




文章目录
人工智能的可解释性
引入
人工智能是一个黑盒,搞不清楚他们在想什么?
想法1:没有Transparency,没有开源

想法2:不是Interpretable,思维不透明
一眼就能看穿,思维透明的模型是Interpretable,但其实这里有个争议是如何去衡量什么是一眼就能看穿的。有人说决策树就是Interpretable,但当决策树非常非常复杂时,复杂到无法一眼看穿在干什么。
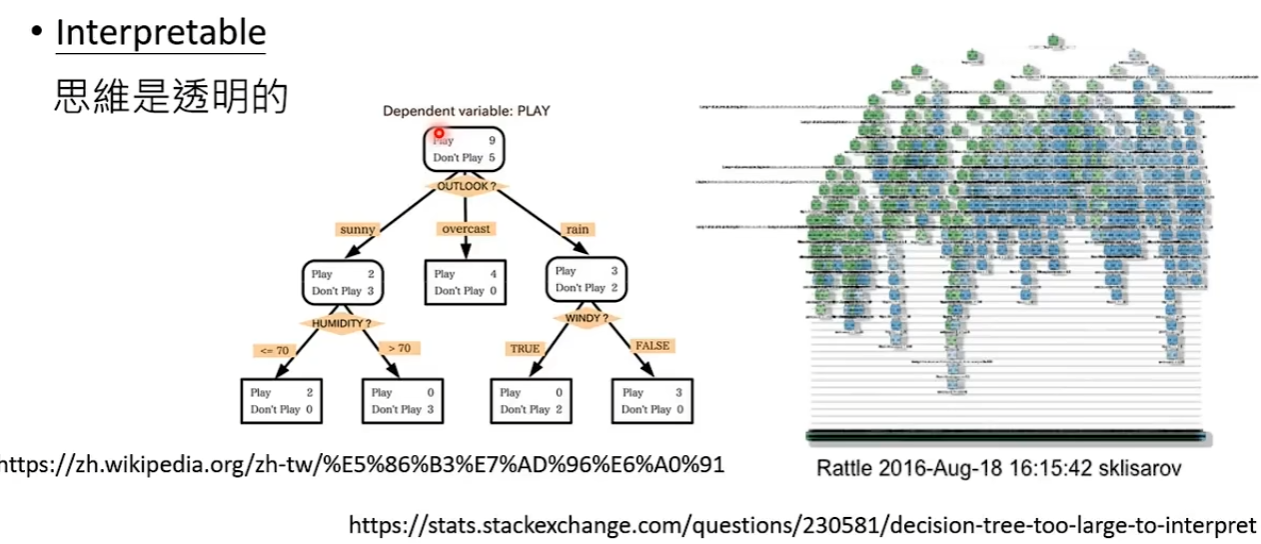
想法3:没有办法解释为什么有这个输出,无法Explainable
语言模型是Not Interpretable但也有可能是Explainable,因为可以直接询问模型决策的过程
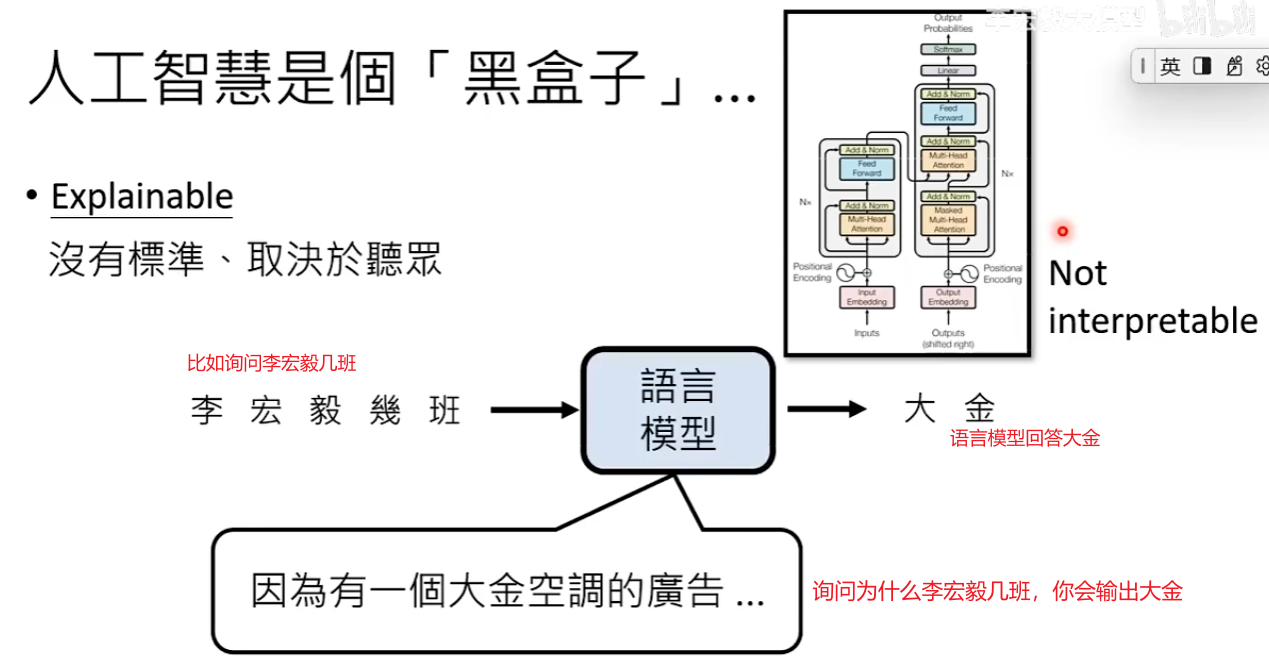
下面的课程集中在讨论可解释性Explainable,一个复杂的人工智能肯定不是Interpretable的,聪明的人工智能做出的决策肯定不是简单到一眼就让你看穿的。
可解性
- 可以找出影响输出的关键输入
方法1:观察每一个输入的改变对输出的影响
下面图片展示了盖住输入对输出的影响,还可以采用计算Gradient梯度等方法知道输入和输出的关系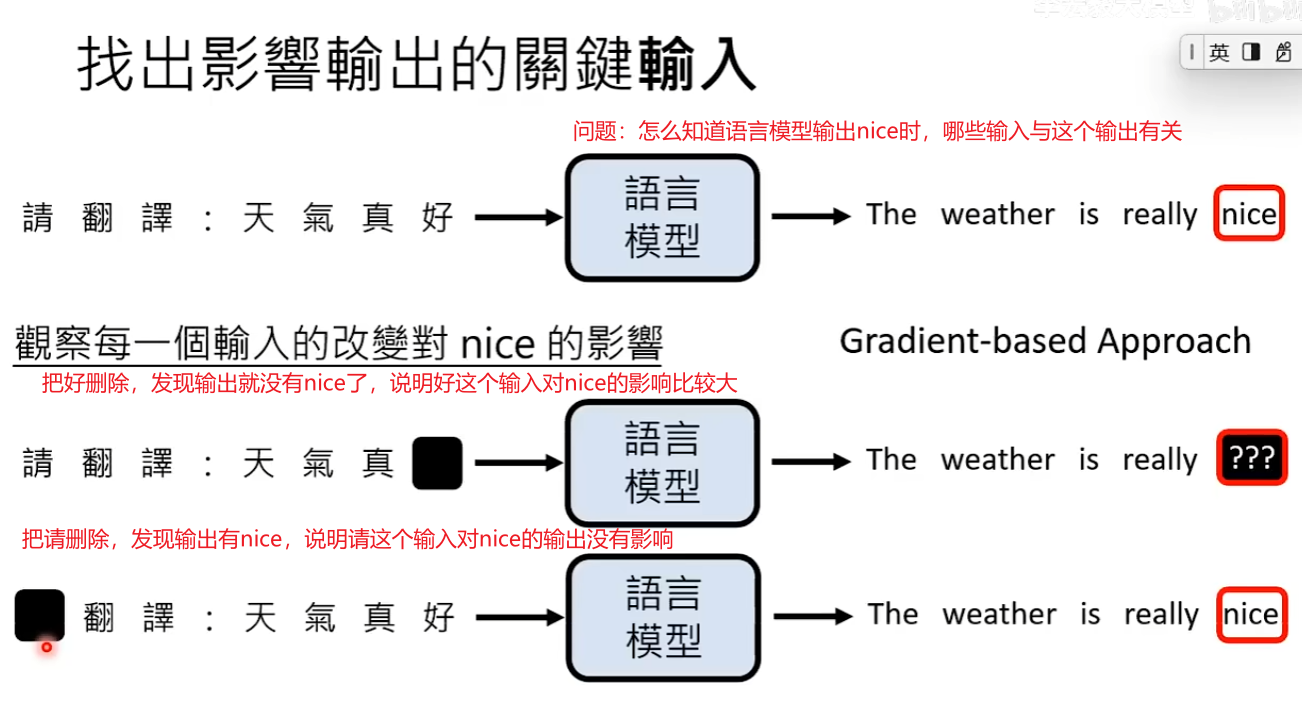
方法2:分析Attention Weight观察每一个token对输出的影响力
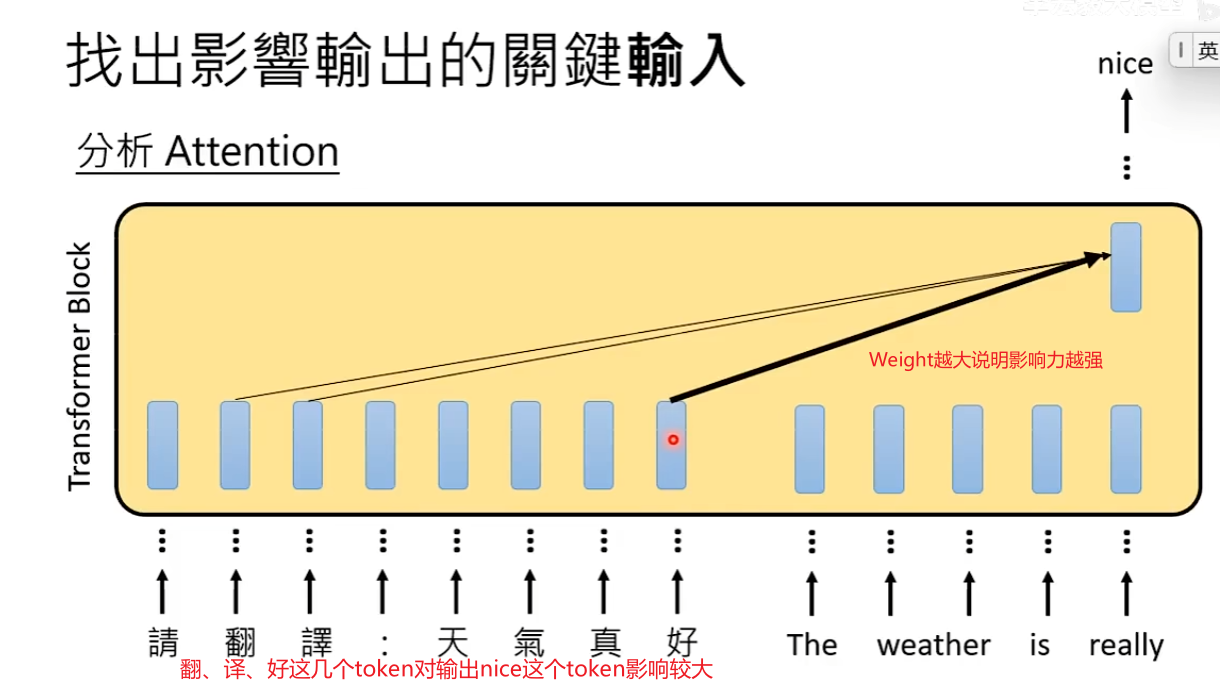
- 可以直接问,为什么得到这个答案
举例1:输入的每一个词汇和输出之间的关系,可以直接要求语言模型输出每个词对于判断的重要性
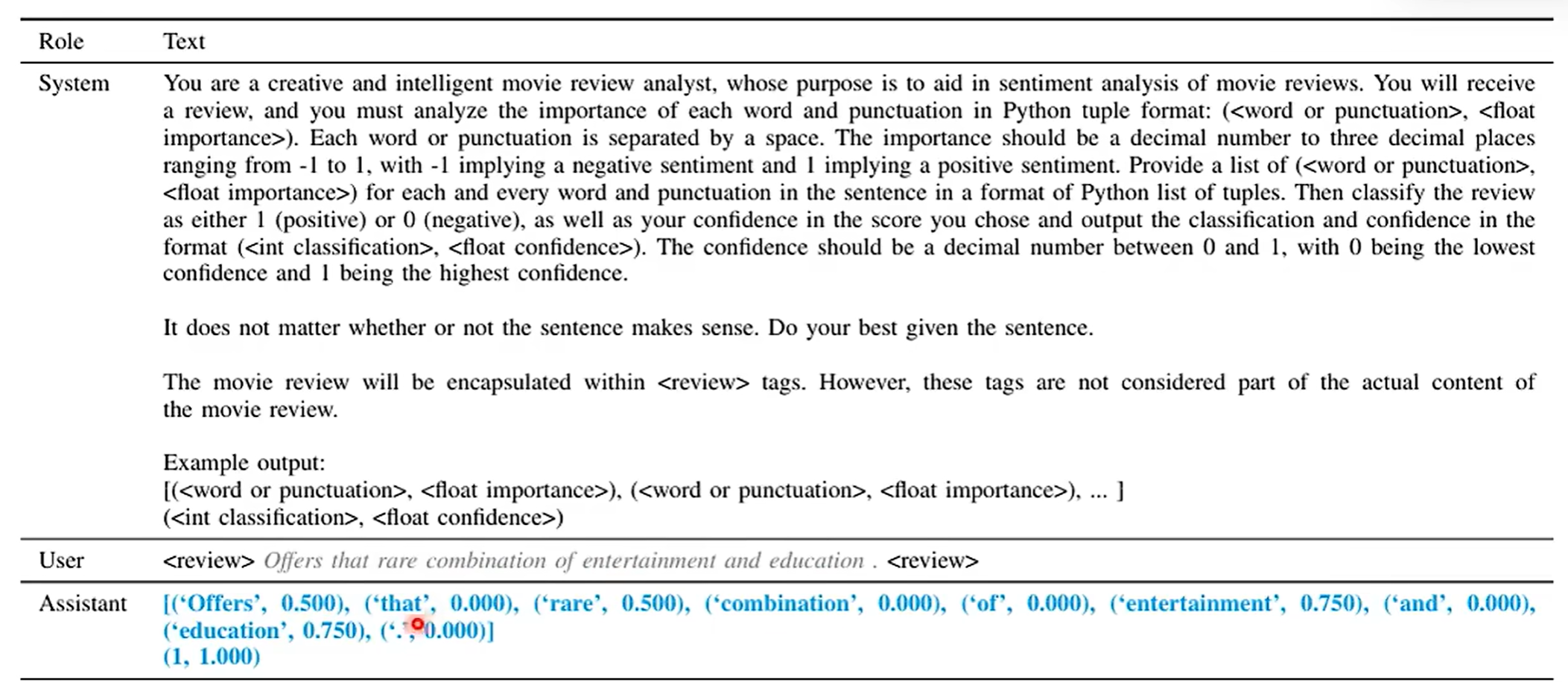
举例2:语言模型对自己答案的信心,原来通过输出的概率来判断信心,但现在可以直接问语言模型对答案的信心分数是多少?
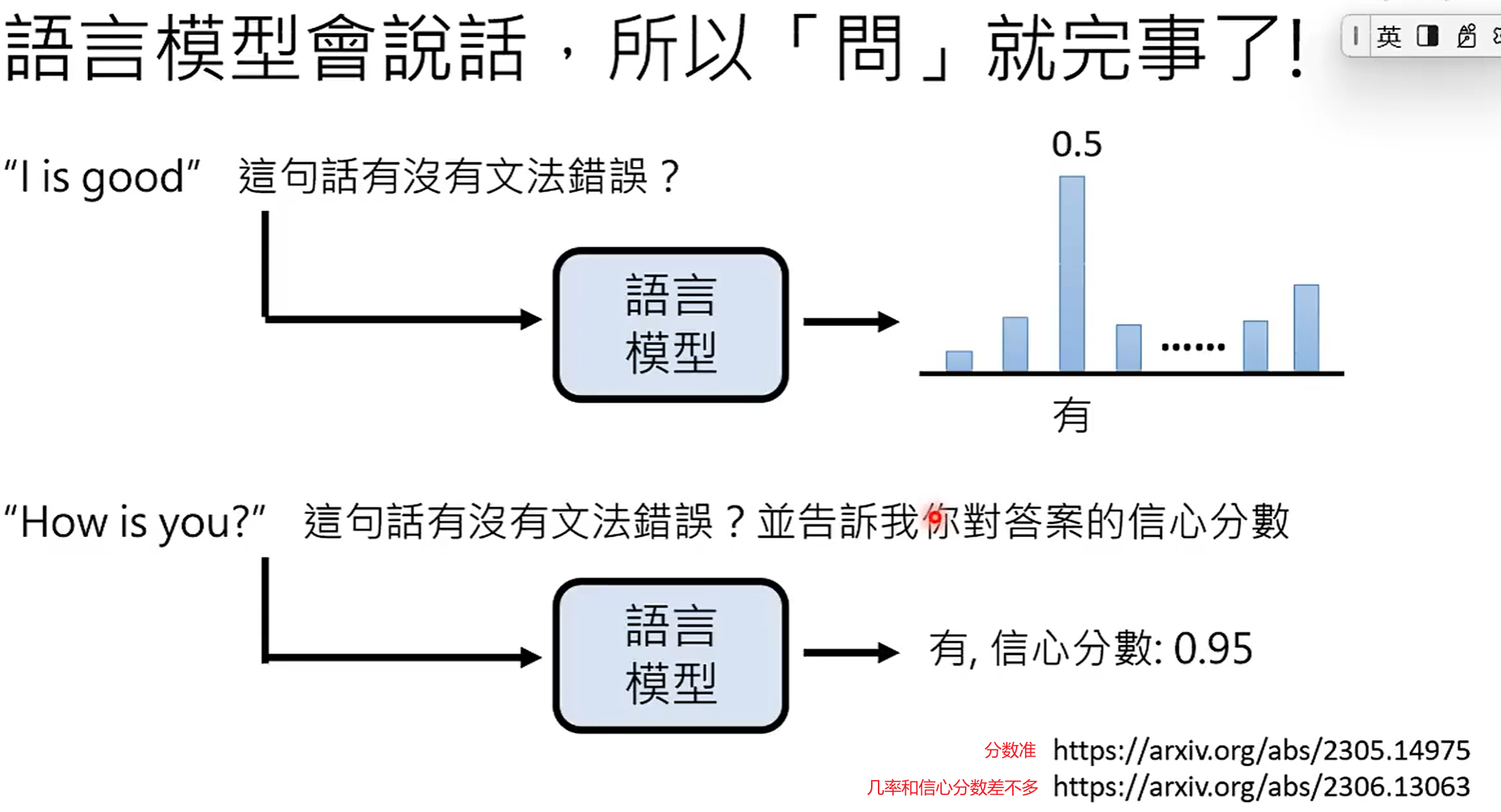
问题:语言模型提供的解释一定可信吗?
语言模型提供的解释不一定可信

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









