这两个词,再选最好的。
优点:比贪心搜索更聪明,因为它考虑了更多的可能性,而且比穷举法快得多。
缺点:虽然比贪心搜索好,但也不能保证一定能写出最好的句子,只是比贪心搜索更接近。
3.2 训练阶段
计划采样就是一种“半扶半放”的训练方法,既能让模型自己学着预测,又能避免完全靠自己出错太多,或者完全依赖别人指导的问题。
自由运行(Free Running)模式
想象一下,你在学骑自行车,自由运行模式就像是你完全靠自己摸索。每踩一步,你都根据上一步的感觉来决定下一步怎么骑。如果一开始方向没把握好,歪了,那后面就会越来越歪,最后可能就摔跤了。这种模式的问题就是,一旦开始出错,后面就会越来越错,很难学会。
教师强制(Teacher Forcing)模式
这种模式就好比你学骑自行车的时候,旁边有个教练一直扶着你,告诉你每一步怎么骑。比如,教练说:“左脚踩这里,右脚踩那里。”这样虽然你能很顺利地骑完,但教练一放手,你可能又不会骑了,因为自己没真正学会怎么调整。
计划采样(Scheduled Sampling)
计划采样就是把上面两种方法结合起来。就好像教练有时候放手让你自己骑(自由运行),有时候又会在关键时刻扶你一把(教师强制)。具体来说,教练会设定一个比例,比如70%的时候让你自己骑,30%的时候帮你纠正。这样,你既能自己练习,又能学到正确的方法,最后就能学会独立骑自行车了。
小故事
假设你在学做意大利千层面,你有个大厨朋友在旁边指导。大部分时间(比如70%),他让你自己决定下一步做什么。比如你想加面条,就让你试试。但剩下的30%时间,他会直接告诉你下一步该做什么,比如提醒你该加肉酱了。这样,你既有了自己动手的机会,又不会完全走偏,最后就能学会独立做菜啦。
3.3 如何评估模型预测出的整个句子的质量
想象一下,我们用机器翻译句子,比如把中文翻译成英文,机器会一个词一个词地去猜,然后拼成一句话。但是机器翻译出来的句子和我们希望的句子(也就是标准答案)可能不一样,比如长度不一样,或者单词顺序不一样。那我们怎么判断机器翻译的这句话到底好不好呢?
** 小故事讲解**
假设我们有一份标准的菜谱(就像正确的翻译句子),然后让很多厨师(就是不同的翻译模型)按照菜谱去烧菜(翻译句子)。怎么判断谁烧的菜(翻译的句子)更好呢?可以用一个叫BLEU评分的东西来判断。
-
看配料对不对(精确度)
BLEU评分会看翻译句子里的词组(比如“红烧肉”“好吃极了”这些连续的词)和标准句子里的词组对不对得上。比如标准句子是“我爱吃红烧肉”,翻译成“我爱吃红烧茄子”,那虽然大部分词都对上了,但“红烧肉”和“红烧茄子”不一样,所以得分就会低一点。 -
看菜是不是做完整了(短句惩罚)
如果翻译出来的句子比标准句子短很多,比如标准句子是“今天天气很好,适合出去郊游”,翻译成“今天天气好”,那就会被扣分。因为翻译得太短了,可能漏掉了一些重要的东西,就像菜没做完一样。 -
最后打个总分(BLEU分数)
BLEU分数越高,就说明翻译的句子和标准句子越像,翻译的质量就越好。就像菜烧得越接近菜谱,厨师的手艺就越好。
3.4 Teacher forcing
3.4.1 什么是 Teacher Forcing?
想象一下,你正在教一个小孩学说话。小孩一开始说话的时候,可能会说错很多词,比如他想说“我吃苹果”,结果说成了“我吃香蕉”。如果一直让他自己说下去,他可能会越说越离谱,比如“我吃香蕉,香蕉是红色的,红色的香蕉很好吃……”这就完全不对了。
为了避免这种情况,你可以用“Teacher Forcing”。就是每次小孩说错的时候,你直接告诉他正确的词,让他接着说下去。比如他一开始说“我吃香蕉”,你就马上纠正他:“不对,是苹果。”然后让他接着说:“苹果是……”这样他就能一直跟着正确的方向学。
3.4.2 Teacher Forcing 要解决什么问题?
在训练一个神经网络(比如 RNN)的时候,也是一样的道理。RNN 是一种用来处理序列数据的网络,比如生成句子或者预测时间序列。正常情况下,RNN 会用上一步的输出作为下一步的输入,这就像是小孩自己接着说下去一样。但如果一开始说错了,后面就会一直错下去,导致训练效果很差,学得特别慢,还容易出问题(比如梯度消失或者爆炸)。
所以,Teacher Forcing 的出现就是为了避免这种“越说越离谱”的情况。它直接用正确的答案(也就是“Ground Truth”)来引导模型学习,让模型每次都能跟着正确的方向走。
3.4.3 Teacher Forcing 是怎么工作的?
假设小孩要学的句子是“我吃苹果,苹果很好吃”。正常情况下,他可能会说“我吃香蕉,香蕉很好吃”。但如果用 Teacher Forcing,你就会直接告诉他:“不对,是苹果。”然后让他接着说“苹果很好吃”。
放到 RNN 里,假设我们要训练一个模型,让它根据前面的词预测下一个词。比如真实句子是“我吃苹果,苹果很好吃”,模型一开始可能会预测“我吃香蕉”。但用 Teacher Forcing 的话,我们不会用“香蕉”作为下一步的输入,而是直接把“苹果”给模型,让它接着预测“苹果很好吃”。这样模型每次都能接触到正确的答案,学得更快,也更不容易出错。
3.4.4 Teacher Forcing 的缺点
虽然 Teacher Forcing 让模型在训练的时候学得很快,但它也有一个很大的问题。在训练的时候,模型一直依赖正确的答案来学习,但到了测试的时候,它就没办法再依赖正确答案了(因为测试的时候没人告诉它正确答案是什么)。这就导致模型在测试的时候可能会变得很脆弱,表现不如训练的时候好。
4. 模型的训练与评估
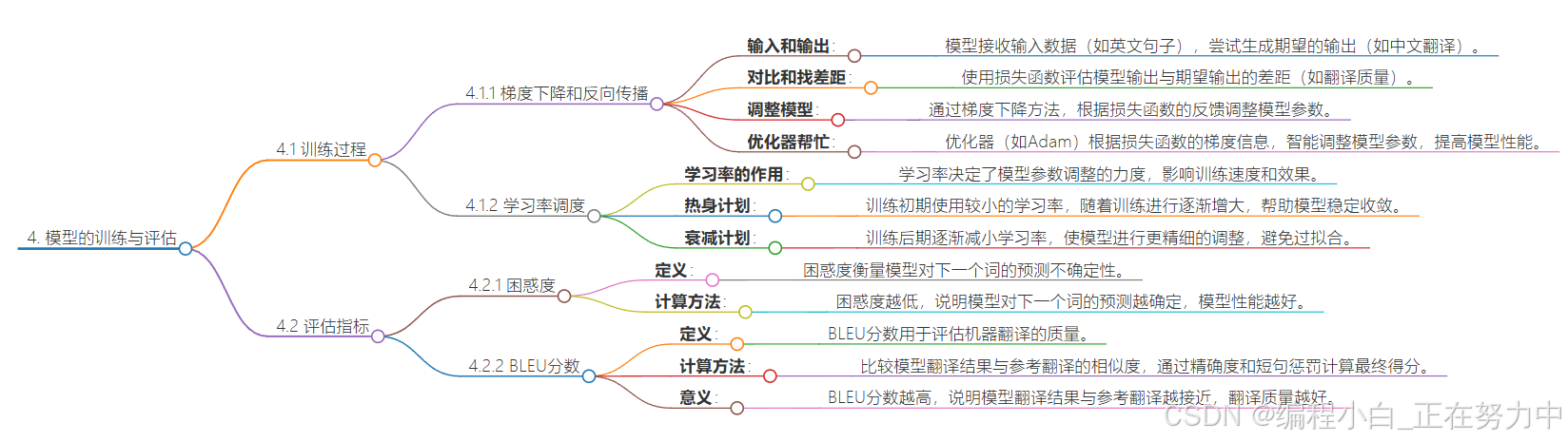
训练过程
1. 梯度下降和反向传播
想象一下,你手里有个模型(就像一个机器),它的任务是把输入的东西(比如一段话)变成我们想要的输出(比如翻译成另一种语言)。但是刚开始的时候,这个模型还不太会做,所以需要训练。
- 输入和输出:我们把一些数据(比如英文句子)喂给模型,让它试试看能不能输出正确的结果(比如翻译成中文)。
- 对比和找差距:模型输出的结果可能和我们期望的不一样,这时候就需要一个“裁判”(损失函数)来打分,看看差距有多大。比如,如果模型翻译得很糟糕,裁判就会给一个很高的“罚分”(损失值)。
- 调整模型:为了让模型变得更好,我们需要根据裁判的反馈来调整模型的“零件”(参数)。这就像是给机器拧拧螺丝、调整一下齿轮。这个过程用到的方法叫“梯度下降”,意思是沿着错误最小的方向调整零件。
- 优化器帮忙:优化器就像是一个聪明的修理工,它会根据裁判的反馈,帮助我们调整零件,让模型下次做得更好。这个过程会反复进行很多次,直到模型变得很厉害。
2. 学习率调度
学习率就像是我们调整零件时的力度。如果力度太大,可能会把零件拧坏;如果力度太小,又会调整得很慢。所以,我们需要聪明地调整力度:
- 热身计划:刚开始训练的时候,模型还不熟悉任务,所以先用小力度慢慢调整,等它熟悉了,再逐渐加大调整力度。
- 衰减计划:等到模型差不多学会的时候,我们再慢慢减小调整力度,这样可以让模型更精细地调整,避免出现“过犹不及”的情况。
评估指标
训练完模型后,我们得看看它到底学得怎么样,这时候就需要用到一些评估指标。
1. 困惑度
想象一下,你让模型预测下一个字是什么。如果模型很确定(比如看到“我爱”,它马上知道下一个字是“你”),那它的困惑度就低;如果它很迷茫(比如看到“我爱”,它猜是“你”“国”“学习”……),那困惑度就高。困惑度越低,说明模型越厉害。
2. BLEU分数
这个是用来评估翻译质量的。比如,模型把一段英文翻译成中文,我们拿它的翻译和一个专业的翻译(参考翻译)对比一下。如果模型的翻译和专业翻译很像,BLEU分数就高,说明翻译得很好;如果差得很远,分数就低。
5. 高级主题和应用
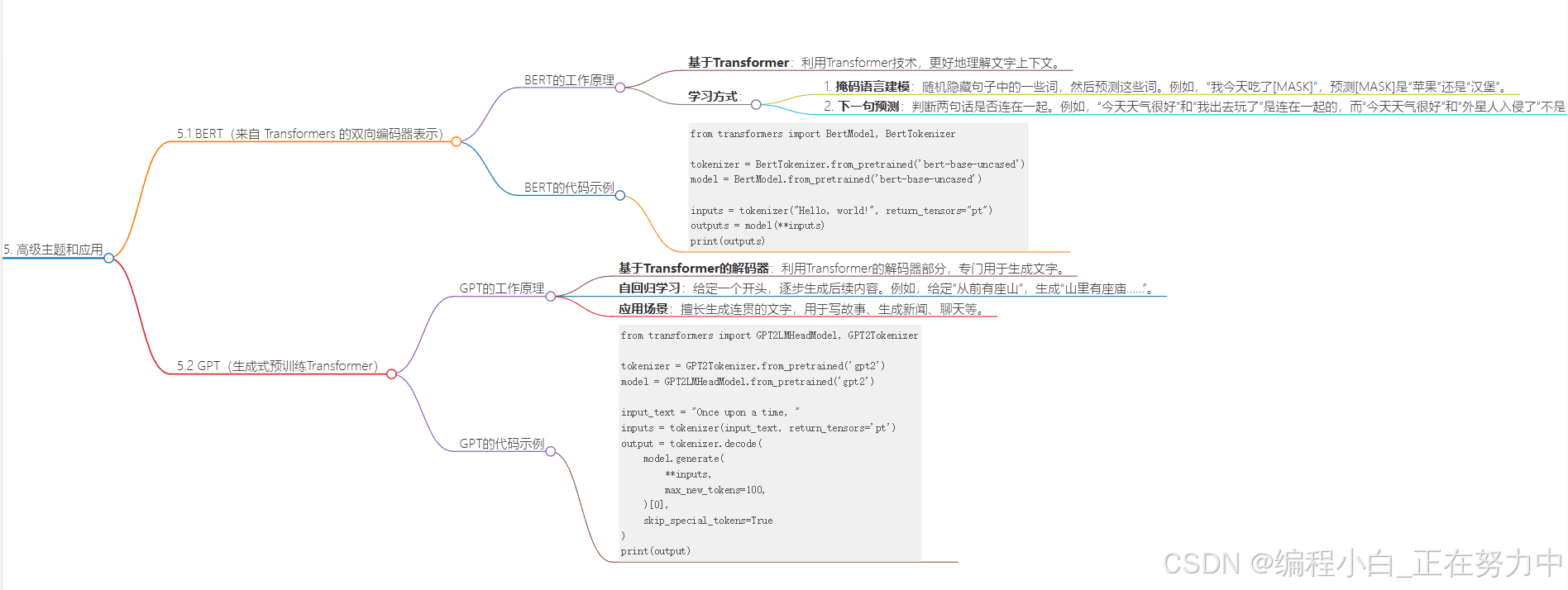
5.1 BERT(来自 Transformers 的双向编码器表示)
BERT是一种很厉害的自然语言处理模型,它的名字有点绕,但简单来说,它就像一个超级聪明的“语言理解专家”,能够理解文字的含义。
BERT的工作原理:
- BERT是基于一种叫Transformer的技术,这个技术很厉害,能让模型更好地理解文字的上下文。
- 它通过两种方式学习:
- 掩码语言建模:想象一下,你有一句话,BERT会随机把其中一些词藏起来,然后猜这些词是什么。比如“我今天吃了[MASK]”,它要猜出[MASK]是“苹果”还是“汉堡”。
- 下一句预测:BERT还会学习判断两句话是不是连在一起的。比如“今天天气很好”和“我出去玩了”是连在一起的,而“今天天气很好”和“外星人入侵了”就不是。
- 因为BERT能同时从前向后和从后向前理解句子,所以它能很好地捕捉到每个词在句子中的意思。
代码:
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
print(outputs)
5.2 GPT(生成式预训练Transformer)
GPT也是一个很厉害的模型,但它和BERT有点不一样。BERT主要是用来理解语言的,而GPT主要是用来生成语言的,比如写故事、写文章、聊天等等。
GPT的工作原理:
- GPT也是基于Transformer技术,但它只用了一部分(解码器),专门用来生成文字。
- 它是通过一种叫“自回归”的方式学习的。简单来说,就是给它一个开头,比如“从前有座山”,它会根据这个开头,一个字一个字地往后生成,生成“山里有座庙……”。
- GPT很擅长生成连贯的文字,所以它被用来写故事、生成新闻、甚至聊天。
代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
input_text = "Once upon a time, "
inputs = tokenizer(input_text, return_tensors='pt')
output = tokenizer.decode(
model.generate(
**inputs,
max_new_tokens=100,
)[0],
skip_special_tokens=True
)
print(output)
Tokenization
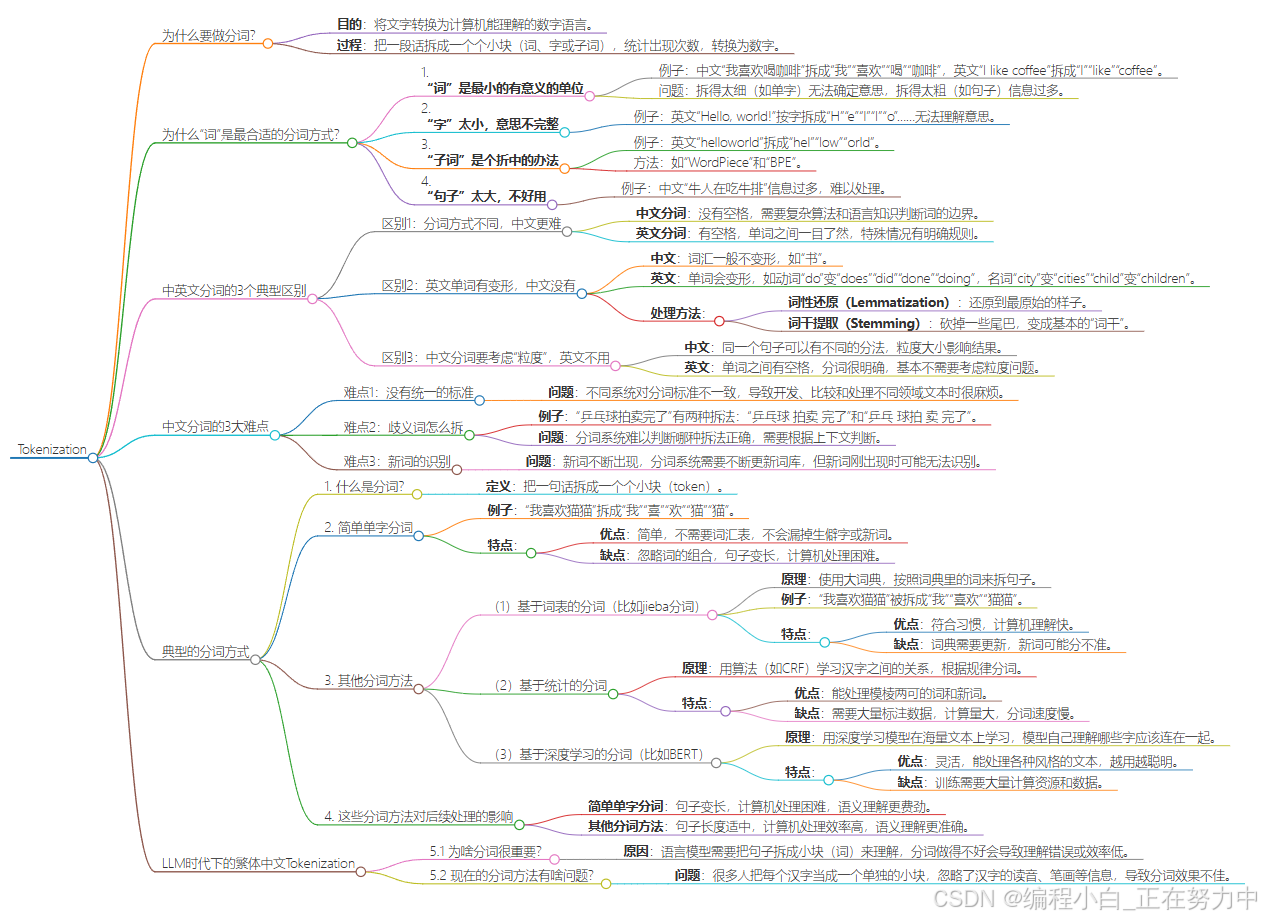
为什么要做分词?
想象一下,你手里有一堆乱七八糟的文字,比如一篇文章或者一段话。计算机很聪明,但它看不懂我们人类写的文字,它只懂数字。所以,我们需要把这些文字变成计算机能懂的“数字语言”。分词就是这个过程的第一步。
分词就是把一段话拆成一个个小块,这些小块可以是词、字,或者是介于两者之间的“子词”。然后我们数一数每个小块出现的次数,把这些次数变成数字,最后把这些数字扔进机器学习或者深度学习的模型里,让计算机去学习和处理。
为什么“词”是最合适的分词方式?
-
“词”是最小的有意义的单位
比如“我喜欢喝咖啡”,我们把它拆成“我”“喜欢”“喝”“咖啡”,每个词都有明确的意思。再比如英文“I like coffee”,拆成“I”“like”“coffee”,也很清楚。
但是,如果拆得太细,比如一个字一个字拆,就会出问题。比如“牛”,它可以是“牛市”(股票涨),也可以是“牛人”(很厉害的人),单独一个字根本没法确定意思。所以,字太小了,意思不完整。 -
“字”太小,意思不完整
比如“Hello, world!”,如果按字拆,就变成一个个字母,比如“H”“e”“l”“l”“o”……这样根本没法理解意思,因为字母太小了,没法表达完整的想法。 -
“子词”是个折中的办法
有时候,一个词太大,字又太小,那怎么办?这时候可以用“子词”。比如“helloworld”,我们把它拆成“hel”“low”“orld”,这样既不像字那么小,也不像词那么大,还能解决一些生僻词的问题。比如“WordPiece”和“BPE”就是这样的方法。 -
“句子”太大,不好用
如果按句子来分,比如“牛人在吃牛排”,这个句子信息太多了,机器很难处理,也很难复用。就好比你把一个大西瓜整个扔给计算机,它不知道怎么吃,但如果切成一块块,就好处理多了。
2.中英文分词的3个典型区别
区别1:分词方式不同,中文更难
-
中文分词:
中文写出来就是一串汉字,中间没有空格隔开,比如“我爱自然语言处理”,你很难一眼看出哪些字是一个词。比如“自然语言处理”是一个词,但你不能直接看出来,得靠上下文和语感。这就需要复杂的算法和很多语言知识来判断词的边界。
比如“我喜欢吃苹果”,“喜欢”是一个词,“吃”是一个词,“苹果”是一个词,但机器不知道,得靠程序来分析。 -
英文分词:
英文单词之间有空格隔开,比如“I love natural language processing”,单词之间一目了然,机器很容易就能把它们分开。即使遇到特殊情况(比如连字符),也有明确的规则可以处理,所以英文分词相对简单。
区别2:英文单词有变形,中文没有
-
中文:
中文词汇一般不会变形。比如“书”这个词,不管是一本书还是很多本书,都是“书”,不会变来变去。所以中文处理的时候,不用担心词的变化,直接用就行。 -
英文:
英文单词会变形,比如动词“do”,可以变成“does”(第三人称单数)、“did”(过去式)、“done”(过去分词)、“doing”(现在分词)。名词也会变,比如“city”变成“cities”,“child”变成“children”。
这些变形在处理的时候很麻烦,所以英文自然语言处理(NLP)里有两个步骤:- 词性还原(Lemmatization):把变形的词还原到最原始的样子。比如“does”“did”“doing”都还原成“do”。
- 词干提取(Stemming):把单词砍掉一些尾巴,变成一个基本的“词干”。比如“cities”砍掉“-es”变成“city”,但有时候也会出错,比如“children”可能会被砍成“childen”,这不是一个正确的单词,但也是词干提取的结果。
区别3:中文分词要考虑“粒度”,英文不用
-
中文:
中文分词的时候,同一个句子可以有不同的分法。比如“中国科学技术大学”,可以分成“中国科学技术大学”(一个词),也可以分成“中国\科学技术\大学”,或者“中国\科学\技术\大学”。
分词的“粒度”(也就是分得细不细)会影响结果。粒度大(分得粗)会保留更多上下文信息,但可能会忽略一些细节;粒度小(分得细)可能会错过一些重要的整体信息。比如“上海浦东发展银行”,如果分成“上海\浦东\发展\银行”,可能会让人误解是四个词,而不是一个整体。所以中文分词要根据具体需求来决定怎么分。 -
英文:
英文单词之间有空格,分词很明确,基本不需要考虑粒度问题。比如“natural language processing”,就是三个词,不会出现中文那种“怎么分”的问题。
3.中文分词的3大难点
难点1:没有统一的标准
中文分词就是把一句话拆成一个个词,但问题是,大家对怎么拆没有统一的说法。比如,有的系统可能觉得这个词应该这么拆,有的系统又觉得应该那么拆。这就导致:
- 开发分词系统的时候,开发者们不知道该按照谁的标准来,所以每个系统都各搞各的。
- 想比较哪个分词系统更好,也没法比,因为大家的标准都不一样。
- 如果要处理不同领域(比如新闻、医学、法律)的文本,就会很麻烦。因为不同领域对词的拆法可能不一样,比如“心脏病”在医学里是一个词,但别的地方可能就拆成“心脏”和“病”了。
难点2:歧义词怎么拆
中文里有很多句子,同一个句子可以有好几种拆法,而且每种拆法的意思还不一样。比如“乒乓球拍卖完了”,就有两种拆法:
- “乒乓球 拍卖 完了”:意思是乒乓球被拍卖完了。
- “乒乓 球拍 卖 完了”:意思是球拍被卖完了,“乒乓”还可能是修饰“球拍”的。
这就让分词系统很头疼,因为它不知道该选哪种拆法,得根据上下文来判断,但上下文有时候又不明显。比如这句话单独拿出来,系统就很难判断到底是什么意思。
难点3:新词的识别
现在新词冒出来的速度太快了,比如“雨女无瓜”这种网络热词。分词系统要想正确处理这些新词,就得不停地更新自己的词库(就是它认识的词的列表)。但问题来了:
- 新词太多了,系统来不及更新。
- 新词刚出来的时候,系统也不知道它是个词,可能把它拆成几个字,或者完全不认识。
这就要求分词系统得有本事,能快速发现新词,并且知道它怎么拆才是对的,不然就会闹笑话。
4. 典型的分词方式
1. 什么是分词?
分词就是把一句话拆成一个个小块,这些小块叫“token”。就好比把“我喜欢吃苹果”这句话拆成“我”“喜欢”“吃”“苹果”这样的小块,方便计算机去理解。
2. 简单单字分词
简单单字分词就是把每个汉字都当做一个独立的小块。比如“我喜欢猫猫”,就拆成“我”“喜”“欢”“猫”“猫”这5个小块。
特点:
- 优点:很简单,不需要提前准备什么词汇表,也不用考虑复杂规则。就像把句子拆成一个个汉字,直接搞定。而且,它不会漏掉一些生僻字或者新词,因为每个字都被单独处理了。
- 缺点:它没考虑到中文里很多词是几个字连在一起的,比如“猫猫”其实是一个词,但被拆成了两个“猫”。这样会让计算机理解起来更费劲,因为它需要更多数据和学习才能明白“猫猫”是一个整体。而且,拆成单字后,句子会变得很长,计算机处理起来就会更慢,更复杂。
3. 其他分词方法
除了简单单字分词,还有几种更高级的分词方法:
(1)基于词表的分词(比如jieba分词)
- 原理:先准备一个大词典,里面有很多常见的词、成语、固定搭配。分词的时候,就按照词典里的词来拆句子。
- 例子:用jieba分词,“我喜欢猫猫”会被拆成“我”“喜欢”“猫猫”。
- 优点:这种方式更符合我们平时说话的习惯,因为“猫猫”本来就是一个词。这样计算机理解起来会更快,因为它可以直接把“猫猫”当作一个整体来处理。
- 缺点:词典需要经常更新,因为新词会不断出现。如果遇到词典里没有的词,就可能分得不准。
(2)基于统计的分词
- 原理:用一些复杂的算法(比如CRF)来学习汉字之间的关系,看看哪些字经常在一起出现,然后根据这些规律来分词。
- 优点:能处理一些模棱两可的词(比如“我喜欢他”里的“他”到底是代词还是别的意思),也能处理一些新词。
- 缺点:训练这个算法需要很多标注好的数据(就是已经分好词的句子),而且计算量很大,分词速度也慢。
(3)基于深度学习的分词(比如BERT)
- 原理:用深度学习模型(比如BERT)在海量的文本上学习,让模型自己去理解哪些字应该连在一起。
- 优点:很灵活,能处理各种风格的文本,而且越用越聪明。
- 缺点:训练这个模型需要超级多的计算资源和数据,普通人很难上手。
4. 这些分词方法对后续处理的影响
分词之后,计算机要把这些小块(token)变成向量(一种数学表示),然后才能进一步处理。
- 简单单字分词:因为句子被拆成了很多单字,所以输入给计算机的序列就会很长。比如“我喜欢打羽毛球”被拆成很多单字,计算机处理起来就会很费劲,因为它需要处理更多的元素,计算量也会更大。
- 语义理解:简单单字分词会让计算机理解语义更困难。比如“猫猫”被拆成两个“猫”,计算机需要花更多精力去理解它们是一个整体。而如果直接把“猫猫”当作一个词,计算机就更容易理解它的意思。
不同的分词方法各有优缺点,选择哪种方法要看具体任务的需求。
5. LLM时代下的繁体中文Tokenization
5.1 为啥分词很重要?
语言模型就像一个学习语言的机器人,它要理解我们说的话,就得先把句子拆成小块,这些小块就叫“词”(Token)。分词就是把句子拆成这些小块的过程。如果分词做得不好,机器人就会理解错意思,或者效率很低。
5.2 现在的分词方法有啥问题?
现在处理中文的时候,很多人把每个汉字当成一个单独的小块。比如“我喜欢吃苹果”,就被拆成“我”“喜”“欢”“吃”“苹”“果”这样的小块。这样看起来好像没问题,但其实汉字本身有很多信息没被充分利用,比如它的读音、笔画等。
5.3 新的分词方法:子字元(SubChar)
有人想了个新办法,叫“子字元”分词。这个方法就是把汉字拆得更细,比如根据汉字的读音或者形状来拆。比如“苹”字,可以拆成“苹”“果”两个字的拼音“pín”“guǒ”,或者根据笔画拆成更细的部分。这样做的好处有两个:
- 效率更高:拆得细了,机器人处理起来更快。
- 纠错能力强:比如“苹”和“平”读音一样,用这个方法就能把它们归为一类,即使写错了,机器人也能认出来。
5.4 这个方法的工具和代码
研究这个方法的人已经把代码放在网上了,大家可以去GitHub上找到(链接是:https://github.com/thunlp/SubCharTokenization)。还有一个平台叫Hugging Face,也提供了这个方法的模型,方便大家用(链接是:https://huggingface.co/thunlp/SubCharTokenization/tree/main)。
5.5 繁体中文的分词问题
现在的问题是,这个新方法主要是针对简体中文的,繁体中文还没专门的解决方案。比如台湾地区的繁体中文,虽然有人在努力改进,但目前还是用老方法,或者直接用简体中文的分词方法。
5.6 台湾地区的尝试
台湾有个团队在尝试改进,他们用了一个很大的繁体中文语料库(就是很多文字材料),对模型进行了“持续预训练”。简单来说,就是让机器人在这些繁体中文材料上学得更聪明。不过,他们好像还没专门针对繁体中文的分词方法做改进,所以还是有点局限。
apply-gpt代码实现
from transformers import GPT2Tokenizer, GPT2LMHeadModel # 导入GPT2模型和tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2') # 加载GPT2的tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2') # 加载GPT2的模型
# 显式设置 pad_token_id
tokenizer.pad_token = tokenizer.eos_token # 设置pad_token_id为eos_token_id
# 输入文本
input_text = "Once upon a time" # 输入文本
# 将输入文本转化为token_id
inputs = tokenizer(input_text, return_tensors='pt') # 将输入文本转化为token_id
# 生成文本
# **inputs 是将inputs字典解包作为关键字参数传递给generate方法。
# max_new_tokens参数控制生成的文本长度,pad_token_id参数控制生成的文本是否以pad_token_id结尾
output = model.generate(**inputs, max_new_tokens=100, pad_token_id=tokenizer.pad_token_id)
# 解码输出
# skip_special_tokens参数控制是否跳过特殊token(如pad_token_id)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True) # 解码输出
print(decoded_output) # 输出生成的文本
运行结果:
Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the
如果遇到问题,请检测能否科学上网!
问题描述:
OSError: Can’t load tokenizer for ‘gpt2’. If you were trying to load it from ‘https://huggingface.co/models’, make sure you don’t have a local directory with the same name. Otherwise, make sure ‘gpt2’ is the correct path to a directory containing all relevant files for a GPT2Tokenizer tokenizer.
apply-bert 代码实现
from transformers import BertModel, BertTokenizer # 导入bert模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # 加载bert tokenizer
model = BertModel.from_pretrained('bert-base-uncased') # 加载bert模型
inputs = tokenizer("Hello world!", return_tensors="pt") # 输入文本转化为token id
outputs = model(**inputs) # 输入token id到bert模型中得到输出
print(outputs) # 输出模型的输出

















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









