







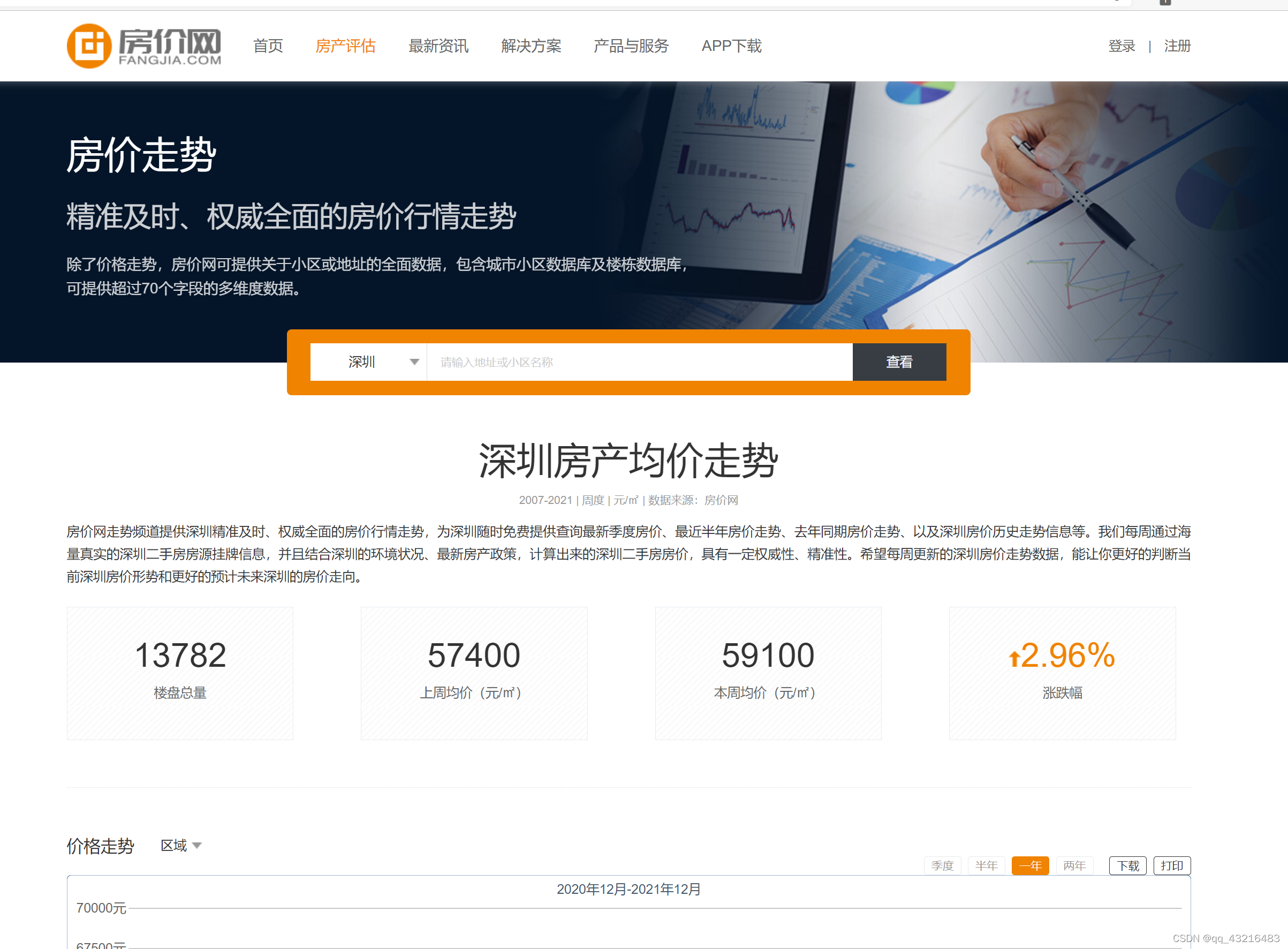
这是我们python课程要求我们制作一个项目,用python爬取结果并作数据展示。我们使用requests的方法对房价的信息做了爬取,一下就是我们所爬取的网页
我们做这个项目主要分为以下几个步骤
1 网页爬取过程
我们使用类的方法经行了封装在直接输入城市名的时候就可以直接get到数据
class reptile:
def __init__(self):
self.__city = '天津'
self.__header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43'
}
def up_data(self, city):
if city != '':
self.__city = city
else:
print('没有得到新的城市名。')
def write_in(self, data, *, fileName='', title='', time=False):
# 数据写入
flag = False
with open(fileName, 'w', encoding='utf-8') as fp:
if not title == '':
fp.write(title + '\n')
if time:
for i, j in data:
if flag:
fp.write('\n')
else:
flag = True
fp.write(str(get_really_time(i)) + ':')
fp.write(str(j))
else:
for i, j in data.items():
if flag:
fp.write('\n')
else:
flag = True
fp.write(i + ' ')
for k in j:
fp.write(k + ' ')
def show_all(self):
oneyear_m()
main()
def get_photo_data(self): # 获取目标城市的总体价格走势图的数据
url = 'http://' + get_first(self.__city) + '.fangjia.com/trend/yearData?'
param = {
'defaultCityName': self.__city,
'districtName': '',
'region': '',
'block': '',
'keyword': ''
}
res = requests.get(url=url, params=param, headers=self.__header).json()
data = res['series']
d = data[0]['data']
# 文件写入
self.write_in(d, fileName='zoushi.txt', time=True)
def get_which(self, choose='up'):
url = 'http://' + get_first(self.__city) + '.fangjia.com/zoushi'
page_txt = requests.get(url=url, headers=self.__header).text
if choose == 'up':
ex = '<div class="trend trend03">.*?<tbody>(.*?)<tbody>'
else:
ex = '<div class="trend trend03" style="border-bottom:none;">.*?<tbody>(.*?)</tbody>'
url_list = str(re. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









