







模型名称INGRAM
代码:GitHub - bdi-lab/InGram: InGram: Inductive Knowledge Graph Embedding via Relation Graphs (ICML 2023)
注:我太懒了,有些不想手打,一些插图直接用组会汇报PPT和OneNote笔记的了,但大多都可以复制。
摘要
归纳知识图谱补全被认为是预测在训练过程中未观察到的新实体之间缺失的三联体的任务。虽然大多数归纳知识图谱补全方法假设所有实体都可以是新的,但它们不允许在推理时出现新的关系。这个限制禁止现有的方法适当地处理现实世界的知识图谱,其中新的实体伴随着新的关系。在本文中,我们提出了一种归纳知识图谱嵌入方法INGRAM,它可以在推理时生成新关系和新实体的嵌入。给定一个知识图谱,我们将关系图定义为由关系和它们之间的亲和权值组成的加权图。在关系图和原始知识图谱的基础上,INGRAM学习如何利用注意机制聚合相邻嵌入来生成关系嵌入和实体嵌入。实验结果表明,在不同的归纳学习场景下,INGRAM优于14种不同的最先进的方法。
一、研究现状和目的
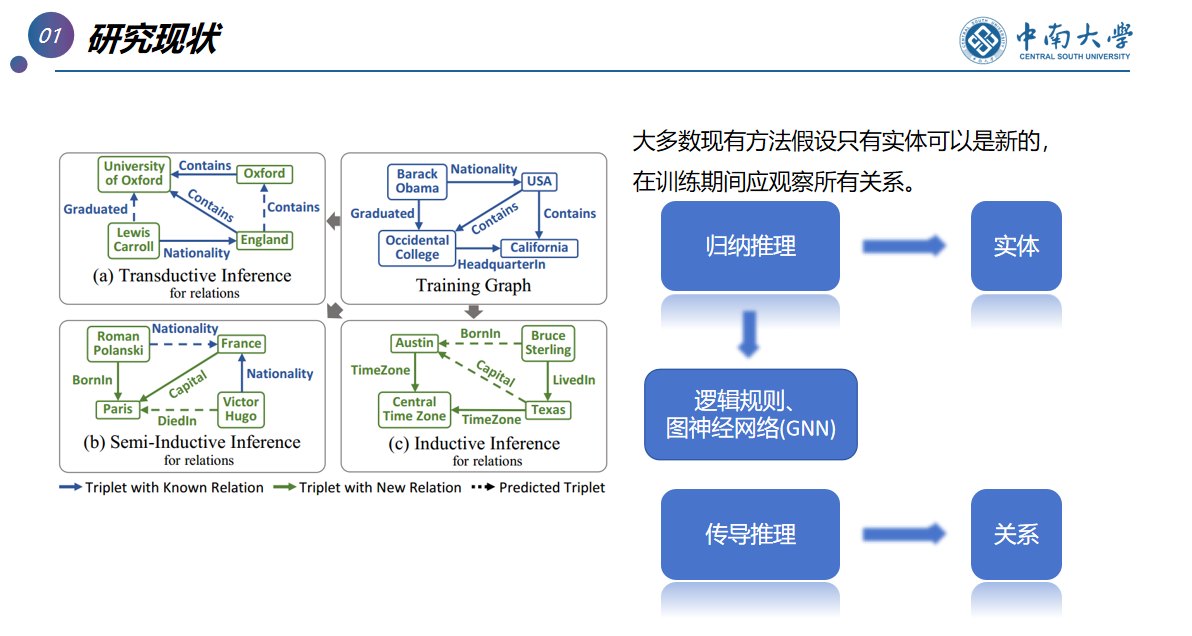
对实体,归纳推理
对关系,传导推理
目的:归纳知识图谱嵌入---------->知识图谱补全
二、相关知识
1、关系图:由关系和它们之间的亲和权值组成的加权图。(图的一种形式,其中节点表示实体,边表示实体之间的关系,边上还可以有权重,用于表示关系的强度或重要性)
2、关系间的亲和权值:用于量化两个实体(节点)之间关系强度的数值。
3、加权图:边上带有权重(weight)的图,图的形式可以是无向图或有向图,权重可以用于表示边的强度、距离、成本、容量等。
4、注意力机制:在处理某个数据点(如词或像素)时,根据其重要性对其他相关数据点进行加权,从而集中关注最相关的信息,从而提高模型的性能。
5、嵌入:将知识图谱中的节点(实体)和边(关系)映射到低维向量空间中,嵌入不仅能捕捉实体和关系的语义信息,还能使复杂的图结构变得易于操作和分析。
6、聚合:对每个节点,根据邻居节点的嵌入和对应的注意力权重进行加权求和,从而得到该节点的新嵌入。
7、嵌入对知识图谱补全的作用:
(1)嵌入技术通过将知识图谱中的实体和关系映射到低维向量空间中,捕捉了其语义和结构特征,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









