







 本文详细介绍了Nginx的用途,包括作为web服务器、正向代理、反向代理和负载均衡。重点讲解了反向代理和负载均衡的配置与策略,如轮询、权重和ip_hash。此外,还提到了动静分离的概念和实现,以及Nginx安装与常用命令。通过具体的反向代理和负载均衡实例,展示了Nginx在实际应用中的高效能。
本文详细介绍了Nginx的用途,包括作为web服务器、正向代理、反向代理和负载均衡。重点讲解了反向代理和负载均衡的配置与策略,如轮询、权重和ip_hash。此外,还提到了动静分离的概念和实现,以及Nginx安装与常用命令。通过具体的反向代理和负载均衡实例,展示了Nginx在实际应用中的高效能。
第1章 Nginx 简介
1.1 Nginx 概述
- Nginx (“engine x”) 是一个高性能的 HTTP 和反向代理服务器,特点是占有内存少,并发能力强,事实上 nginx 的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用 nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等
1.2 Nginx 作为 web 服务器
- Nginx 可以作为静态页面的 web 服务器,同时还支持 CGI 协议的动态语言,比如 perl、php等。但是不支持 java。Java 程序只能通过与 tomcat 配合完成。Nginx 专为性能优化而开发,性能是其最重要的考量,实现上非常注重效率 ,能经受高负载的考验,有报告表明能支持高达 50,000 个并发连接数。
1.3 正向代理
- Nginx 不仅可以做反向代理,实现负载均衡。还能用作正向代理来进行上网等功能。
正向代理:如果把局域网外的 Internet 想象成一个巨大的资源库,则局域网中的客户端要访问 Internet,则需要通过代理服务器来访问,这种代理服务就称为正向代理。
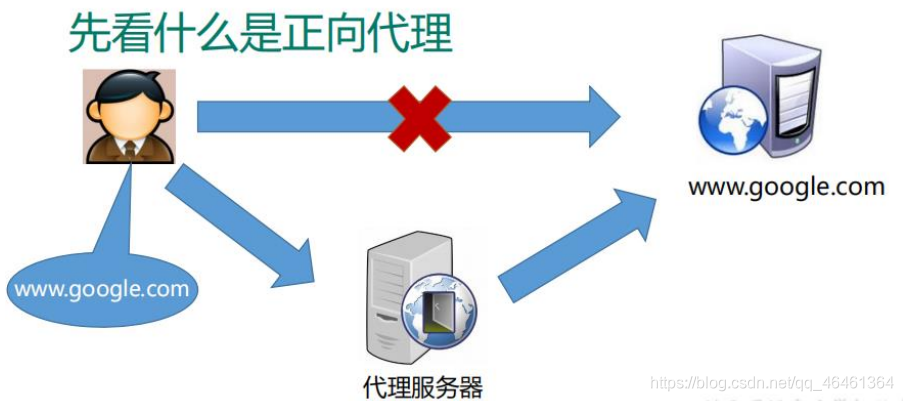
1.4 反向代理
- 反向代理,其实客户端对代理是无感知的,因为客户端不需要任何配置就可以访问,我们只需要将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据后,在返回给客户端,此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器 IP 地址。
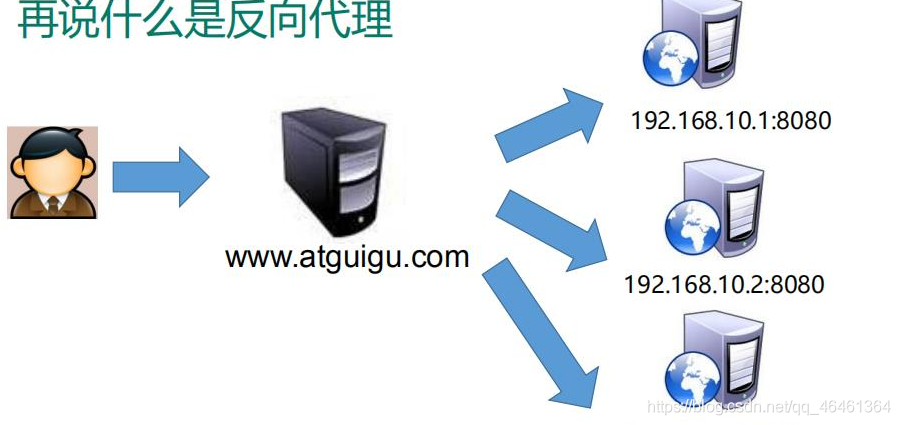
1.5 负载均衡
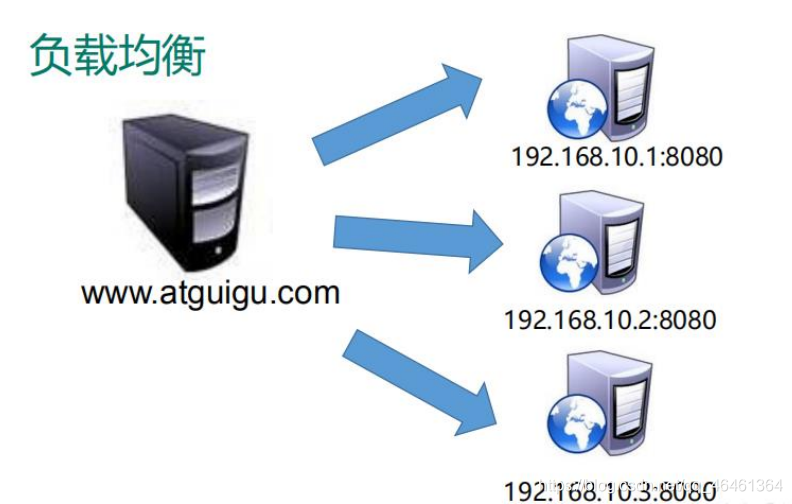
- 客户端发送多个请求到服务器,服务器处理请求,有一些可能要与数据库进行交互,服务器处理完毕后,再将结果返回给客户端。
- 这种架构模式对于早期的系统相对单一,并发请求相对较少的情况下是比较适合的,成本也低。但是随着信息数量的不断增长,访问量和数据量的飞速增长,以及系统业务的复杂度增加,这种架构会造成服务器相应客户端的请求日益缓慢,并发量特别大的时候,还容易造成服务器直接崩溃。很明显这是由于服务器性能的瓶颈造成的问题,那么如何解决这种情况呢?
- 我们首先想到的可能是升级服务器的配置,比如提高 CPU 执行频率,加大内存等提高机器的物理性能来解决此问题,但是我们知道摩尔定律的日益失效,硬件的性能提升已经不能满足日益提升的需求了。最明显的一个例子,天猫双十一当天,某个热销商品的瞬时访问量是极其庞大的,那么类似上面的系统架构,将机器都增加到现有的顶级物理配置,都是不能够满足需求的。那么怎么办呢?
- 上面的分析我们去掉了增加服务器物理配置来解决问题的办法,也就是说纵向解决问题的办法行不通了,那么横向增加服务器的数量呢?这时候集群的概念产生了,单个服务器解决不了,我们增加服务器的数量,然后将请求分发到各个服务器上,将原先请求集中到单个服务器上的情况改为将请求分发到多个服务器上,将负载分发到不同的服务器,也就是我们所说的负载均衡。
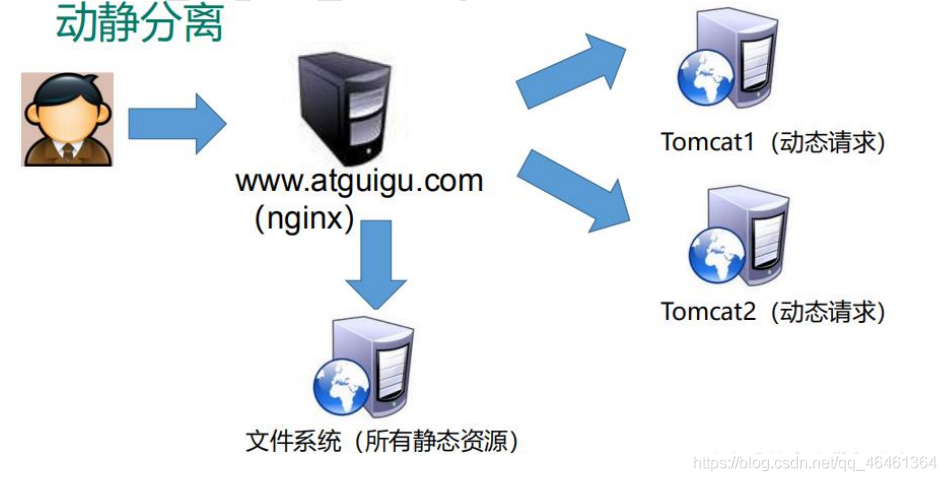
1.6 动静分离
- 为了加快网站的解析速度,可以把动态页面和静态页面由不同的服务器来解析,加快解析速度。降低原来单个服务器的压力。
第2章 Nginx 安装
进入 nginx 官网,下载
第 3 章 nginx 常用的命令和配置文件
3.1 nginx 常用的命令:
(1)启动命令
在/usr/local/nginx/sbin 目录下执行 ./nginx
(2)关闭命令
在/usr/local/nginx/sbin 目录下执行 ./nginx -s stop
(3)重新加载命令
在/usr/local/nginx/sbin 目录下执行 ./nginx -s reload
3.2 nginx.conf 配置文件
nginx 安装目录下,其默认的配置文件都放在这个目录的 conf 目录下,而主配置文件
nginx.conf 也在其中,后续对 nginx 的使用基本上都是对此配置文件进行相应的修改。
配置文件中有很多#, 开头的表示注释内容。我们去掉所有以 # 开头的段落,精简之后的内容如下:
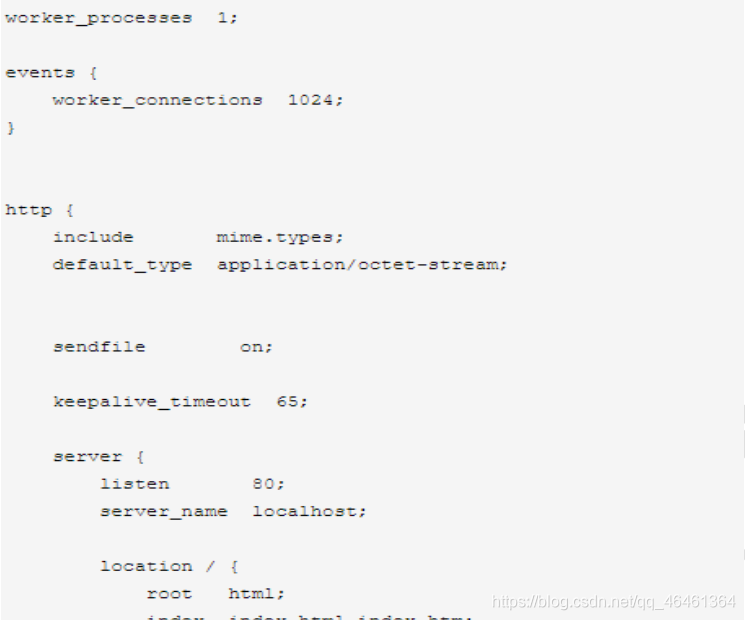
根据上述文件,我们可以很明显的将 nginx.conf 配置文件分为三部分:
-
第一部分:全局块
从配置文件开始到 events 块之间的内容,主要会设置一些影响 nginx 服务器整体运行的配置指令,主要包括配置运行 Nginx 服务器的用户(组)、允许生成的 worker process 数,进程 PID 存放路径、日志存放路径和类型以及配置文件的引入等。
比如上面第一行配置的:

这是 Nginx 服务器并发处理服务的关键配置,worker_processes 值越大,可以支持的并发处理量也越多,但是会受到硬件、软件等设备的制约 -
第二部分:events 块
events 块涉及的指令主要影响 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 work process 下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 word process 可以同时支持的最大连接数等。

上述例子就表示每个 work process 支持的最大连接数为 1024.
这部分的配置对 Nginx 的性能影响较大,在实际中应该灵活配置。
- 第三部分:http 块

这算是 Nginx 服务器配置中最频繁的部分,代理、缓存和日志定义等绝大多数功能和第三方模块的配置都在这里。
需要注意的是:http 块也可以包括 http 全局块、server 块。
① http 全局块
http 全局块配置的指令包括文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。

② server 块
这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的,该技术的产生是为了节省互联网服务器硬件成本。
每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
而每个 server 块也分为全局 server 块,以及可以同时包含多个 locaton 块。
1、全局 server 块
最常见的配置是本虚拟机主机的监听配置和本虚拟主机的名称或 IP 配置。

2、location 块
一个 server 块可以配置多个 location 块。
这块的主要作用是基于 Nginx 服务器接收到的请求字符串(例如 server_name/uri-string),对虚拟主机名称(也可以是 IP 别名)之外的字符串(例如 前面的 /uri-string)进行匹配,对特定的请求进行处理。地址定向、数据缓存和应答控制等功能,还有许多第三方模块的配置也在这里进行。
location匹配顺序
在没有标识符的请求下,匹配规则如下:
1、nginx服务器首先在server块的多个location块中搜索是否有标准的uri和请求字符串匹配。如果有多个标准uri可以匹配,就匹配其中匹配度最高的一个location。
2、然后,nginx在使用location块中,正则uri和请求字符串,进行匹配。如果正则匹配成功,则结束匹配,并使用这个location处理请求;如果正则匹配失败,则使用标准uri中,匹配度最高的location。
备注:
1、如果有精确匹配,会先进行精确匹配,匹配成功,立刻返回结果。
2、普通匹配与顺序无关,因为按照匹配的长短来取匹配结果。
3、正则匹配与顺序有关,因为是从上往下匹配。(首先匹配,就结束解析过程)
4、在location中,有一种统配的location,所有的请求,都可以匹配,如下:
location / {
# 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求
# 但是正则和最长字符串会优先匹配
}
结合标识符,匹配顺序如下:
(location =) > (location 完整路径) > (location ^~ 路径) > (location ,* 正则顺序) > (location 部分起始路径) > (location /)
即
(精确匹配)> (最长字符串匹配,但完全匹配) >(非正则匹配)>(正则匹配)>(最长字符串匹配,不完全匹配)>(location通配)
第4章 反向代理实例
1、实现效果
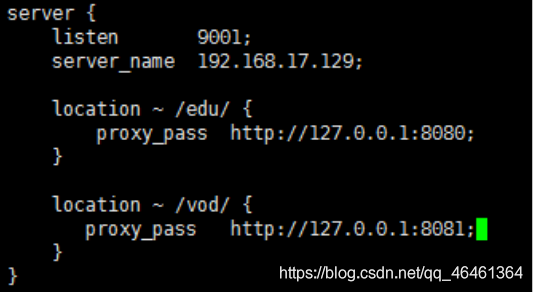
使用 nginx 反向代理,根据访问的路径跳转到不同端口的服务中
nginx 监听端口为 9001,
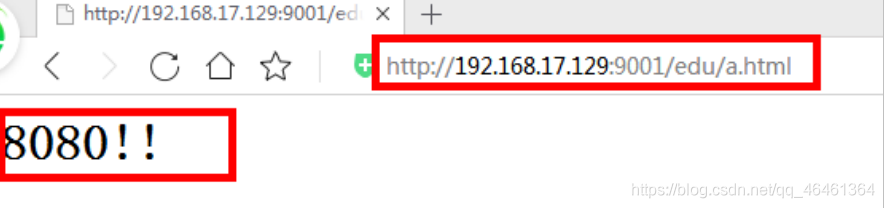
访问 http://192.168.17.129:9001/edu/ 直接跳转到 127.0.0.1:8080
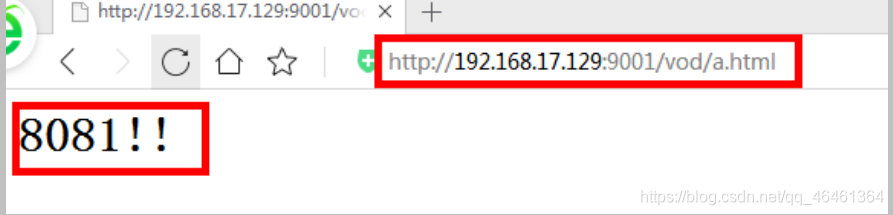
访问 http:// 192.168.17.129:9001/vod/ 直接跳转到 127.0.0.1:8081 2、准备工作
(1)准备两个 tomcat 服务器,一个 8080 端口,一个 8081 端口
(2)创建文件夹和测试页面
3、具体配置
(1)找到 nginx 配置文件,进行反向代理配置
(2)开放对外访问的端口号 9001 8080 8081
4、最终测试
第5章 负载均衡
5.1负载均衡概述
- 在网站创立初期,我们一般都使用单台机器对外提供集中式服务。随着业务量的增大,我们一台服务器不够用,此时就会把多台机器组成一个集群对外提供服务,但是,我们网站对外提供的访问入口通常只有一个,比如 www.web.com。那么当用户在浏览器输入www.web.com进行访问的时候,如何将用户的请求分发到集群中不同的机器上呢,这就是负载均衡要做的事情。
- 负载均衡通常是指将请求"均匀"分摊到集群中多个服务器节点上执行,这里的均匀是指在一个比较大的统计范围内是基本均匀的,并不是完全均匀。
5.2负载均衡实现方式
5.2.1硬件负载均衡
比如 F5、深信服、Array 等
- 优点是有厂商专业的技术服务团队提供支持,性能稳定
- 缺点是费用昂贵,对于规模较小的网络应用成本太高
5.2.2软件负载均衡
比如 Nginx、LVS、HAProxy 等
优点是免费开源,成本低廉
5.2.3Nginx负载均衡
Nginx通过在nginx.conf文件进行配置即可实现负载均衡。
(1)原理图
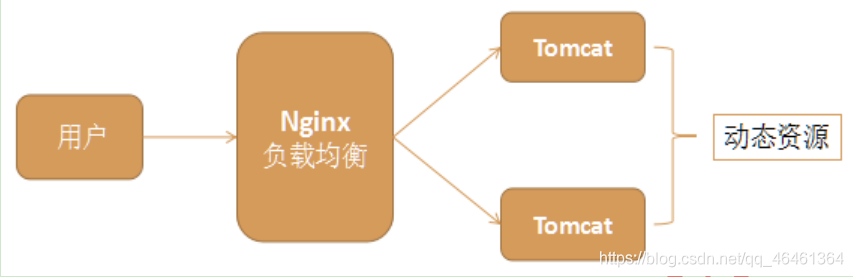
(2)配置如下:(配置2步即可)
A、在http模块加上upstream 配置
upstream www.myweb.com {
server 127.0.0.1:9100 weight=3;
server 127.0.0.1:9200 weight=1;
}
其中weight=1 表示权重,用于后端服务器性能不均的情况,访问比率约等于权重之比,权重越大访问机会越多。
upstream 是配置nginx与后端服务器负载均衡非常重要的一个模块,并且它还能对后端的服务器的健康状态进行检查,若后端服务器中的一台发生故障,则前端的请求不会转发到该故障的机器。
B、在server模块里添加location,并配置proxy_pass
location /myweb {
proxy_pass http://www.myweb.com;
}
其中 www.myweb.com 字符串要和 upstream 后面的字符串相等
5.3Nginx常用负载均衡策略
5.3.1轮询(默认)
注意:这里的轮询并不是每个请求轮流分配到不同的后端服务器,与ip_hash类似,但是按照访问url的hash结果来分配请求,使得每个url定向到同一个后端服务器,主要应用于后端服务器为缓存时的场景下。如果后端服务器down掉,将自动剔除
upstream backserver {
server 127.0.0.1:8080;
server 127.0.0.1:9090;
}
5.3.2权重
每个请求按一定比例分发到不同的后端服务器,weight值越大访问的比例越大,用于后端服务器性能不均的情况
upstream backserver {
server 192.168.0.14 weight=5;
server 192.168.0.15 weight=2;
}
5.3.3ip_hash
ip_hash也叫IP绑定,每个请求按访问ip的hash值分配,这样每个访问客户端会固定访问一个后端服务器,可以解决会话Session丢失的问题
算法:hash(“124.207.55.82”) % 2 = 0, 1
upstream backserver {
ip_hash;
server 127.0.0.1:8080;
server 127.0.0.1:9090;
}
5.3.4最少连接
web请求会被转发到连接数最少的服务器上
upstream backserver {
least_conn;
server 127.0.0.1:8080;
server 127.0.0.1:9090;
}
5.4负载均衡其他几个配置
配置1:
upstream backserver {
server 127.0.0.1:9100;
#其它所有的非backup机器down的时候,才请求backup机器
server 127.0.0.1:9200 backup;
}
配置2:
upstream backserver {
server 127.0.0.1:9100;
#down表示当前的server是down状态,不参与负载均衡
server 127.0.0.1:9200 down;
}
一般在项目上线的时候,可以分配部署不同的服务器上,然后对Nginx重新reload。
reload不会影响用户的访问,或者可以给一个提示页面,系统正在升级…
第6章 静态代理
把所有静态资源的访问改为访问nginx,而不是访问tomcat,这种方式叫静态代理。因为nginx更擅长于静态资源的处理,性能更好,效率更高。
所以在实际应用中,我们将静态资源比如图片、css、html、js等交给nginx处理,而不是由tomcat处理。
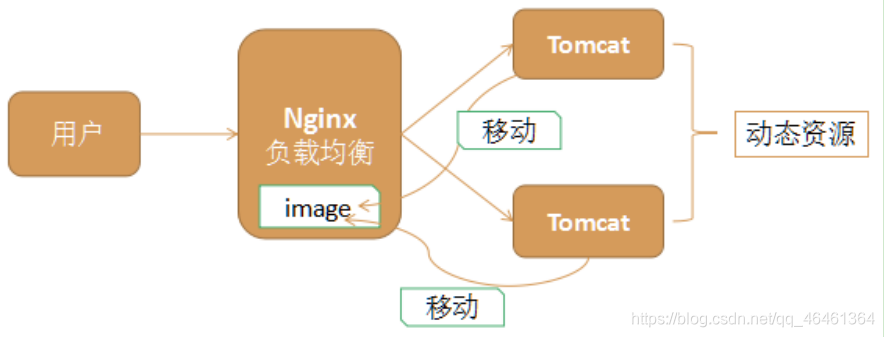
6.1Nginx静态代理实现方式
6.1.1方式一 在nginx.conf的location中配置静态资源的后缀
例如:当访问静态资源,则从linux服务器/opt/static目录下获取(举例)
location ~ .*\.(js|css|htm|html|gif|jpg|jpeg|png|bmp|swf|ioc|rar|zip|txt|flv|mid
|doc|ppt|pdf|xls|mp3|wma)$ {
root /opt/static;
}
说明
- ~ 表示正则匹配,也就是说后面的内容可以是正则表达式匹配
- 第一个点 . 表示任意字符
- *表示一个或多个字符
- . 是转移字符,是后面这个点的转移字符
- | 表示或者
- $ 表示结尾
6.1.2方式二 在nginx.conf的location中配置静态资源所在目录实现
例如:当访问静态资源,则从linux服务器/opt/static目录下获取(举例)
location ~ .*/(css|js|img|images) {
root /opt/static;
}
xxx/css
xxx/js
xxx/img
xxx/images
我们将静态资源放入 /opt/static 目录下,然后用户访问时由nginx返回这些静态资源
第7章 动静分离
Nginx的负载均衡和静态代理结合在一起,我们可以实现动静分离,这是实际应用中常见的一种场景。
动态资源,如jsp由tomcat或其他web服务器完成
静态资源,如图片、css、js等由nginx服务器完成
它们各司其职,专注于做自己擅长的事情
动静分离充分利用了它们各自的优势,从而达到更高效合理的架构
7.1架构图
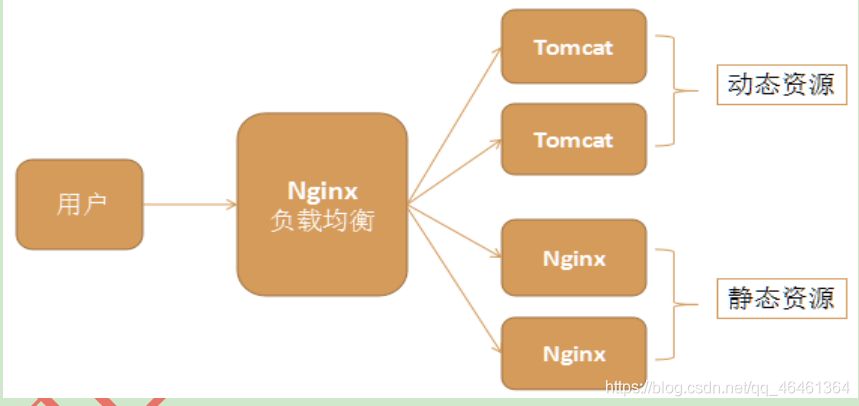
整个架构中,一个nginx负责负载均衡,两个nginx负责静态代理。Nginx在一台Linux上安装一份,可以启动多个Nginx,每个Nginx的配置文件不一样即可
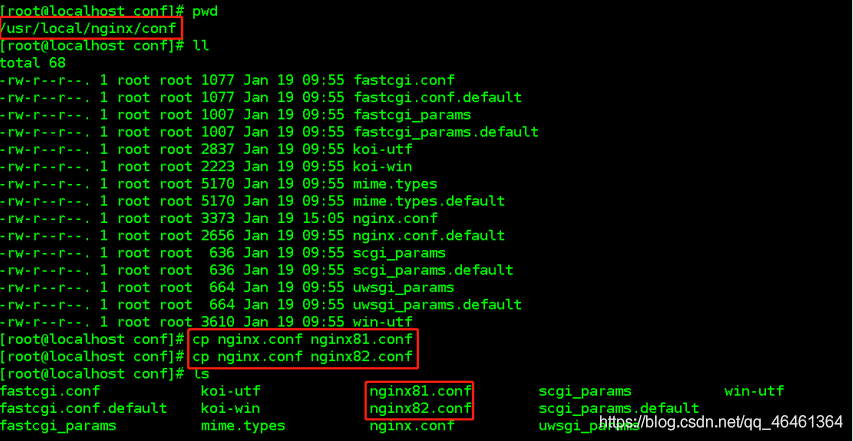
7.2实现步骤
1、拷贝两份nginx配置文件(静态代理)
2、修改新拷贝的nginx81.conf和nginx82.conf配置文件
- Nginx81.conf端口号,因为这两个机器只需要做静态代理,所以删除掉负载均衡的配置

- Nginx82.conf端口号,因为这两个机器只需要做静态代理,所以删除掉负载均衡的配置
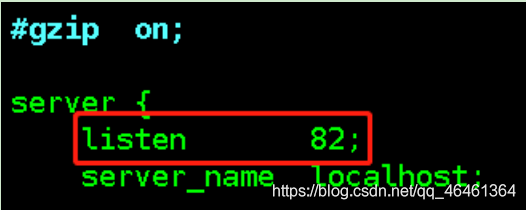
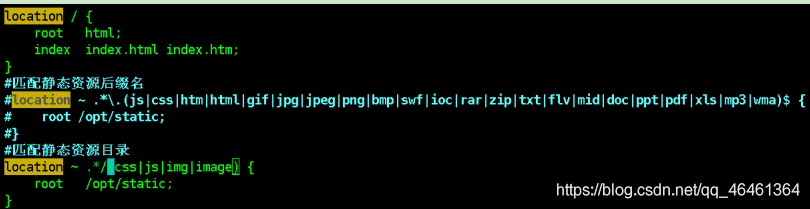
- 静态代理的配置
3、负载均衡Nginx配置(nginx.conf)
A、动态资源的负载均衡
upstream www.myweb.com {
server 127.0.0.1:9100 weight=5;
server 127.0.0.1:9200 weight=2;
}
location /myweb {
proxy_pass http://www.myweb.com;
}


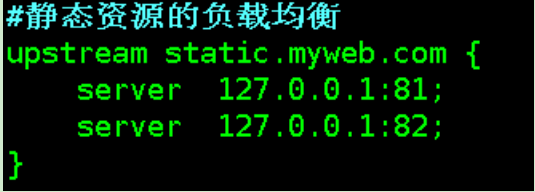
B、静态资源的负载均衡
upstream static.myweb.com {
server 127.0.0.1:81 weight=1;
server 127.0.0.1:82 weight=1;
}
location ~ .*/(css|js|img|images) {
proxy_pass http://static.myweb.com;
}

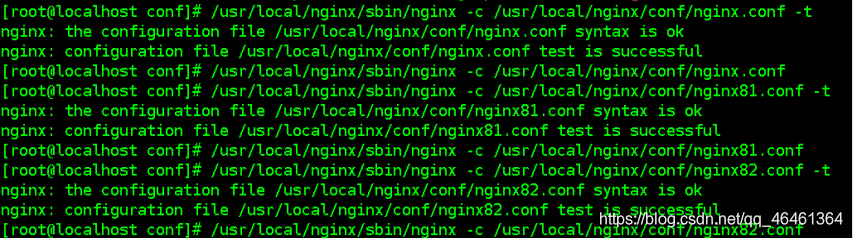
4、启动三台nginx服务器,启动两台tomcat服务器
5、浏览器输入http://192.168.235.128/myweb/进行测试
关闭掉一台nginx静态代理服务器
关闭掉一台tomcat服务器

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









