



在上一篇文章,介绍了Gen6d的环境配置和个人数据集制作,当时了解的不多做出来的效果很差,过程也不够详细,所以这一次详细介绍制作个人数据集。
个人数据集制作
1、首先还是自己拍一段视频,放在 ..\Gen6D\data\custom\video路径下。
拍摄视频的目标对象一定是要静止的,假如目标对象没有纹理,那背景的纹理必须要足够丰富。
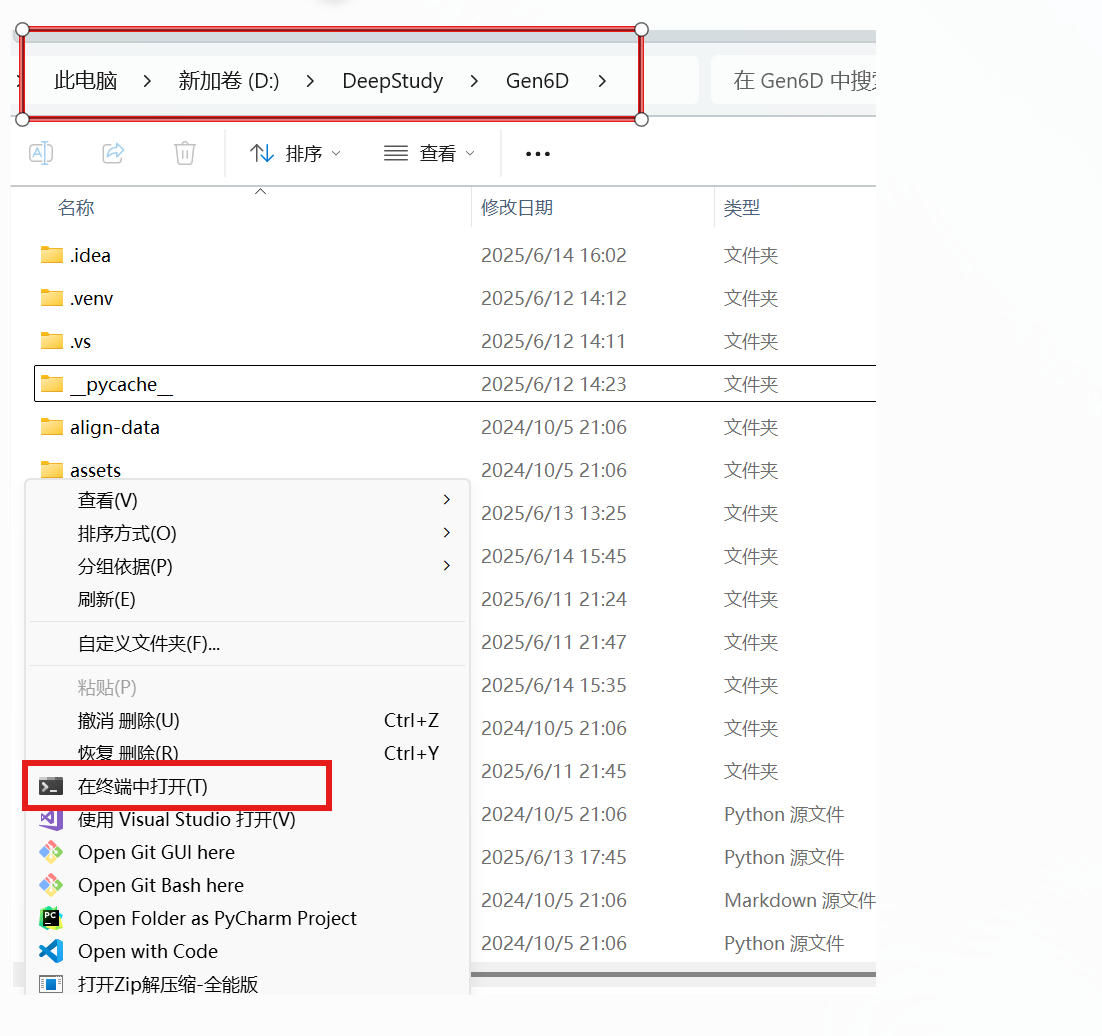
2、在Gen6d文件夹下打开终端
3、激活虚拟环境,将视频分割为大小一致的图片
# 激活虚拟环境
conda activate xxx
#eg: conda activate torch1.10
# 分割视频
# --transpose 解决图片颠倒
python prepare.py --action video2image --input data/custom/video/XXX.mp4 --output data/custom/XXX/images --frame_inter 10 --image_size 960 --transpose
# eg:python prepare.py --action video2image --input data/custom/video/duanzi.mp4 --output data/custom/duanzi/images --frame_inter 10 --image_size 960 --transpose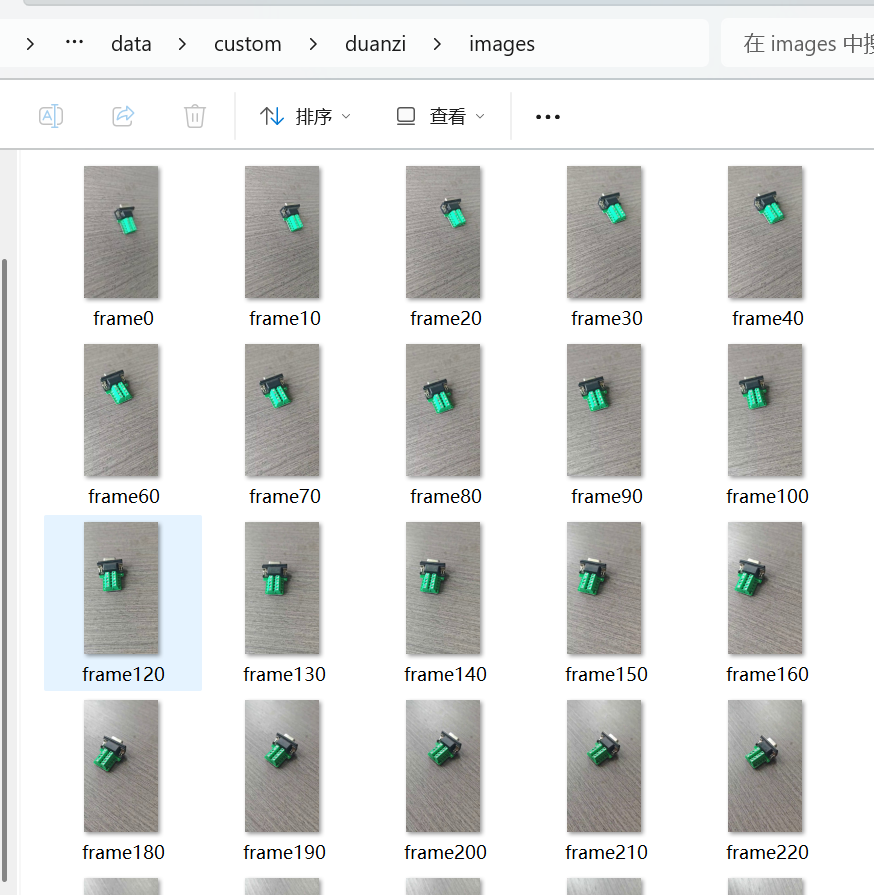
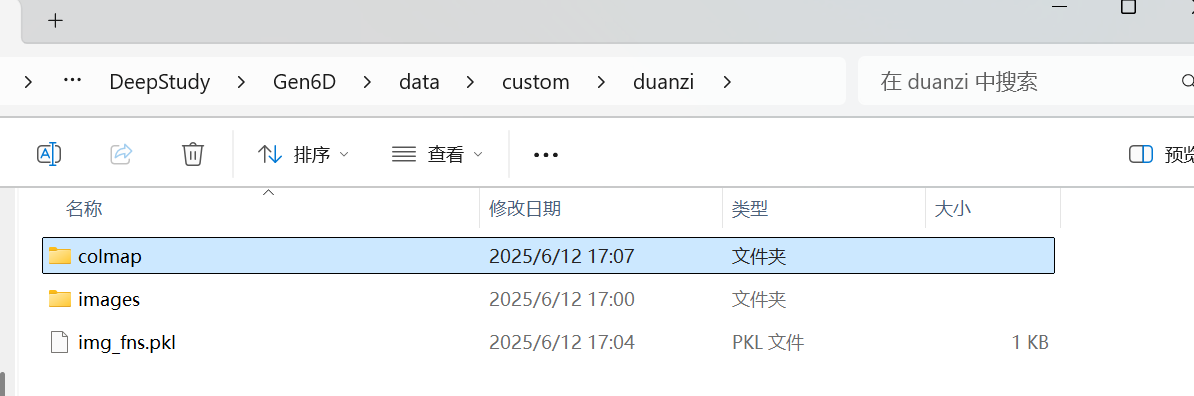
4、恢复相机姿势
# colmap假如没有添加环境变量就需要colmap.bat的完整路径(原作者这里写的是colmap.exe的路径,但是运行会报错,打不开colmap)
python prepare.py --action sfm --database_name custom/XXX--colmap <colmap.bat路径地址>
# eg:python prepare.py --action sfm --database_name custom/duanzi --colmap D:\DeepStudy\COLMAP\colmap.bat生成了colmap文件夹
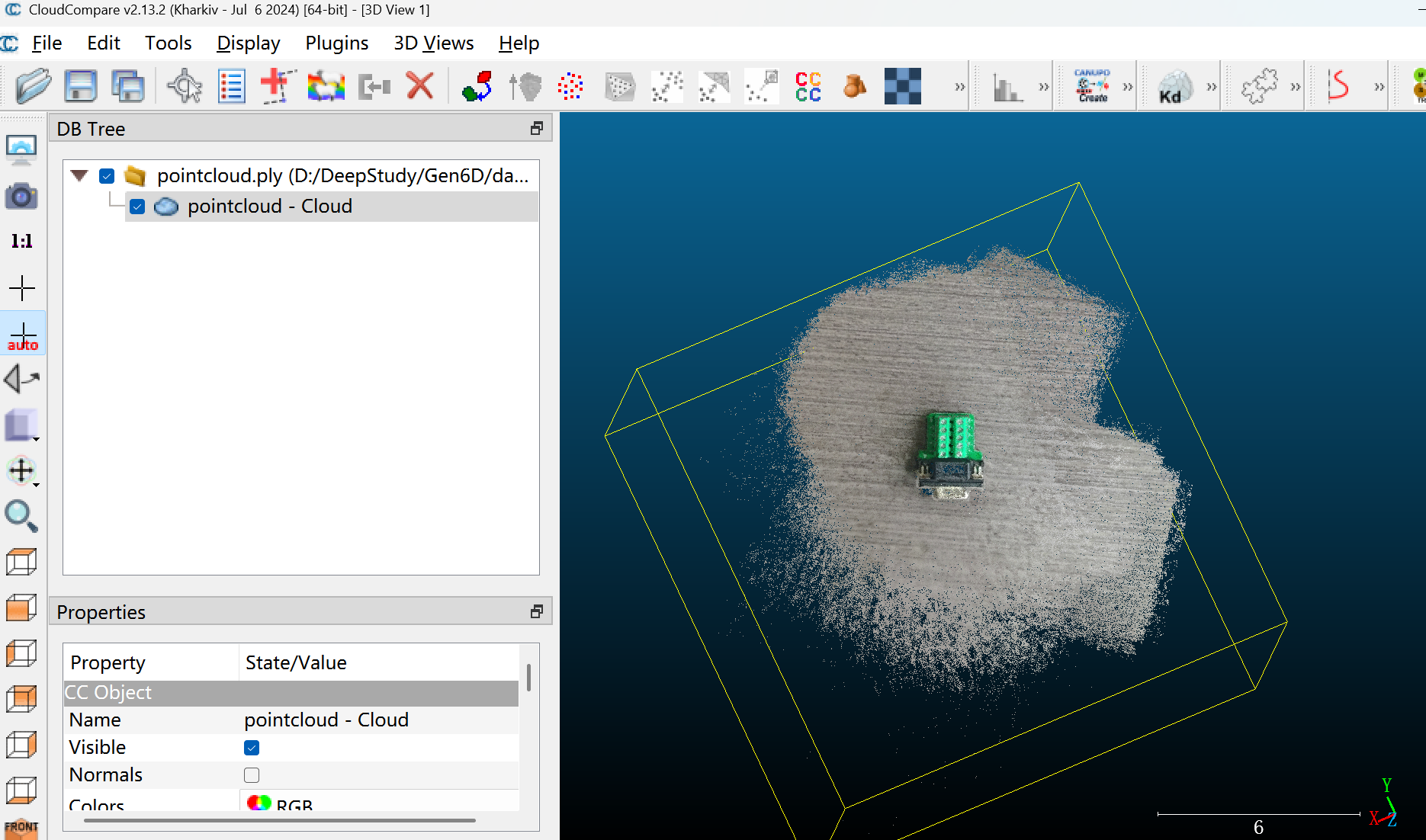
5、剪裁点云,使用CloudCompare打开Gen6D/data/custom/duanzi/colmap/pointcloud.ply
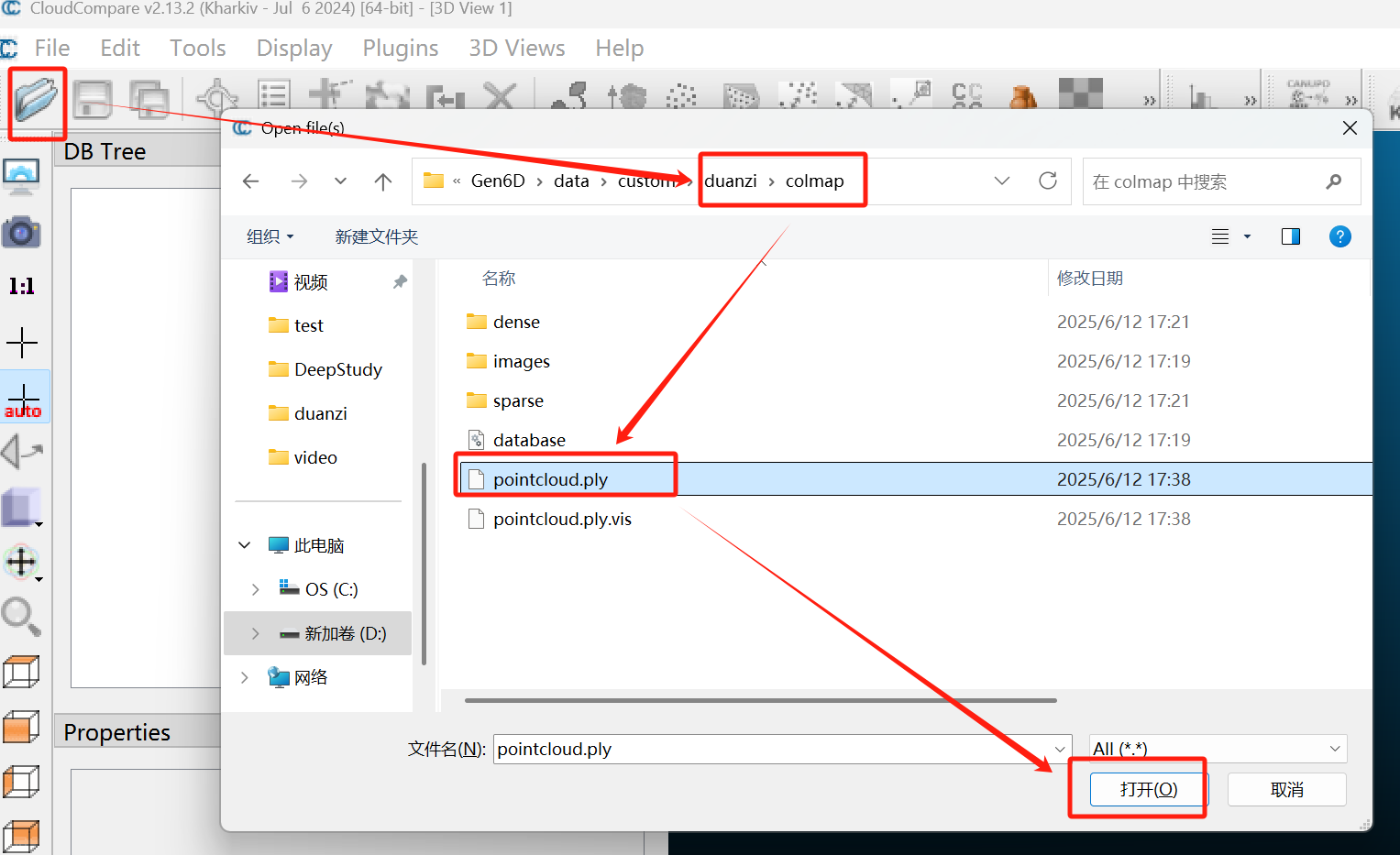
鼠标左键旋转视角,右键拖动界面
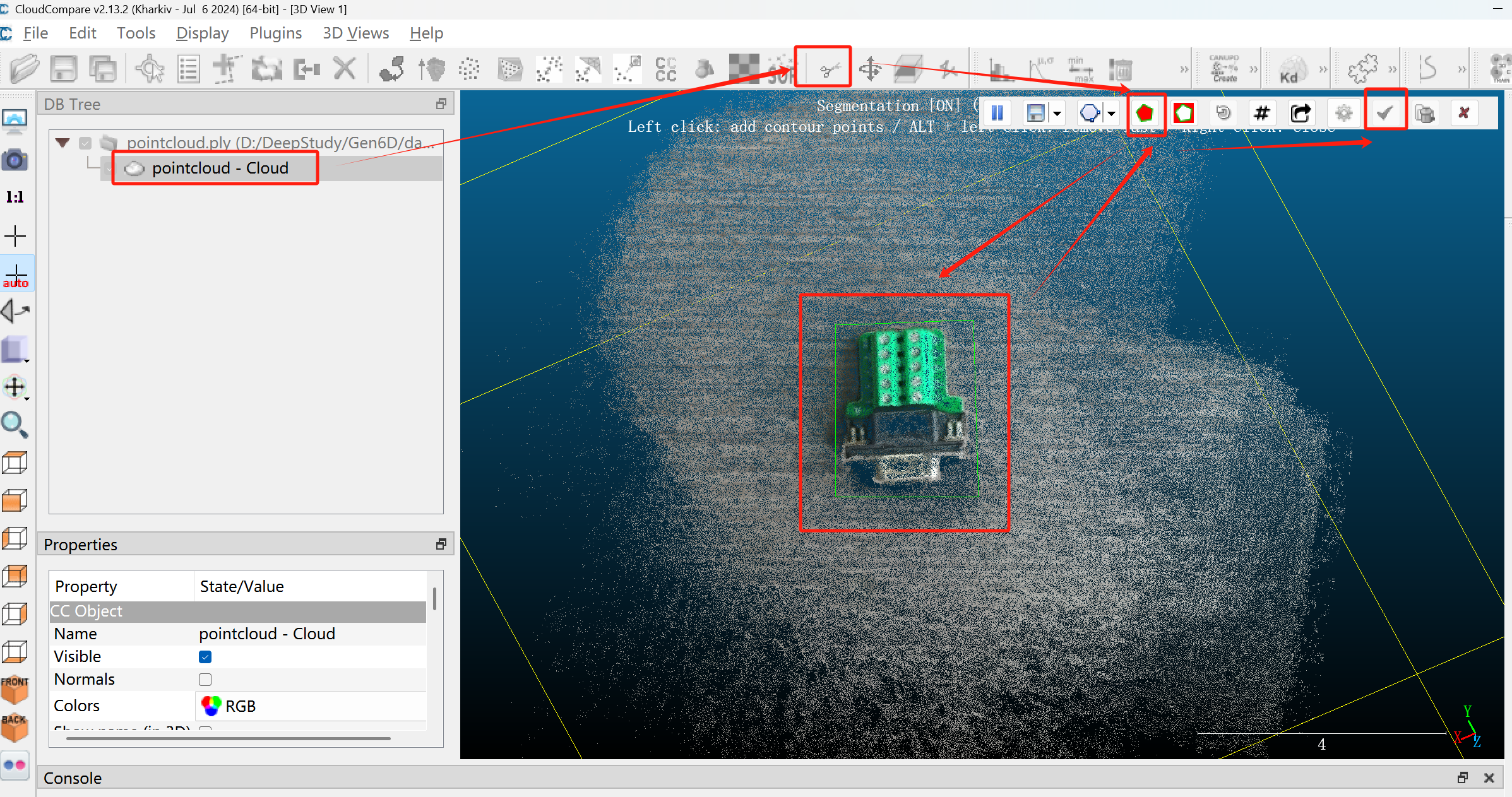
剪裁
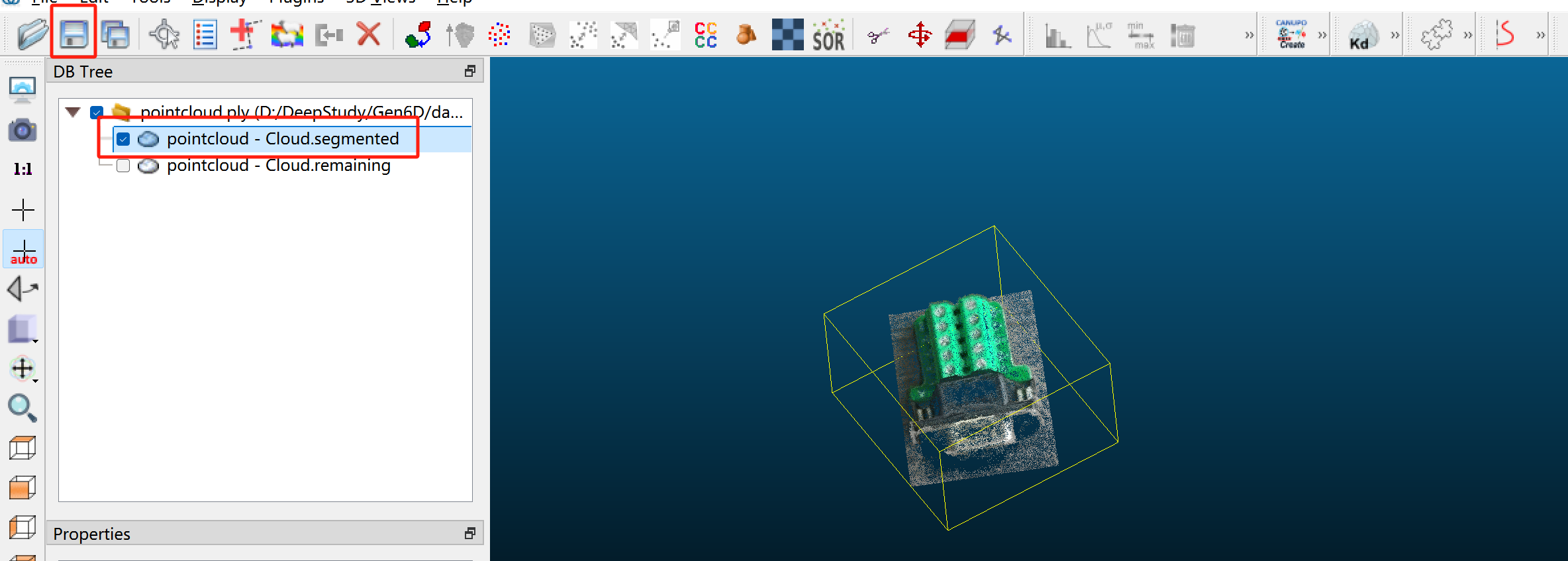
将裁剪后的目标对象点云导出:需要取消remaining部分,只选择segmented,用binary格式保存在Gen6D/data/custom/duanzi/目录下,命名为object_point_cloud.ply(名字不要修改)。
6、指定目标对象的X正方向和Z正方向
使用CloudCompar打开刚保存的Gen6D/data/custom/duanzi/object_point_cloud.ply。
1)Z正方向的向量:拟合一个平面,其法线作为Z正方向的向量。
首先在放置物体的平面剪切点云
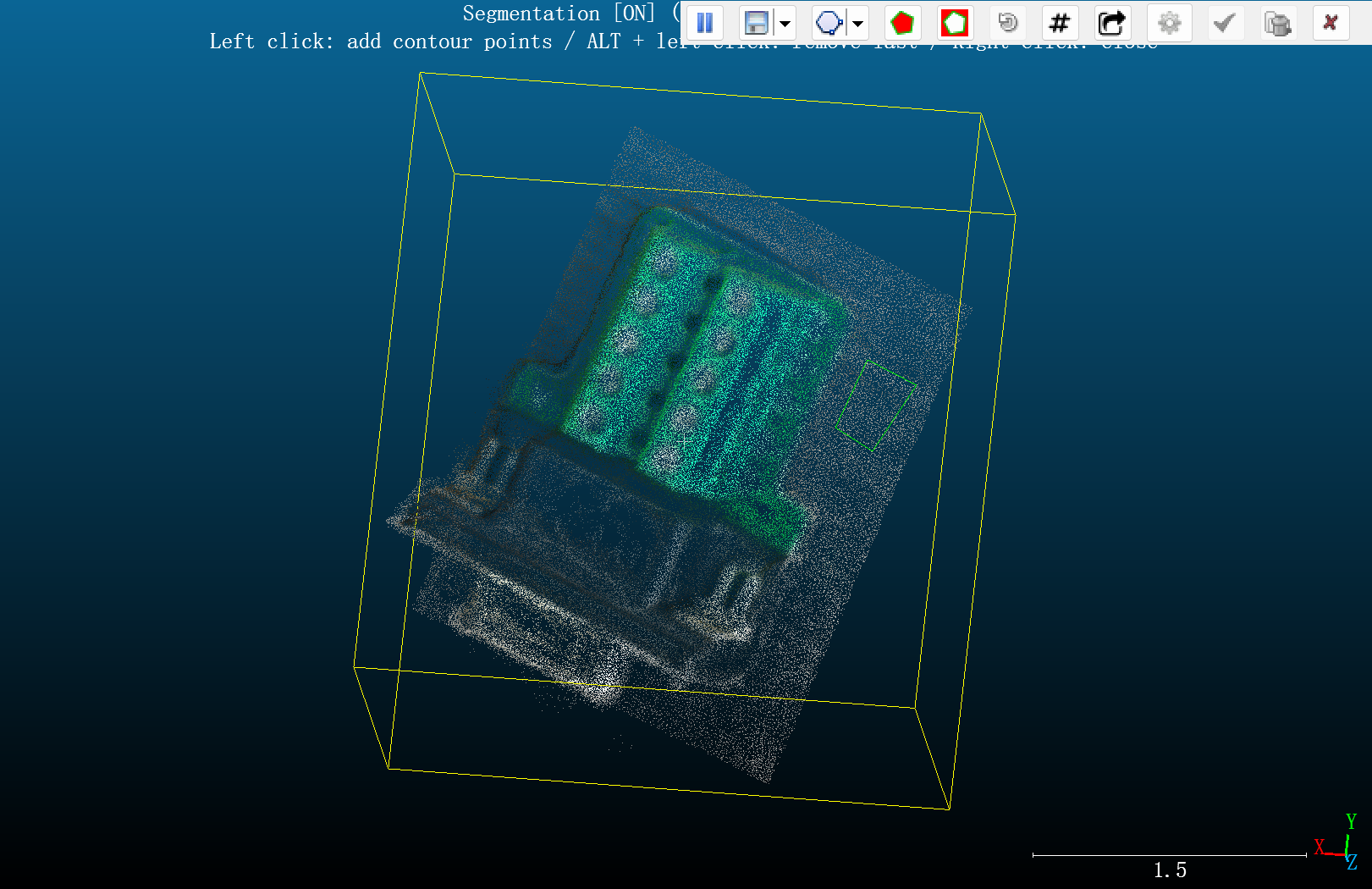
7、选中剪切之后的segmented,在点击Tools->Fit->Plane
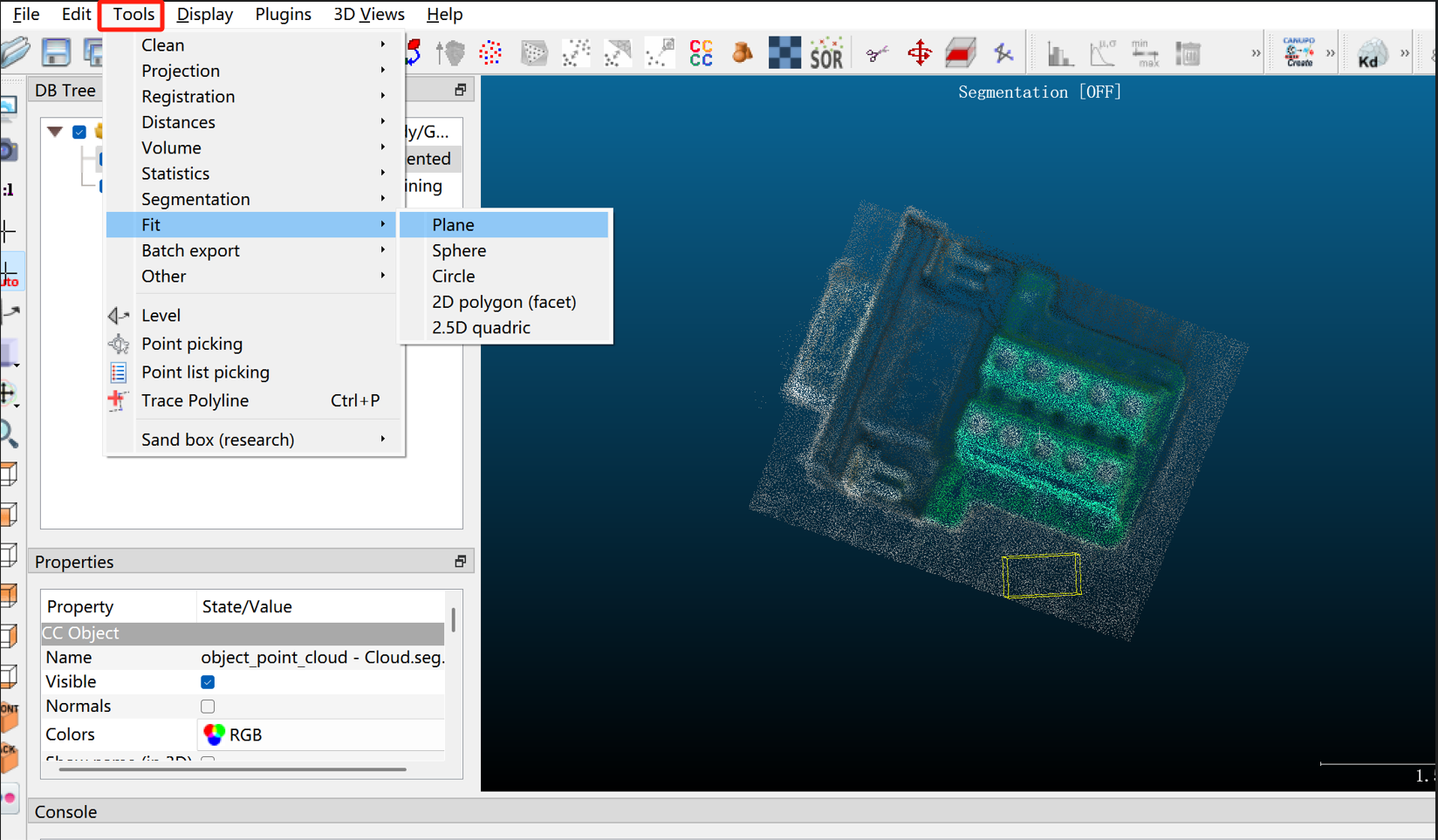
勾选 Show normal vector,发现Z轴与放置平面垂直

将法线可视化并使用法线作为 Z 方向
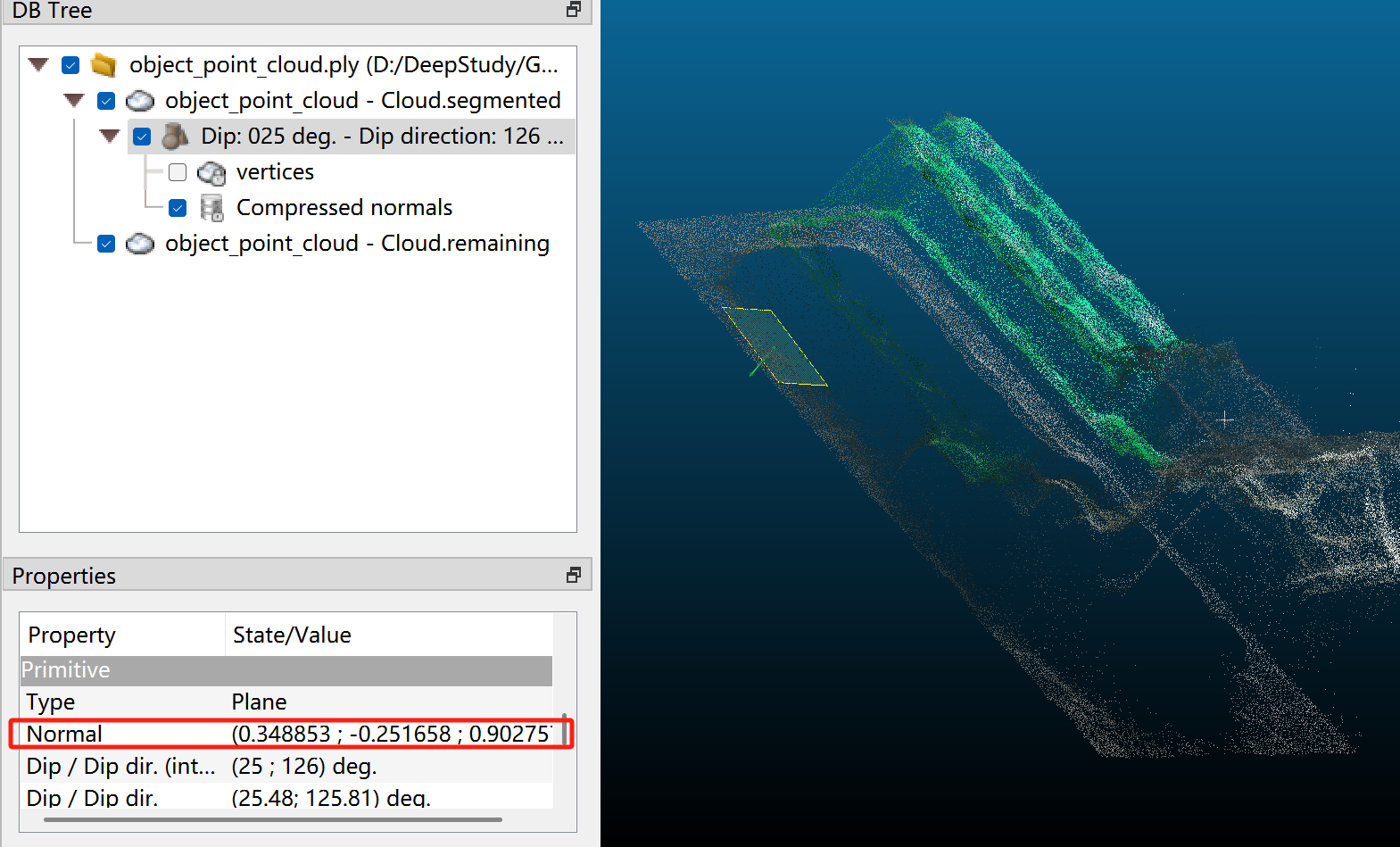
法线与 Z+ 方向(向上)相反,因此对象的 Z+ 方向为 (-0.348853 0.251658 -0.902757)
8、为了获得对象的前进方向 (x+),我们使用点拾取工具选择一个方向
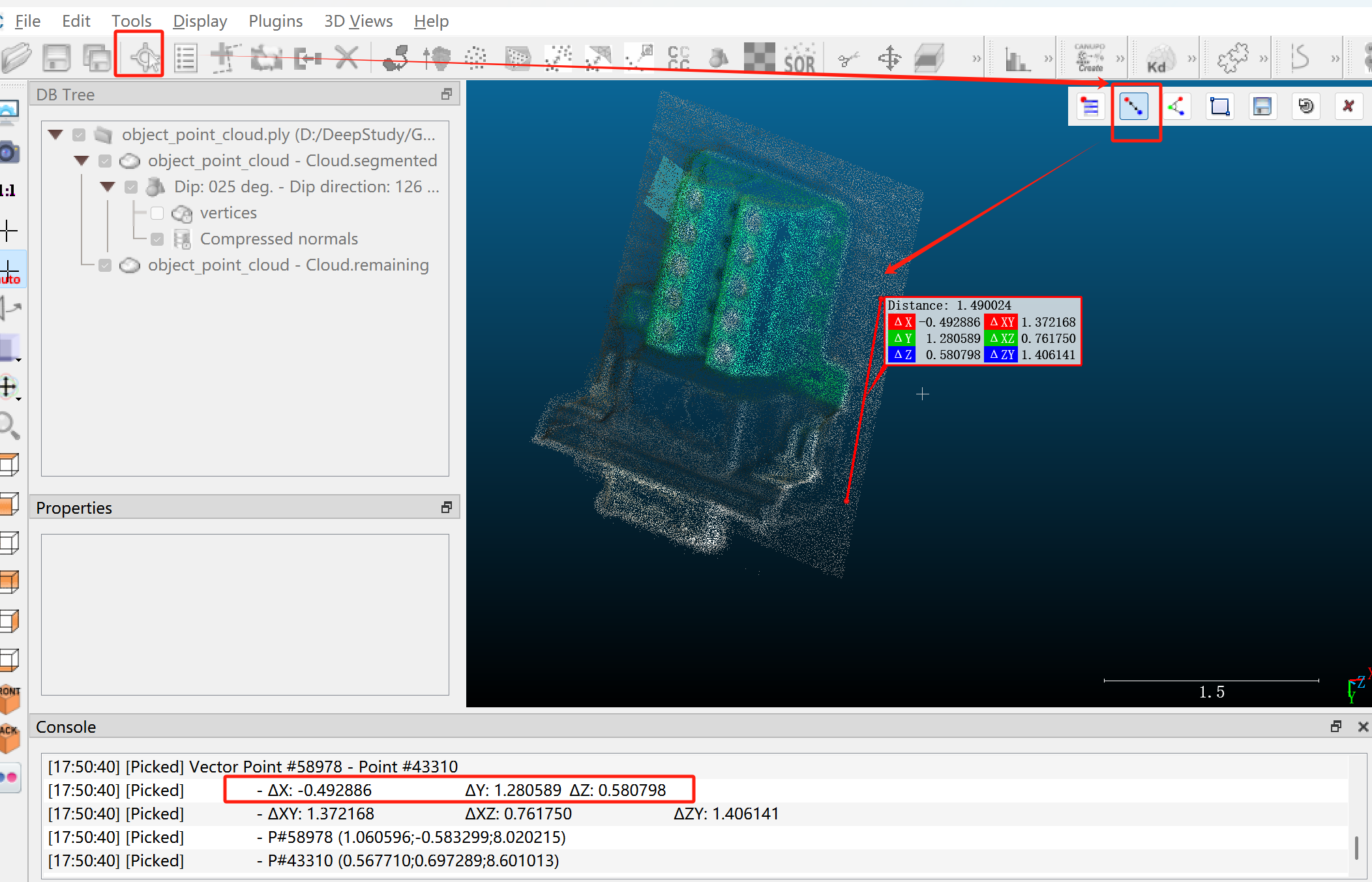 这个对象的前进方向是 (-0.492886 1.280589 0.580798)
这个对象的前进方向是 (-0.492886 1.280589 0.580798)
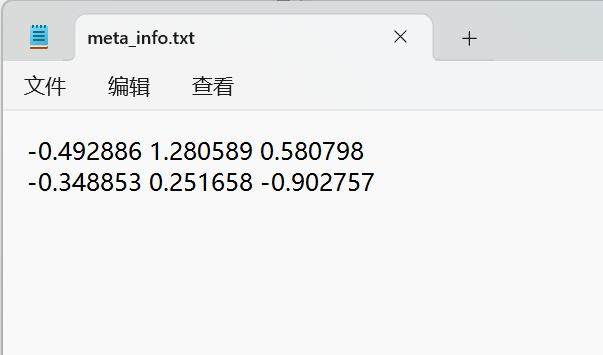
在Gen6D/data/custom/duanzi/目录下创建meta_info.txt将X正方向和Z正方向记录下来
9、生成识别后的视频
# 假如没有添加环境变量就需要ffmpeg.exe的完整路径
# --transpose 解决图片颠倒
python predict.py --cfg configs/gen6d_pretrain.yaml --database custom/XXX --video data/custom/video/XXX.mp4 --resolution 960 --transpose --output data/custom/XXX/test --ffmpeg ffmpeg.exe
# eg: python predict.py --cfg configs/gen6d_pretrain.yaml --database custom/duanzi --video data/custom/video/duanzi.mp4 --resolution 960 --transpose --output data/custom/duanzi/test --ffmpeg D:/DeepStudy/ffmpeg/bin/ffmpeg.exe
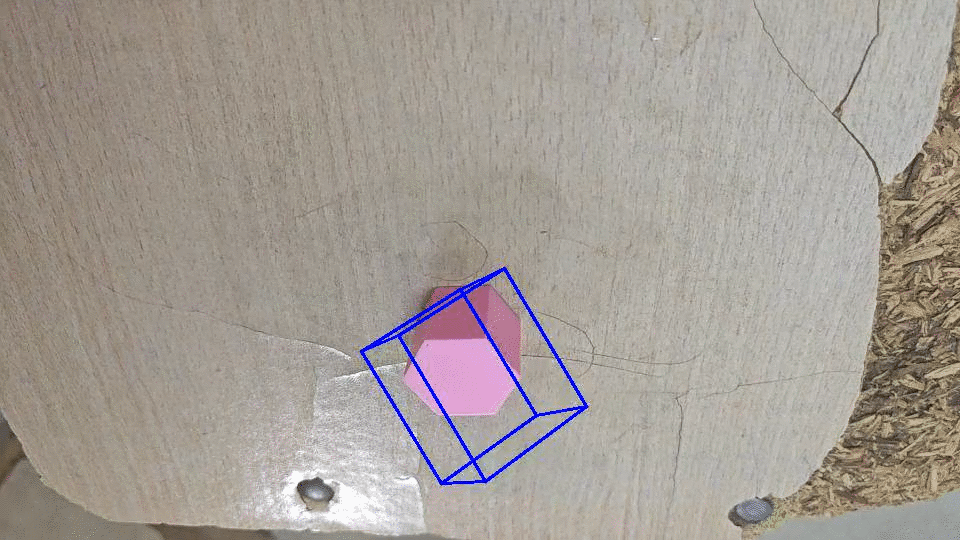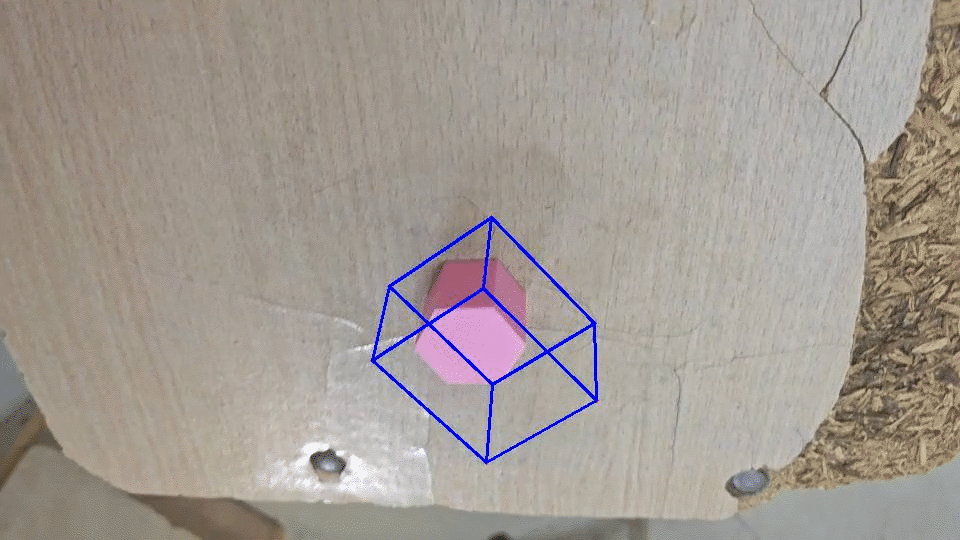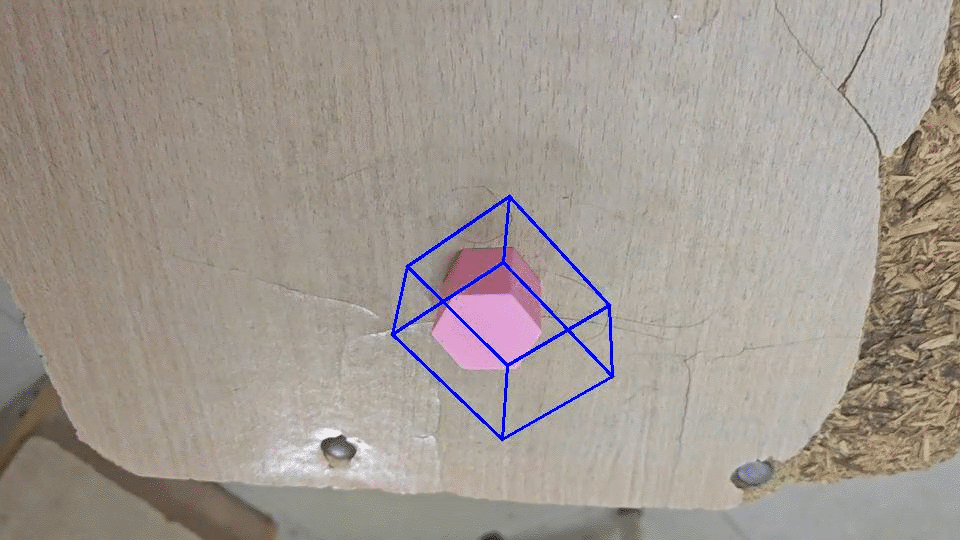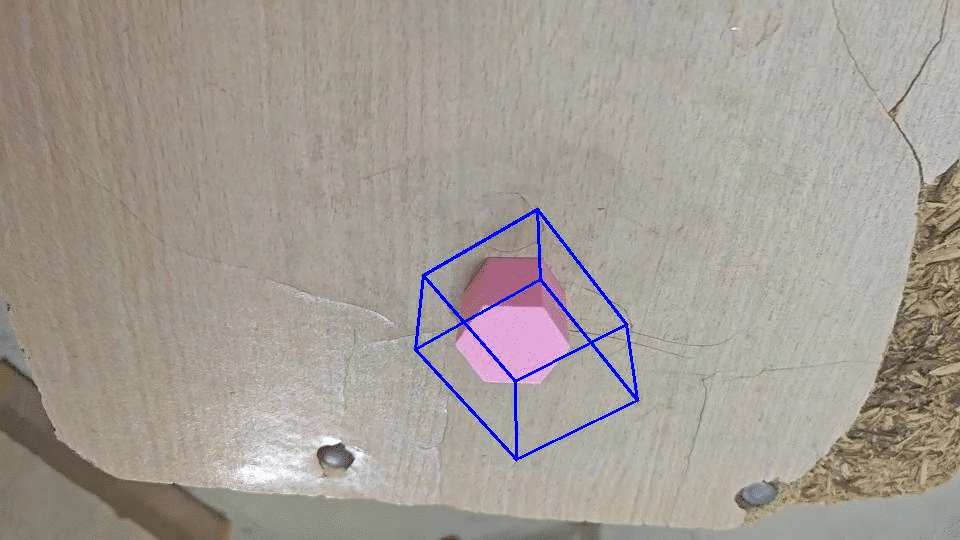
搞来搞去感觉效果一般,最后看看原作者的。

issue
我在nvidia app将显示改成Nvidia GPU感觉生成点云处理数据变慢了。

















 4496
4496






 到【灌水乐园】发言
到【灌水乐园】发言







