




文章目录
生成策略
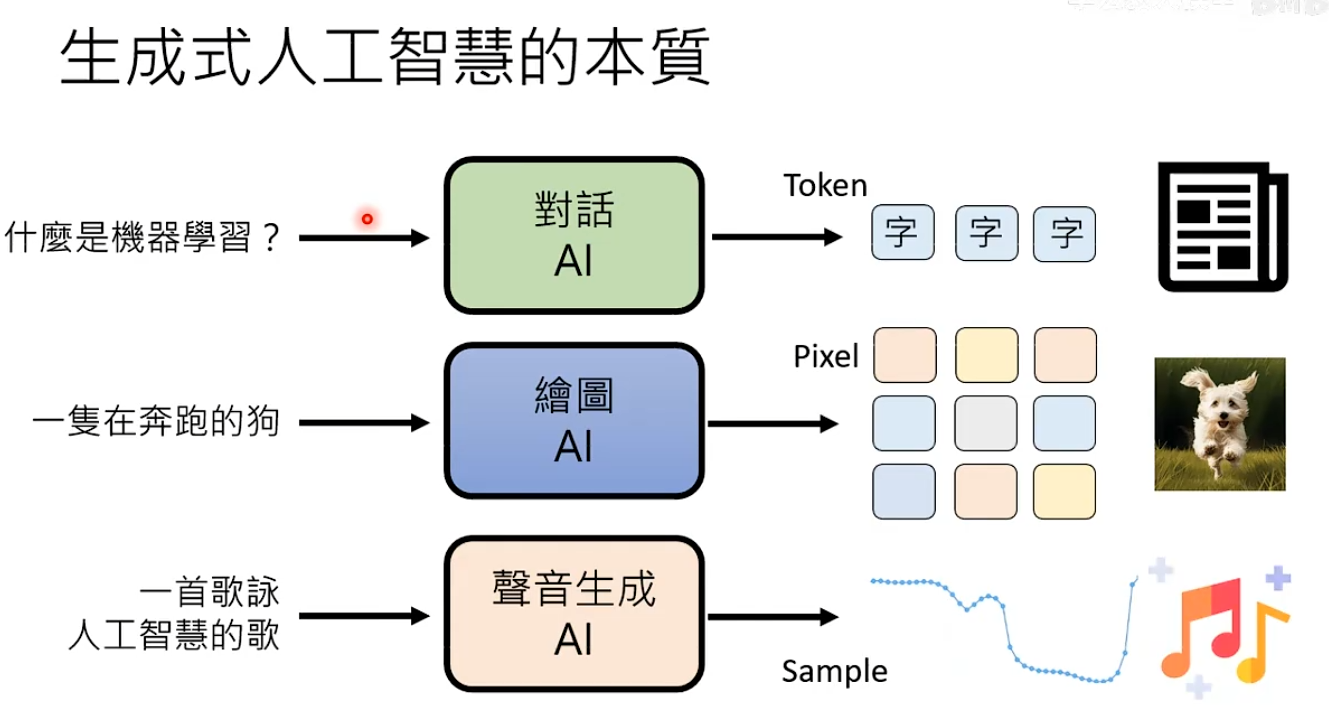
生成式AI:让机器产生复杂有结构的物件,比如文字、影响、声音等。
- 文字:一句话由token组成
- 影像:由一个一个像素构成,每个像素有多少颜色取决于BPP(Bit per Pixel)。
8BPP:256色,16BPP:65536色,24BPP:1670万色
- 声音:由取样点构成,每个点有多少数值取决于取样解析度
16KHZ取样率每一秒有16000个点

生成式人工智能的本质:给定条件后,生成式AI把基本单位用正确的排序组合起来
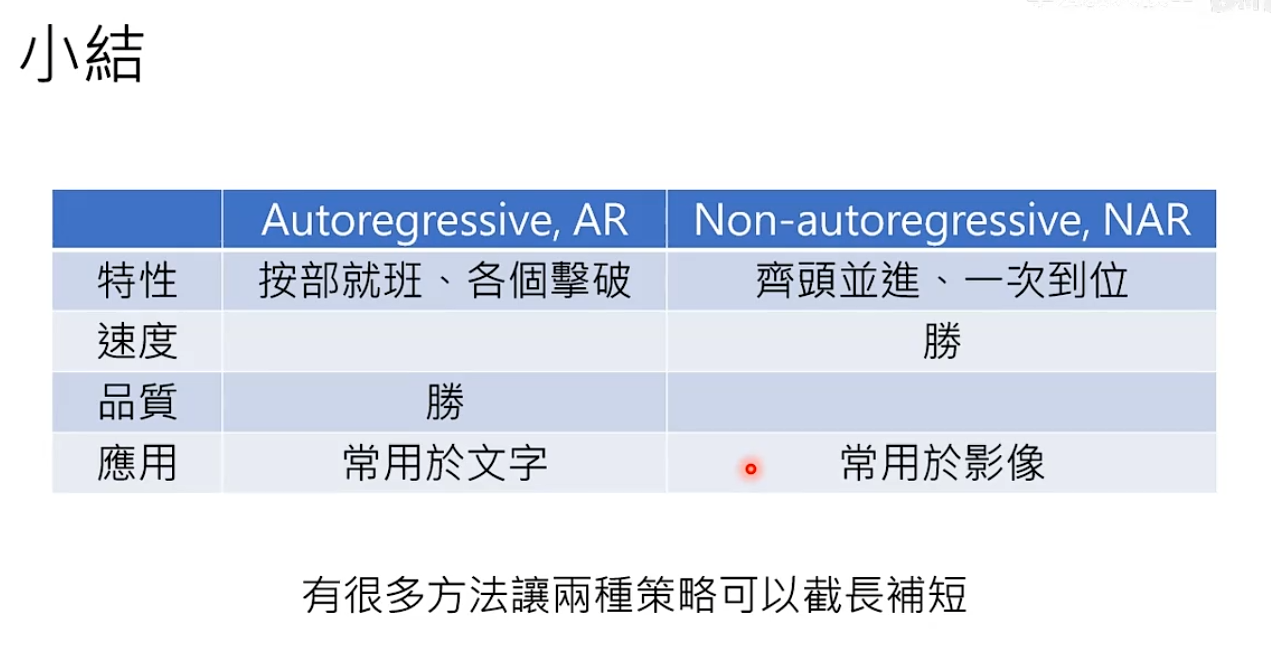
AR与NAR的总结
目前的做法是两种方法结合。
生成策略:Autoregressive Generation AR
文字接龙使用的生成策略是Autoregressive Generation,其实影像也可以进行像素接龙,声音也可以进行取样点接龙。但实际操作中,影像生成与语音生成不是采用接龙的方式。
Autoregressive Generation本质上的限制
每次产生一个基本单位时,只能按部就班生成
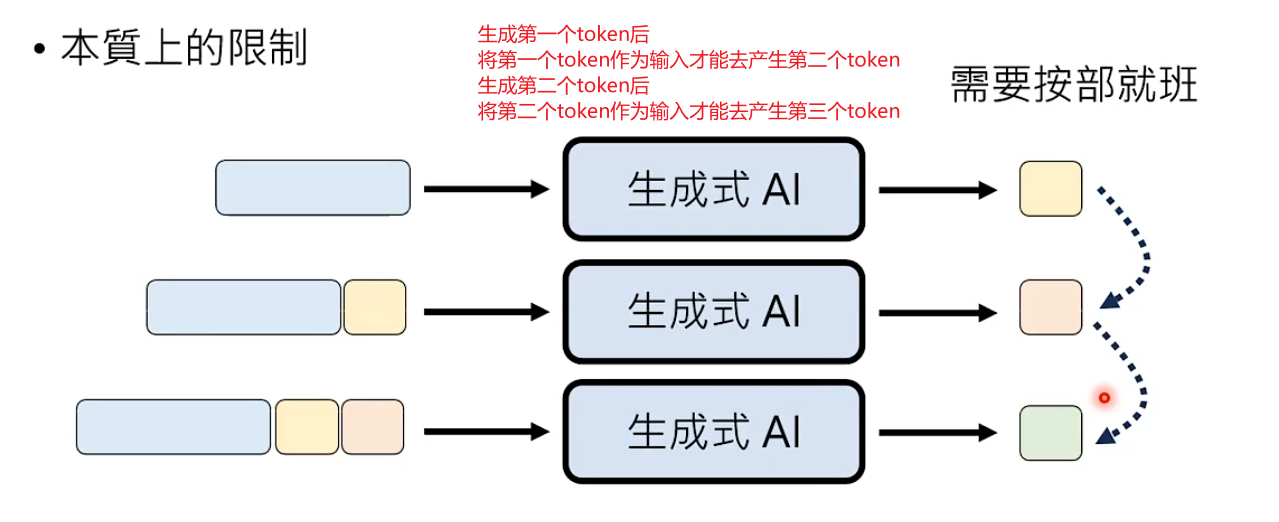
假设需要生成1024x1024解析度的图片,图片有100w个像素,那么需要做100w次像素接龙,生成成本和时间都太多了。生成语音采用这种策略也存在同样的问题。

生成策略:Non-autoregressive Generation NAR
NAR:不按部就班,一次同时生成所有基本单位,图像生成主流采用的方法。
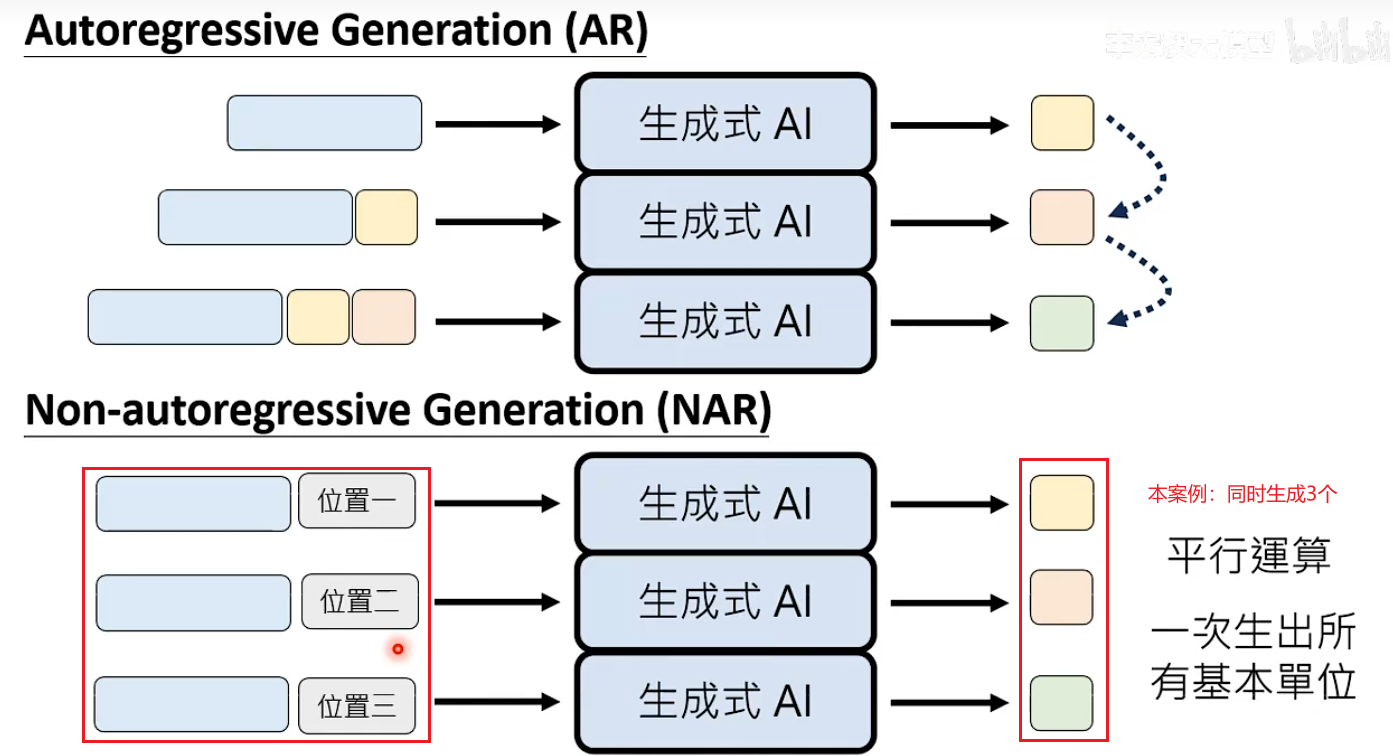
文字也可以用Non-autoregressive Generation的方式,思路是确定生成的基本单位数量。
方式1:给一个输入,让语言模型预测要自己回答的答案token数量。 - 影响生成的大小是固定的,所以就不需要实现预测。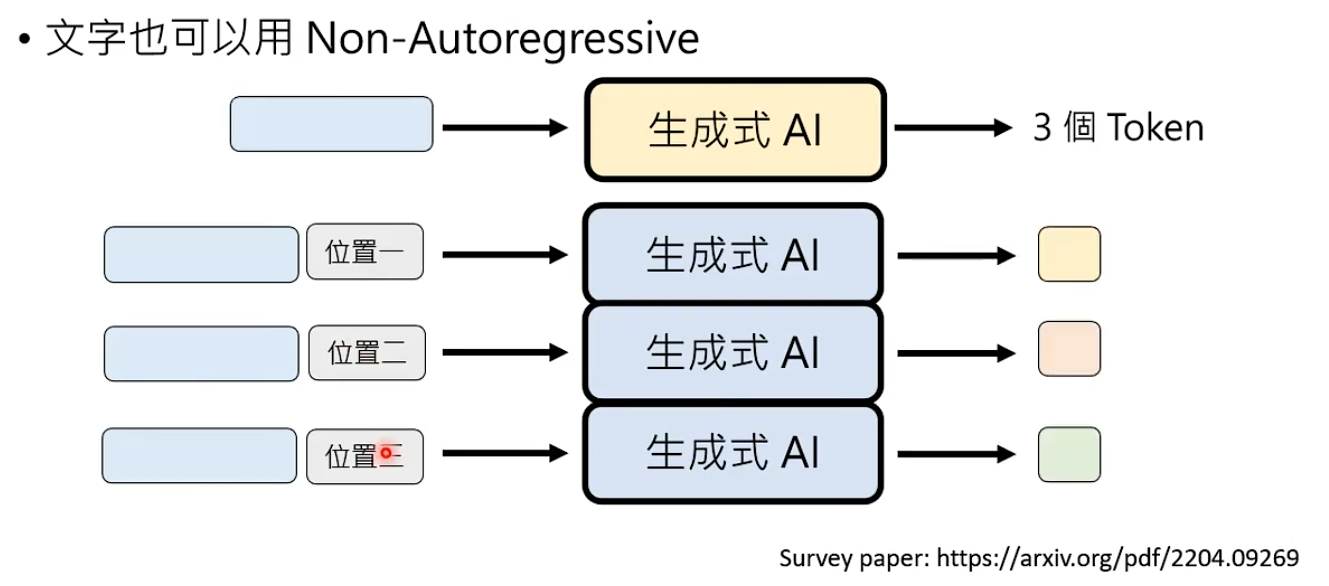
方式2:生成固定长度的答案,如果出现END这个token,那之后的答案丢掉就可以了。
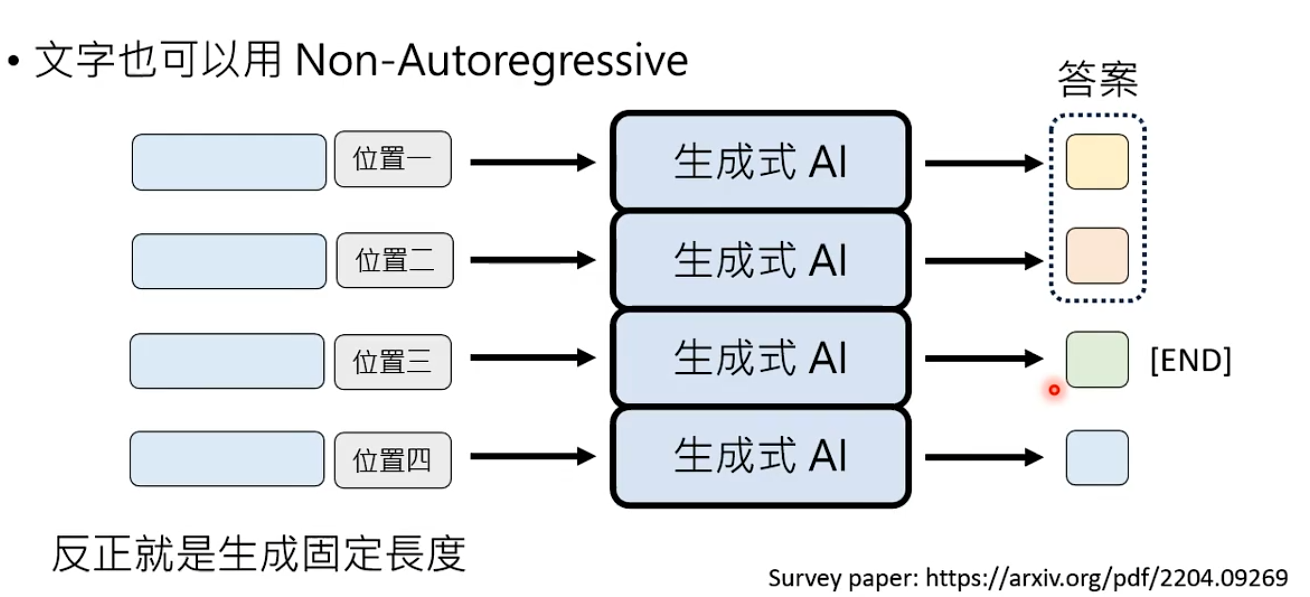
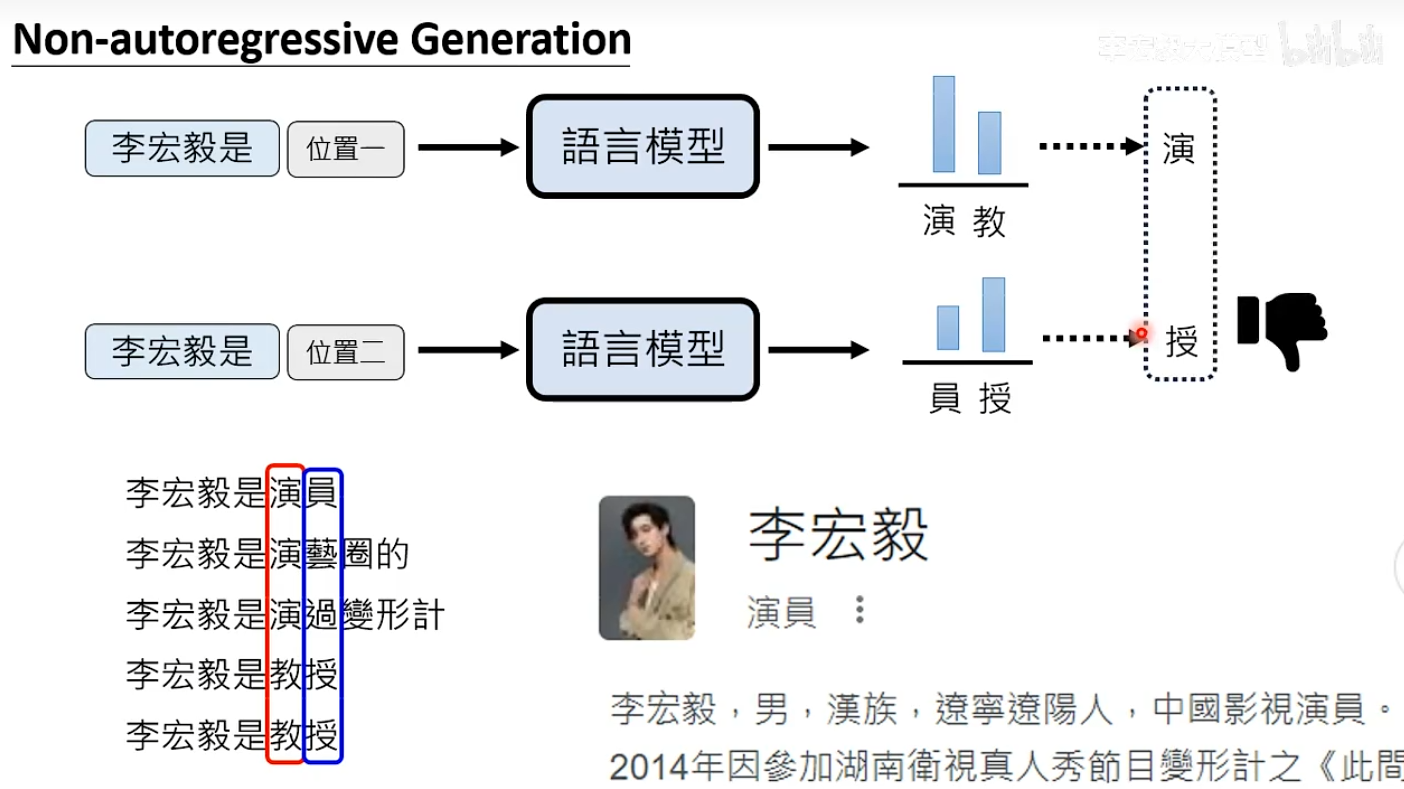
Non-Autoregressive Generation的质量存在问题
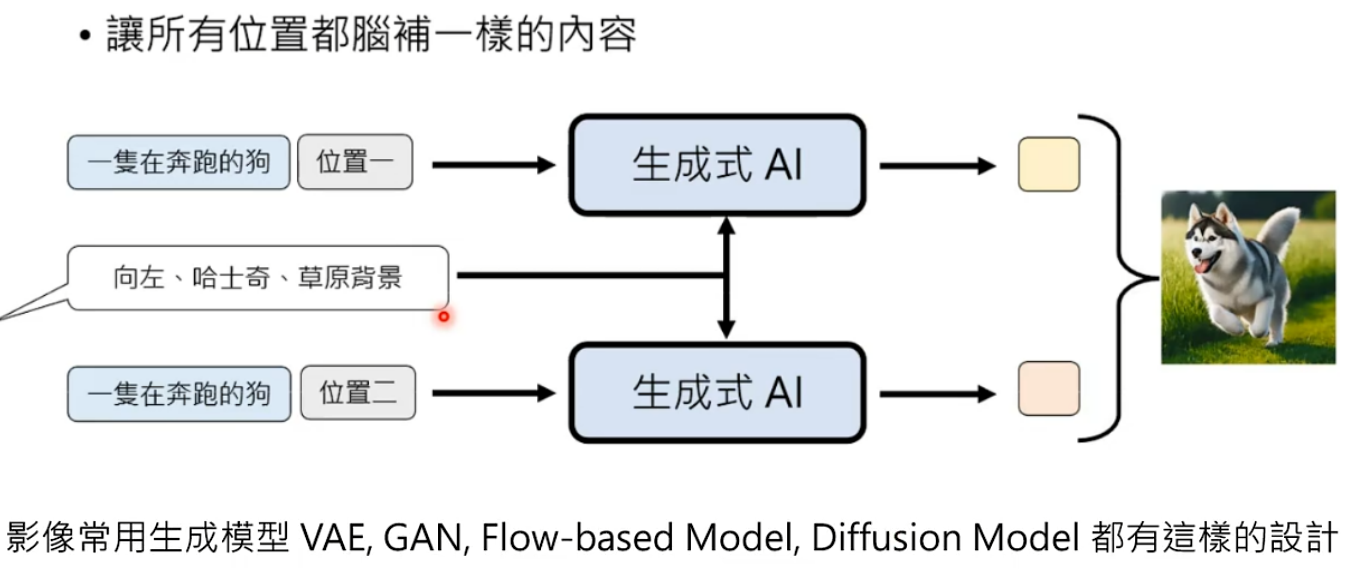
生成式AI往往需要自行脑补,给定同样的条件也会有很多可能的输出。
假设生成一个图片,每个位置的生成是独立,当生成不同位置时模型的生成思路可能是不一样。
虽然是同一个模型去生成,可能生成差不多的东西,但不能保证独立生成时想的是一模一样的。这就是早期使用NAG生成图片时,图片质量很差的原因。
这个问题被称为multi-modality problem。
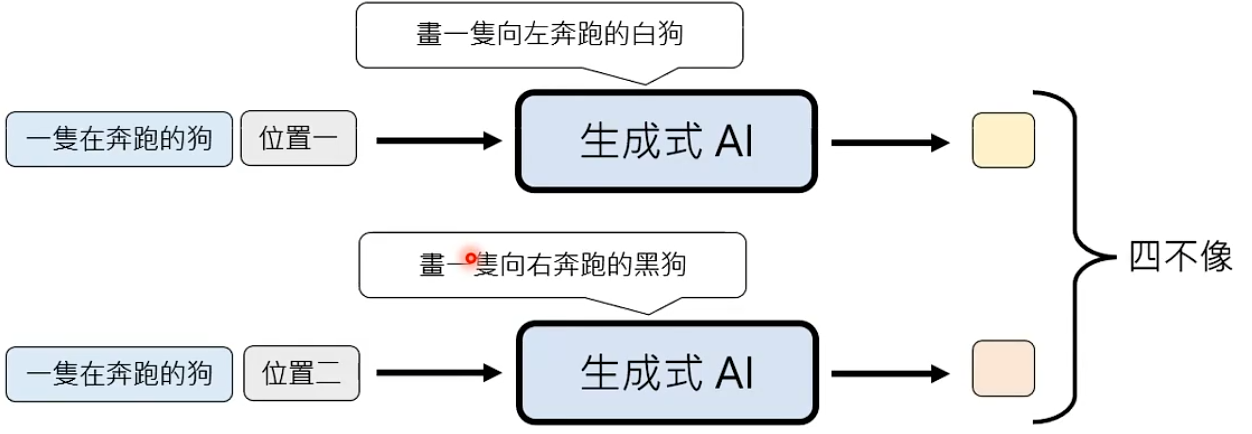
问题:虽然NAG存在multi-modality problem问题,但是不得不用其生成图片和语音。所以需要通过其他办法,解决这个问题。
解决办法1:确定好需要脑补的东西,让所有位置都脑补一样的东西。将其作为prompt输入。
解决办法2:AR + NAR,先用Autoregressive生成一个精简版本(定大框架),再根据精简版本用NAR生成精细版本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









