







 这篇博客介绍了神经网络基础中的梯度下降法,包括概念、参数初始化、单参数及多参数的梯度下降更新规则,并详细讲解了在Logistic回归中如何应用梯度下降法进行模型训练。
这篇博客介绍了神经网络基础中的梯度下降法,包括概念、参数初始化、单参数及多参数的梯度下降更新规则,并详细讲解了在Logistic回归中如何应用梯度下降法进行模型训练。
吴恩达笔记——神经网络基础(四):梯度下降法
上一节讲到损失函数和成本函数
损失函数:用于衡量单一样本的算法效果
成本函数:用于衡量参数w和b的效果,在全部训练集上的效果
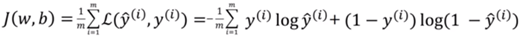
1)梯度下降法概念
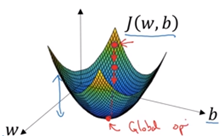
利用训练集在成本函数上使用梯度下降法,获取参数w和b。
a)初始化w和b(对于Logist回归,任意w和b均有效),通常用0做初始化
b)沿着函数J下降最快的方向迭代(w和b)
c)迭代后,J收敛到全局最优解,即最小值处
以单参数J(w)函数为例,梯度下降参数更新方法如下:

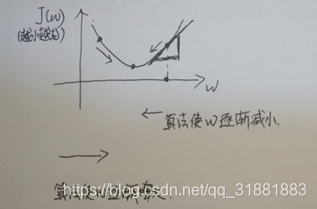
无论初始值在哪一侧,梯度下降法都会使成本函数朝着最优方向移动;
当成本函数有多个参数时,梯度下降参数更新方法如下:
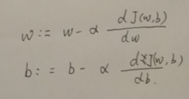
2)Logis
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









