




文章目录
从回归到多类分类
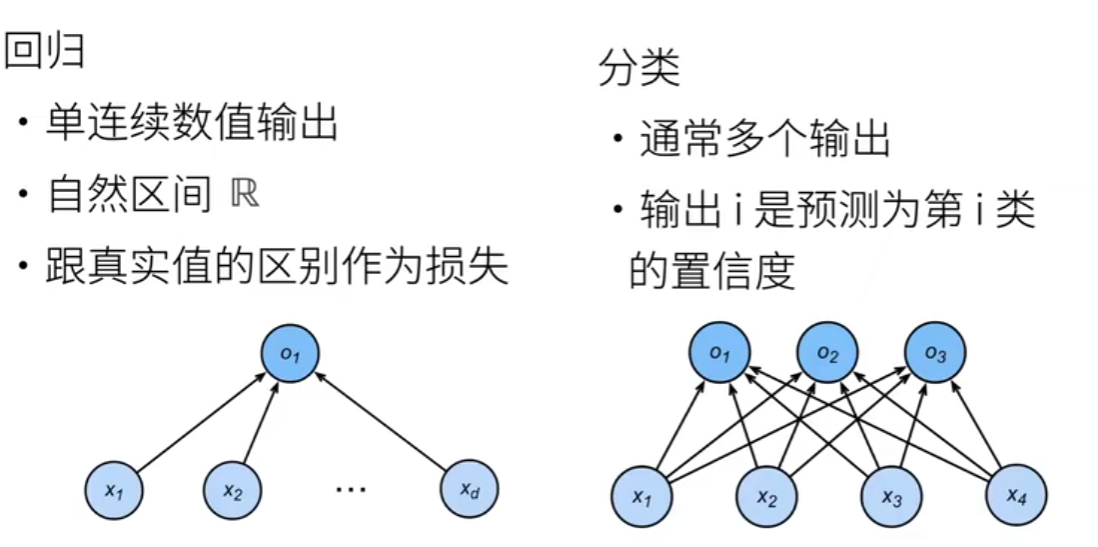
回归:估计一个连续值
- 单连续数值输出
- 输出是一个自然区别R
- 损失函数:跟真实值的区别作为损失
分类:预测一个离散类别
- 通常多个输出
- 输出i是预测第i类的置信度
在深度学习中,置信度通常指模型对其预测结果的确信程度
1.对类别进行编码:独热编码
说明
one-hot 独热编码用于将离散的分类标签转换为二进制向量。独热编码是一个向量,它的分量数目=类别,类别对应的分量设置为1,其他所有分量设置为0。
- 离散的分类:类别之间相互独立,不存在谁比谁大、谁比谁先、谁比谁后的关系。
- 二进制向量:每一个分量都是二进制的,只有0、1两种取值。
目的:将独立的标签表示为相互独立的数字,并且数字之间的距离也相等
2.使用均方损失训练
3.选取使得置信度 o i o_i oi最大的i作为预测结果
y ^ = arg max i o i \hat y = \argmax_i o_i y^=argmaxioi
角度1:对分类问题来说,并不关系预测与实际值,关心对正确类别的置信度(可能性)特别大
需要更置信(确信)的识别正确类:
正确类y的置信度 o y o_y oy要远远大于非正确类的置信度 o i o_i oi: o y − o i ≥ Δ ( y , i ) o_y - o_i \geq \Delta(y,i) oy−oi≥Δ(y,i),其中 Δ \Delta Δ表示某个阈值 => 这里我们并不关系 o y o_y oy的具体值,而是关心 o y o_y oy和 o i o_i oi的差距
角度2:我们更希望输出类别的匹配概率(非负,和为1) ,也就是输入一个样本,预测每个输出类型的概率,然后使用预测概率最高的类别作为输出:采用softmax函数。
y ^ = s o f t m a x ( o ) \hat y = softmax(o) y^=softmax(o),具体展开 y ^ i = e x p ( o i ) ∑ k e x p ( o k ) \hat y_i = \frac{exp(o_i)}{\sum_k exp(o_k)} y^i=∑kexp(ok)exp(oi)。其中,指数是不管什么值都可以让其变成非负,这个式子可以保证 y ^ i \hat y_i y^i对所有的i求和值为1。
:::tips
softmax运算将数值映射为一个概率。
:::
交叉熵损失函数
交叉熵常用来衡量两个概率的区别 H ( p , q ) = ∑ i − p i l o g ( q i ) H(p,q)=\sum_i - p_ilog(q_i) H(p,q)=∑i−pilog(qi)
将其作为损失KaTeX parse error: \tag works only in display equations
y y y通常是一个one-hot编码向量,真实类别为1,其余为,其中 y i y_i yi是真实标签的第 i i i个类别的概率; y ^ i \hat y_i y^i是模型预测的第 i i i个类型的概率。
除了 i = k i=k i=k 时 y k = 1 y_k=1 yk=1,其他 y i = 0 y_i=0 yi=0,所以求和式中只有 i = k i=k i=k的项不为零: l ( y , y ^ ) = − ∑ i y i l o g y ^ i = − ( y k l o g y ^ k ) + ∑ i ≠ k y i l o g y ^ i = − l o g y ^ k l(y,\hat y )=-\sum_i y_ilog\hat y_i = -(y_klog\hat y_k) + \sum_{i\neq k} y_ilog \hat y_i = -log\hat y_k l(y,y^)=−∑iyilogy^i=−(yklogy^k)+∑i=kyilogy^i=−logy^k
所以(1)的 y ^ y \hat y_y y^y 表示该样本的真实类别 y y y 对应的预测概率 y ^ k \hat y_k y^k。
为了更明确,交叉熵损失函数可以写成: l ( y , y ^ ) = − l o g y ^ t r u e c l a s s l(y,\hat y)=-log \hat y _{true class} l(y,y^)=−logy^trueclass
交叉熵来衡量概率区别可以发现:我们不关心非正确类的预测值,只关心正确类的预测值。
梯度下降
目标是求损失的梯度,接着朝减少损失的方向更新参数。
损失函数:$l(y,\hat y )=-\sum_i y_ilog\hat y_i $
带入softmax公式: = − ∑ i y i l o g ( e o i ∑ k = 1 q e o k ) =-\sum_i y_ilog(\frac{e^{o_i}}{\sum_{k=1}^q e^{o_k}}) =−∑iyilog(∑k=1qeokeoi)
利用对数性质 l o g ( a b ) = l o g ( a ) − l o g ( b ) log(\frac{a}{b}) = log(a)-log(b) log(ba)=log(a)−log(b):$=-\sum_i y_i [log(e^{o_i}) - log(\sum_{k=1}^q e^{o_k})] $
简化 l o g ( e x ) = x log(e^x)=x log(ex)=x: = ∑ i y i l o g ( ∑ k = 1 q e o k ) − ∑ i y i o i =\sum_i y_i log(\sum_{k=1}^q e^{o_k}) - \sum_i y_i o_i =∑iyilog(∑k=1qeo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









