







 本文档详细介绍了如何在百度AIStudio平台上利用PaddlePaddle框架,结合CCPD车牌数据集,制作VOC格式数据集,进行模型训练,并最终实现车牌检测。从数据集的准备、环境配置、模型训练到模型使用,每个步骤都有清晰的操作指导和代码示例。
本文档详细介绍了如何在百度AIStudio平台上利用PaddlePaddle框架,结合CCPD车牌数据集,制作VOC格式数据集,进行模型训练,并最终实现车牌检测。从数据集的准备、环境配置、模型训练到模型使用,每个步骤都有清晰的操作指导和代码示例。
一、百度AI Studio
- AI Studio是百度推出的基于PaddlePaddle框架的一站式深度学习平台,提供Jupyter notebook的定制修改版本的编程环境,并且提供免费GPU算力加速模型开发。
- AI Studio官网
https://aistudio.baidu.com/aistudio
二、车牌数据集(CCPD)
- 下载地址
https://pan.baidu.com/s/1JSpc9BZXFlPkXxRK4qUCyw - 提取码
ol3j
三、VOC格式的数据集的制作
- 标注车牌数据集
可以使用labelImg或者labelme
工具(labelImg)下载链接:
https://pan.baidu.com/s/1GNFQ466fYP_SzrW5CvPUFQ
提取码:askg - 制作的文件结构(voc目录下)

- 标注过程
①下载标注工具
②打开标注工具,点击Open Dir,打开JPEGImages文件夹,载入图片,并选择Save Dir为上Annotations
③点击Create RectBox,就可以进行标注
④输入标签名称,点击OK
⑤点击Save,保存XML文件
⑥按照上面步骤,重复操作(至少标注500以上)
⑦效果如下

四、使用AI Studio创建环境
- 进入AI Studio的官网
可以需要进行账号的注册 - 创建项目
在主界面上,点击项目,进入一个新的界面后,点击创建项目
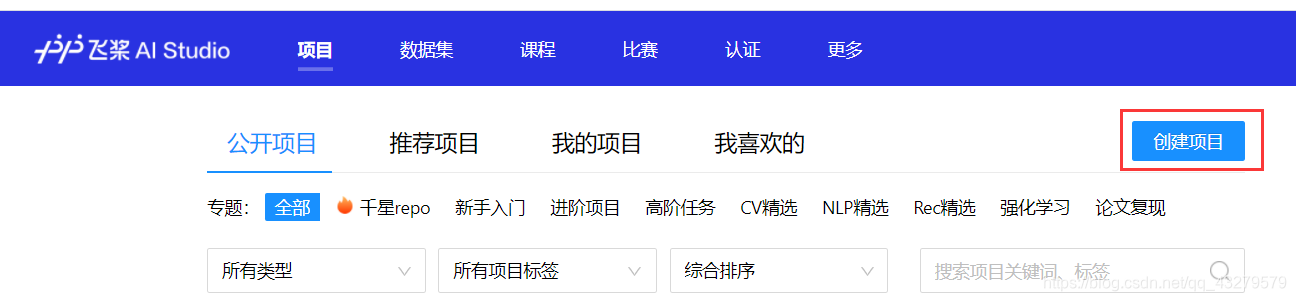
选择需要使用的类型(本次选择Notebook)
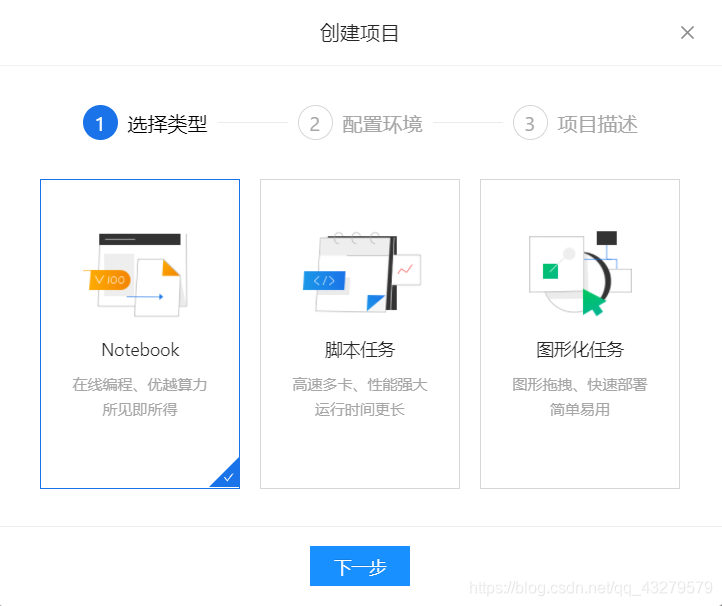
项目框架的选择
本项目框架版本为PaddlePaddle 1.8.0
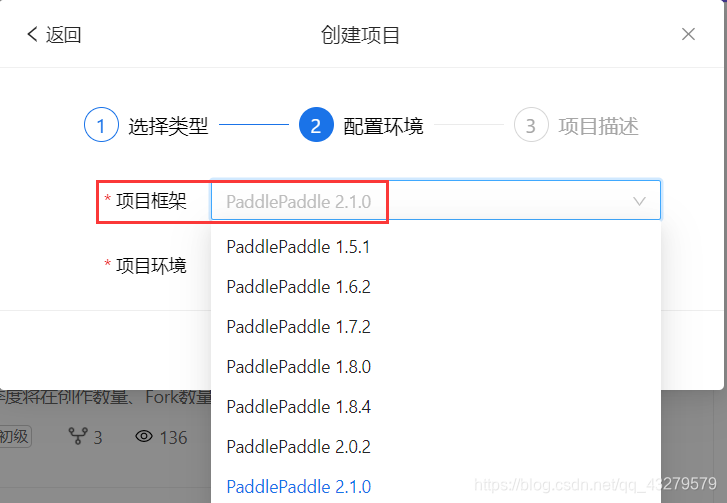
启动项目,选择运行环境
五、数据集配置
- 下载PaddleDetection的整个框架
下载地址:https://pan.baidu.com/s/1yS9U88OcLIQMyc8Cn2Q7DQ
提取码:qaxe - 在voc/ImageSets下创建一个Main文件夹,并且在Main目录下创建一个label_list.txt,里面存放标注的标签,此处标签为plate
- voc目录下,创建一个create_list.py对数据集进行划分
具体代码内容如下#create_list代码如下: import os import random trainval_percent = 0.95 # 训练集验证集总占比 train_percent = 0.9 # 训练集在trainval_percent里的train占比 xmlfilepath = './Annotations' txtsavepath = './ImageSets/Main' total_xml = os.listdir(xmlfilepath) print(total_xml) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('./ImageSets/Main/trainval.txt', 'w') ftest = open('./ImageSets/Main/test.txt', 'w') ftrain = open('./ImageSets/Main/train.txt', 'w') fval = open('./ImageSets/Main/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close() - voc目录下,创建一个list.py
#list.py代码如下: import os import re import random devkit_dir = './' output_dir = './' def get_dir(devkit_dir, type): return os.path.join(devkit_dir, type) def walk_dir(devkit_dir): filelist_dir = get_dir(devkit_dir, 'ImageSets/Main') annotation_dir = get_dir(devkit_dir, 'Annotations') img_dir = get_dir(devkit_dir, 'JPEGImages') trainval_list = [] train_list = [] val_list = [] test_list = [] added = set() for _, _, files in os.walk(filelist_dir): for fname in files: print(fname) img_ann_list = [] if re.match('trainval.txt', fname): img_ann_list = trainval_list elif re.match('train.txt', fname): img_ann_list = train_list elif re.match('val.txt', fname): img_ann_list = val_list elif re.match('test.txt', fname): img_ann_list = test_list else: continue fpath = os.path.join(filelist_dir, fname) for line in open(fpath): name_prefix = line.strip().split()[0] print(name_prefix) added.add(name_prefix) #ann_path = os.path.join(annotation_dir, name_prefix + '.xml') ann_path = annotation_dir + '/' + name_prefix + '.xml' print(ann_path) #img_path = os.path.join(img_dir, name_prefix + '.jpg') img_path = img_dir + '/' + name_prefix + '.jpg' assert os.path.isfile(ann_path), 'file %s not found.' % ann_path assert os.path.isfile(img_path), 'file %s not found.' % img_path img_ann_list.append((img_path, ann_path)) print(img_ann_list) return trainval_list, train_list, val_list, test_list def prepare_filelist(devkit_dir, output_dir): trainval_list = [] train_list = [] val_list = [] test_list = [] trainval, train, val, test = walk_dir(devkit_dir) trainval_list.extend(trainval) train_list.extend(train) val_list.extend(val) test_list.extend(test) #print(trainval) with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval: for item in trainval_list: ftrainval.write(item[0] + ' ' + item[1] + '\n') with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain: for item in train_list: ftrain.write(item[0] + ' ' + item[1] + '\n') with open(os.path.join(output_dir, 'val.txt'), 'w') as fval: for item in val_list: fval.write(item[0] + ' ' + item[1] + '\n') with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest: for item in test_list: ftest.write(item[0] + ' ' + item[1] + '\n') if __name__ == '__main__': prepare_filelist(devkit_dir, output_dir) - 运行上面创建的两个py文件,运行结果如下
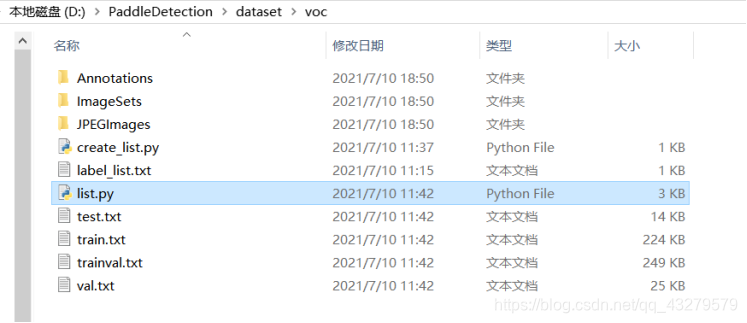
- 将上面标注好的voc数据集,放到PaddleDetection/dataset目录下
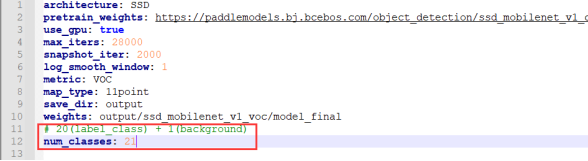
- 修改./PaddleDetection/Configs/ssd/ssd_mobilenet_v1_voc.yml文件
将num_classes的值修改为2,2表示1个标签加一个背景
- 修改./PaddleDetection/ppdet/data/source/voc.py文件
将文件中的pascalvoc_label()函数内容修改为前面label_list.txt中的内容

- 将整个压缩上传到AI Studio创建的项目中
六、模型训练
- 解压上面上传的PaddleDetection项目
- 相关配置
终端进入PaddleDetection目录安装Python依赖 pip install -r requirements.txt 配置Python环境变量 env PYTHONPATH=/home/aistudio/PaddleDetection 测试环境 export PYTHONPATH=`pwd`:$PYTHONPATH python ppdet/modeling/tests/test_architectures.py
补充:当遇到Could not install packages due to an EnvironmentError: HTTPSConnectionPool的问题的时候

解决方法:
对requirements.txt内容进行修改

- 训练
训练前可能需要先下载paddlepaddle-gpu,可以先执行看需要不需要安装,提示缺少paddlepaddle-gpu,就自行安装即可
命令如下pip install paddlepaddle-gpu

开始训练
python python -u tools/train.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --use_tb=True --eval
默认训练总轮数为28000轮。可以自行修改训练的轮数,位置为修改模型类别的文件。
训练过程
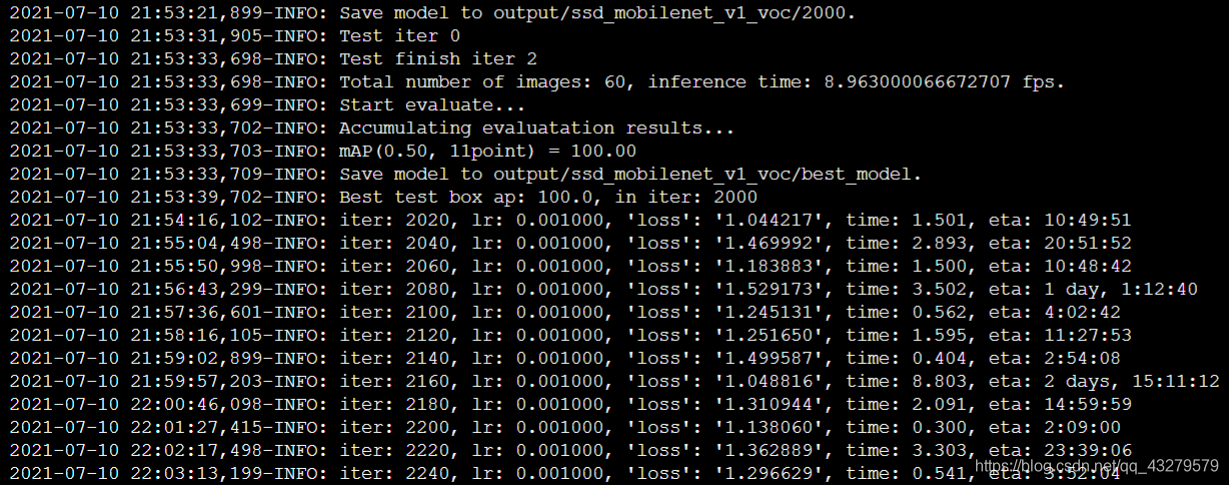
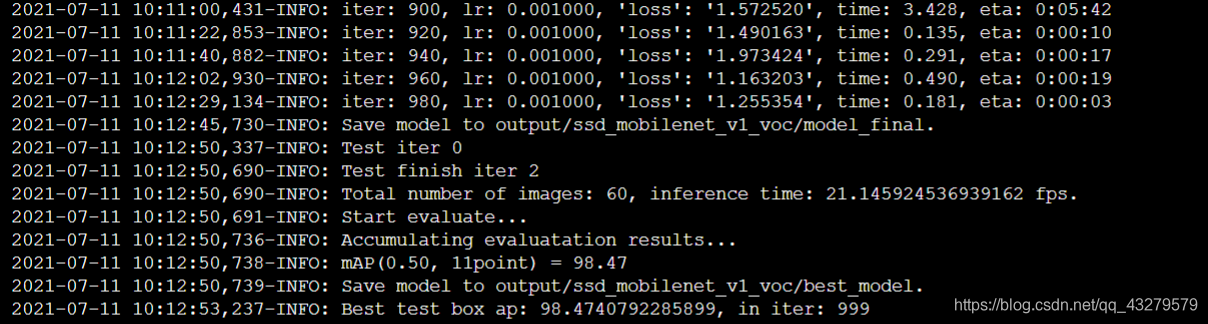
七、模型使用
- 模型识别过程
python tools/infer.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --infer_img=/home/aistudio/1.jpg(1.jpg为自己上传的测试图片)
- 识别结果

定位的结果可能框选的没有那么准确,原因可能是标注的时候可能没有标注的很好。并且这个模型训练轮数也不是使用的默认训练轮数,而是自定义的训练轮数。
参考链接
https://blog.youkuaiyun.com/han422858897/article/details/118273873

















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









