







将其复制粘贴到YOLOv8的"ultralytics/nn/modules/conv.py"或者"ultralytics/nn/modules/block.py"目录下面。但是,最好新建一个文件在conv.py的同级目录下,通过建立文件导入其中类的形式。
一、创建新文件导入新模块
任何一个模块都可以像下面的图片一样直接建立一个文件粘贴复制进去。
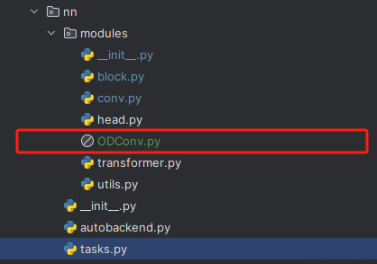
建立上面的文件之后,存在两种情况,一种是官方代码可以直接使用;另外一种需要进行一定的处理。下面分别讲解两种情况。
情况一:官方代码可以直接使用
直接修改"ultralytics/nn/modules/__init__.py"文件就可以了
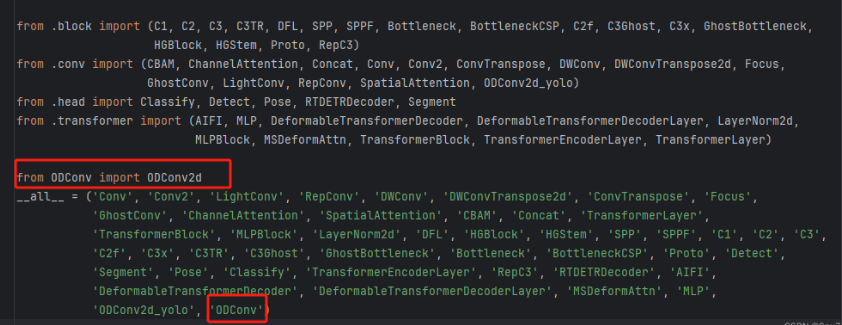
情况二:官方代码不可以直接使用
官方代码的并不能直接使用,需要经过处理,文件"ultralytics/nn/modules/conv.py"修改
修改一:导入模块
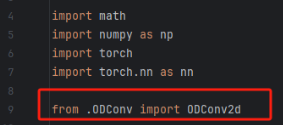
修改二:将额外处理代码添置conv模块,将所需代码添加到conv.py的末尾处
class ODConv2d_yolo(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, groups=1, dilation=1):
super().__init__()
self.conv = Conv(in_channels, out_channels, k=1)
self.dcnv3 = ODConv2d(out_channels,out_channels, kernel_size=kernel_size, stride=stride, groups=groups,
dilation=dilation)
self.bn = nn.BatchNorm2d(out_channels)
self.gelu = nn.GELU()
def forward(self, x):
x = self.conv(x)
x = self.dcnv3(x)
x = self.gelu(self.bn(x))
return x修改三:配置头文件
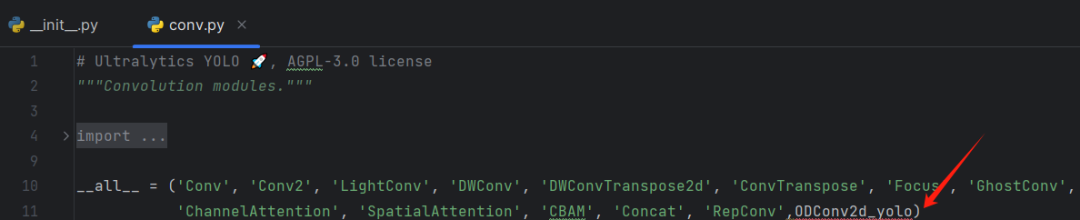
修改四:重复情况一的步骤
修改"ultralytics/nn/modules/__init__.py"文件如下

二、Conv模块
已经把定义的模块放入Conv模块中了,还需要其他配置。当然不同的模块导入方式略有不同。
修改一:如下的文件"ultralytics/nn/tasks.py"
先把在上面"ultralytics/nn/modules/__init__.py"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











