




文章目录
感知机模型
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别。
感知机旨在求出将输入空间中的实例划分为两类的分离超平面。如果训练数据集是线性可分的,则感知机一定能求得分离超平面。如果是非线性可分的数据,则无法获得超平面。为了找出这个超平面,也就是确定感知机模型的参数和w,b。
算法描述
给定输入向量x,权重向量w,和偏移标量b感知机输出 o = σ ( < w , x > + b ) σ ( x ) = { 1 i f x > 0 − 1 o t h e r w i s e o=\sigma (<w,x>+b) \;\;\;\; \sigma(x) = \begin{cases} 1 & if\;x>0\\ -1 &otherwise \end{cases} o=σ(<w,x>+b)σ(x)={ 1−1ifx>0otherwise
< w , x > <w,x> <w,x>表示w和x做内积,感知机是个二分类问题, x > 0 x>0 x>0取1,其余情况取-1.
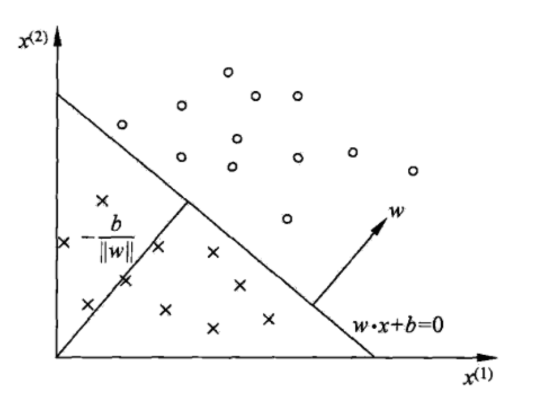
对于特征空间中有一个超平面 w x + b = 0 wx+b=0 wx+b=0,其中 w w w是超平面的法向量, b b b是超平面的截距。这个超平面将特征空间分为两部分,位于两部分的特征向量被分为正负两类,因此称超平面S为分离超平面。
- 正类区域: w ⋅ x + b > 0 w⋅x+b>0 w⋅x+b>0
- 负类区域: w ⋅ x + b < 0 w⋅x+b<0 w⋅x+b<0
法向量 w w w 始终垂直于超平面,指向超平面的“正方向”。
调整 b b b 可以平移超平面,使其靠近或远离原点。
《深度学习入门》的解释
将输入想成不同的信号,每个神经元会计算传送过来的信号总和,只有当这个总和超过某个界限值 θ \theta θ时,才会被激活。
比如 w 1 x 1 + w 2 x 2 ≤ θ w_1x_1+w_2x_2\leq \theta w1x1+w2x2≤θ将 θ \theta θ移动后使用 b = − θ b=-\theta b=−θ表示原来的式子 b + w 1 x 1 + w 2 x 2 ≤ 0 b+w_1x_1+w_2x_2\leq 0 b+w1x1+w2x2≤0
o = σ ( < w , x > + b ) σ ( x ) = { 1 i f x > 0 − 1 o t h e r w i s e o=\sigma (<w,x>+b) \;\;\;\; \sigma(x) = \begin{cases} 1 & if\;x>0\\ -1 &otherwise \end{cases} o=σ(<w,x>+b)σ(x)={ 1−1ifx>0otherwise
激活函数: σ \sigma σ函数将输入信号的总和转换为输出信号
激活函数的作用:决定如何来激活信号的总和
:
每个神经元对应一个偏置:每个神经元的计算都需独立调节其激活阈值(偏置)。
权重控制输入信号的重要性,偏置调整神经元被激活的容易程度。
训练感知机
假设当前是第i个样本, y i y_i yi是该样本的真是标号,假设+1和-1, y ^ = < w , x i > + b \hat y = <w,x_i>+b y^=<w,xi>+b表示线性模型预测的结果 y ^ \hat y y^。
分类判断:如果真实值 y i y_i yi和 y ^ \hat y y^异号,说明感知机模型预测的结果错误。此时需要更新参数w与b,使用该错误样本来更新权重 w = w + y i x i w=w+y_ix_i w=w+yixi,标量偏差 b = b + y i b=b+y_i b=b+yi。
终止条件:所有的类都分类正确。

这个算法参数更新部分实际上是使用的梯度下降算法,在这里批量大小为1也就是每一次拿一个样本去算梯度。
损失函数的选择
核心:最小化误分类样本的损失,修改参数向正确分类方向更新
李沐视频里介绍的损失函数
损失函数(单样本)为 l ( y , x , w ) = m a x ( 0 , − y < w , x > ) l(y,x,w)=max(0,-y<w,x>) l(y,x,w)=max(0,−y<w,x>),如果分类正确了预测值和真实值一致 − y < w , x > -y<w,x> −y<w,x>的结果为负数,那么max取0;如果分类错误,预测值和真实值不一致 − y < w , x > -y<w,x> −y<w,x>的结果是正数,那么max取 − y < w , x > -y<w,x> −y<w,x>。
李航书中介绍的损失函数
损失函数的一个自然选择是误分类点的总数,但是这样的损失函数不是参数w,b的连续可导函数,不能求导优化。
损失函数的另一个选择是误分类点到超平面S的总距离。
- 一点到超平面的距离公式: d = ∣ w ⋅ x 0 + b ∣ ∣ ∣ w ∣ ∣ d=\frac{|w·x_0+b|}{||w||} d=∣∣w∣∣∣w⋅x0+b∣、
- 函数距离(Functional Distance)是点 x 0 x_0 x0 到超平面 S : w ⋅ x + b = 0 S:w⋅x+b=0 S:w⋅x+b=0的 未规范化距离: 函数距离 = w ⋅ x 0 + b 函数距离=w⋅x_0+b 函数距离=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









