







sv lab4学习记录
-
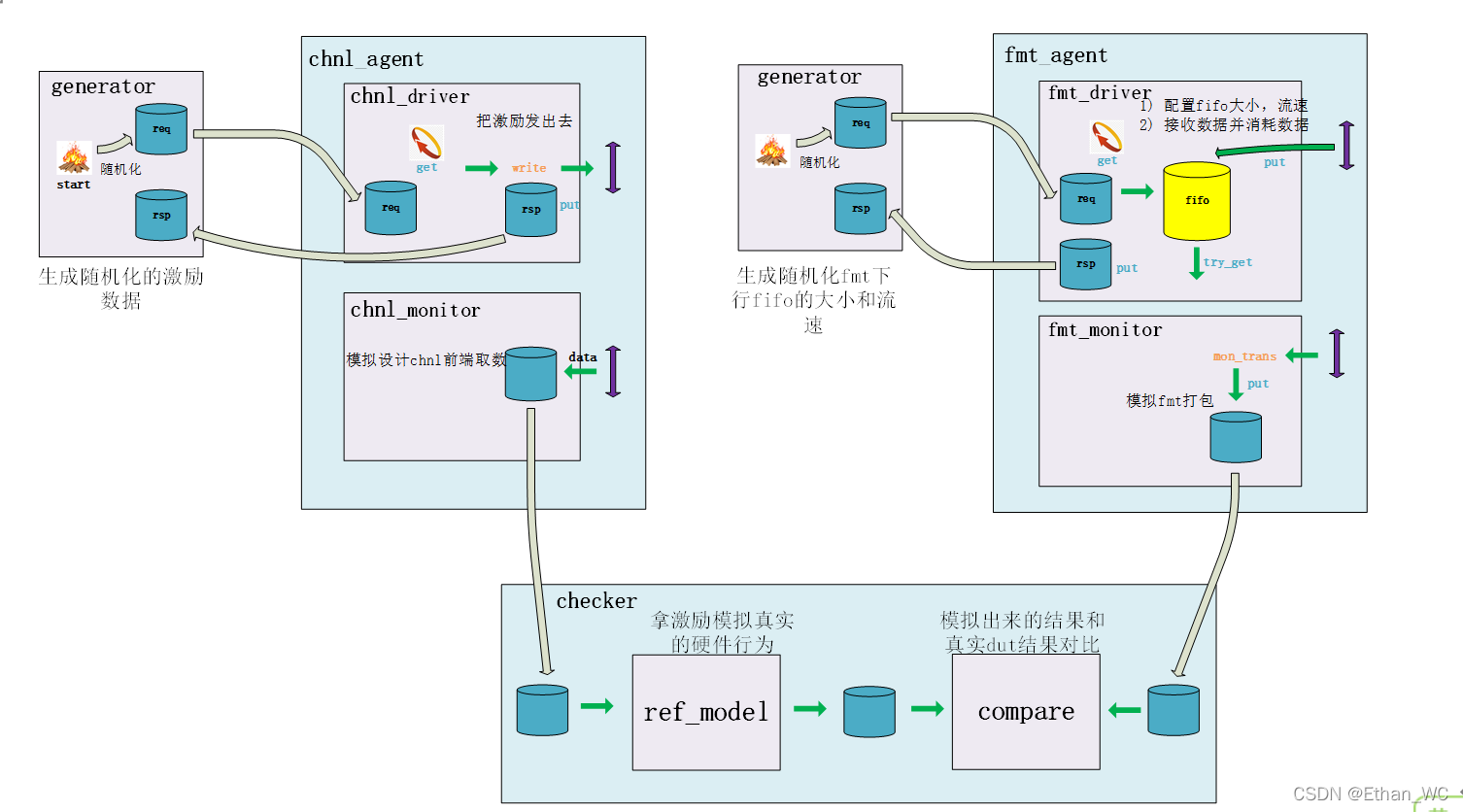
框架图
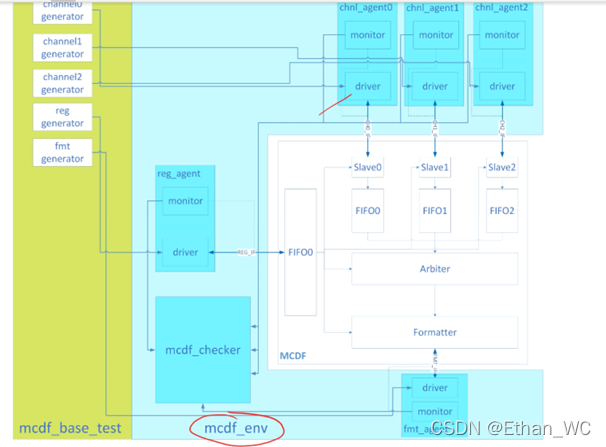
-
这个mcdf interfance 为什么存在?
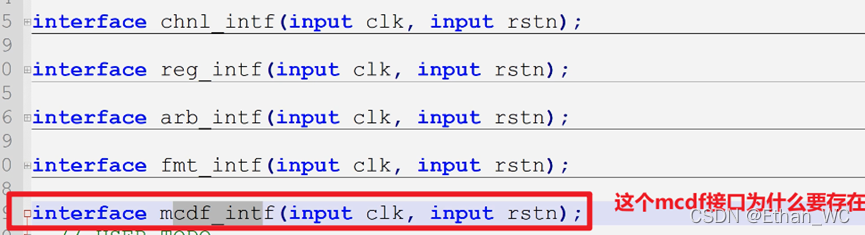
因为对于chnl_intf, reg_intf, fmt_intf, arb_intf, 他们都是直接和mcdf_intf连接的。有时候我想监测内部的信号,我会把内部的信号直接先交给mcdf_intf。而mcdf_intf又可以被验证环境中的任何一个组件拿到。比方说checker可以通过mcdf_intf监测到chal, reg, formatter,的信号,间接的可以监测到一些关键的信号。这样我们以前的那些黑盒的验证慢慢的就变成了灰盒。 -
约束合理不合理取决于对设计的理解。
-
关于fmt_pkg

fmt_pkg包和以往的包不同,以往的包都是一个master,只管生成数据然后发送出去。但是fmt_pkg需要模拟一个response,不仅要接受数据还得按一定的速度将数据消化掉,所以需要在内部放一个fifo。
fmt_agent模拟的这个缓存,有可能数据消耗的快,也可能消耗的慢。这样进一步可以模拟出grant什么时候拉高。所以fmt_agent里的driver和之前的都不一样。1)这里的generator是在生成什么呢?
生成随机数,内部fifo的大小和消耗数据的速度,这些都需要随机。fmt_pkg需要模拟一个slave,不单单需要将数据拿进来,还要消化掉,还要模拟消化数据有多快,要模拟深度有多深。
而这里用了两个枚举类型,用来简明控制生成相关参数的随机数。
2)这里的driver是在干什么呢?
该类是接受gene生成的两个随机枚举型,配置(fifo大小和消耗速度<带宽>)并生成内部fifo,模拟response端行为,上端接收dut的数据,下端模拟消耗数据。
- Driver中干以下四个task:

① 配置do_config()

得到gene随机后的fmt_fifo_t和fmt_bandwidth_t值。后开始生成内部fifo,进行相关配置。
注意:
req.fifo和this.fifo不一样,不同类中的变量名字一样,前者为枚举类型,后者为mailbox。
⑴ req.fifo为枚举类型,根据不同的枚举值选择不同的fifo_bound (即fifo的深度的数值)和data_consum_peroid(即数据消耗的速度,控制水流出去的速度)。
⑵ this.fifo即真正的buf,根据以上随机值生成真正的buf,配置其大小和流速。
② 上端接收数据任务 do_receive()

注意:只有内部余量大于包的长度(能存的下),才会将grant给dut,表示我当前可以接收数据。
接收到数据后put进fifo中。
③ 下端消耗数据任务 do_consum()
拿一次数据等一段随机时间,拿一次等一段随机时间。

3) 这里的monitor是在干什么呢?
该类将接口上的数据解出来,根据各自的长度放到相应的动态数组中,然后打印出来。送给checker作最终的数据比较。

#=============================================================#
路桑留的问题:
- 既然我们在do_config中做了配置new(大小),还有必要在初始function new中配置 初始值嘛?为什么一开始要给fifo做new(),如果不做new行不行?
- 做了new,为什么不给他们做new(10),new(100),为什么一开始要new个无穷大?有没有必要?

#=============================================================#
- 关于mcdf_checker
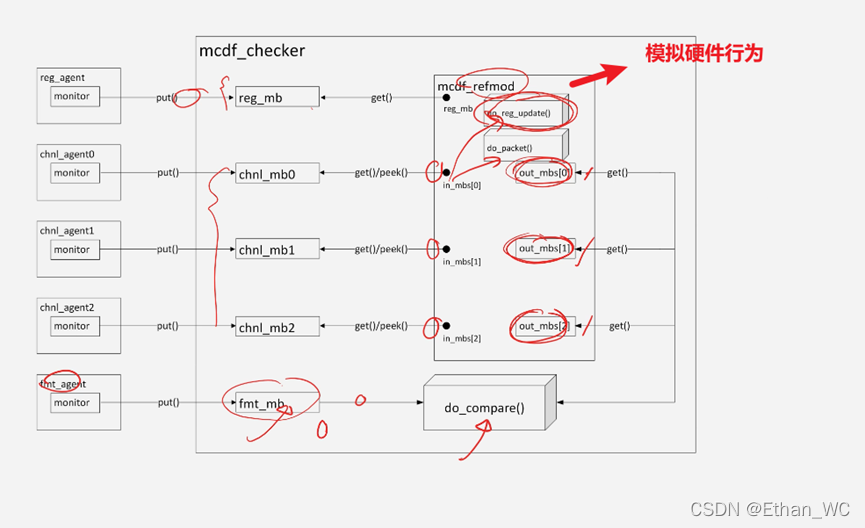

基本模型图:
小细节:设计中真正打包的只有fmt模块,它只有一个buf。而ref_model中有三个buf,它是在做什么?
==> 它是在假定arbit的功能是OK的,arbit也没有丢数。
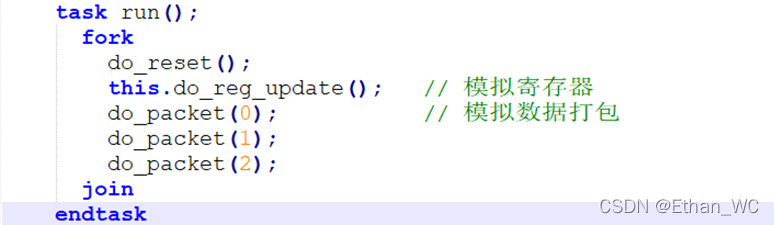
ref_model做的事情:
① 对寄存器的模拟;
② 对数据长度的打包;
ref_model没有模拟的事情:
① 让哪些数据通道可以开关;
② arbit的仲裁功能;【哪些数据谁在前谁在后(优先级)没有检查】
所以该ref_model能够帮忙检查的是:
① 数据完整性的检查,数据有无丢失;
- mcdf_pkg.sv中包含了 checker, mcdf_env, mcdf_test
checker中在干什么?

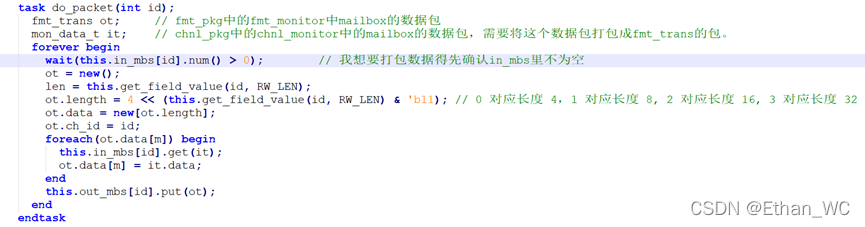
① mcdf_refmod: 完成模拟数据读写和三个通道的数据打包
1) do_reg_update() 模拟寄存器读写

2) do_packet(int id)
细节:do_packet()中 wait(this.in_mbs[id].num() > 0);
// 我想要打包数据得先确认in_mbs里不为空
② mcdf_checker: 完成 fmt_mb出来的数据包和refmodel打包后exp_mbs的数据包的比较

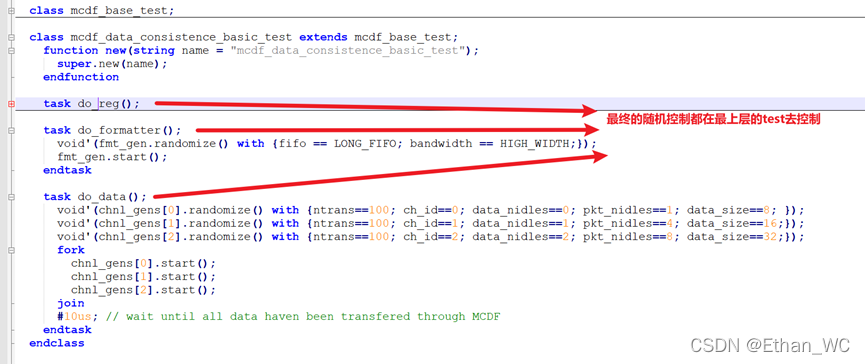
- 最终的generate随机化都在最上层的test去控制。


















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











