







 该专栏为热销专栏榜 第4名
该专栏为热销专栏榜 第4名一、本文介绍
🔥本文给大家介绍使用Agent Attention模块改进YOLOv11网络模型。其主要作用是通过引入高效的代理token来减少计算复杂度,同时保留全局上下文建模能力。相比传统的Softmax注意力,Agent Attention通过代理token聚合并广播信息,从而降低了模型在处理高分辨率图像时的计算负担,并显著提高了推理速度。其优势在于保持了目标检测中的全局信息处理能力,同时加速了生成过程,特别是在高分辨率场景下,可以提高检测精度、减少内存消耗,并提升处理速度。
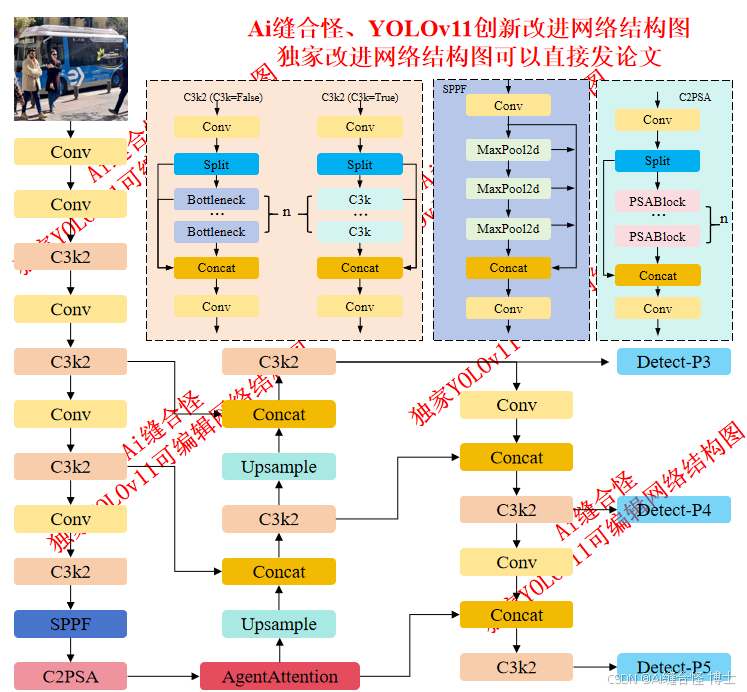
展示部分YOLOv11改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov11n_AgentAttention.yaml
专栏改进目录:YOLOv11改进专栏包含卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、C2PSA/C3k2二次创新改进、全网独家创新等创新点改进
全新YOLOv11-发论文改进专栏链接:全新YOLOv11创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进1 : yolov11n_AgentAttention.yaml
🚀 创新改进2 : yolov11n_C2PSA_AgentAttention.yaml
二、Agent Attention模块介绍

摘要:注意力模块是Transformer架构的核心组件。虽然全局注意力机制具有强大的表征能力,但其过高的计算成本限制了其在多种场景中的应用。本文提出了一种新型注意力范式——代理注意力(Agent Attention),旨在实现计算效率与表征能力之间的最佳平衡。具体而言,代理注意力通过引入四元组(Q,A,K,V)的形式,在传统注意力模块中新增了一组代理标记A。这些代理标记首先作为查询标记Q的代理,从K和V中聚合信息,随后将信息反馈给Q。由于代理标记的数量可以设计得远少于查询标记数量,代理注意力在保持全局上下文建模能力的同时,显著优于广泛采用的Softmax注意力机制。有趣的是,我们证明了所提出的代理注意力等同于线性注意力的广义形式。因此,代理注意力实现了软性线性注意力的强大性能与线性注意力高效性的无缝融合。大量实验表明,代理注意力在各类视觉Transformer架构及图像分类、目标检测、语义分割、图像生成等多样化视觉任务中均展现出优异效果。值得注意的是,得益于其线性注意力特性,代理注意力在高分辨率场景中表现尤为突出。例如,当应用于Stable Diffusion时,我们的注意力机制无需额外训练即可显著提升图像生成速度和质量。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 33
33

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









