






论文链接:https://arxiv.org/pdf/2401.05856
论文解读:构建检索增强生成系统中的七个失败点
一、背景与研究动机
随着大语言模型(LLM)如 ChatGPT 的出现,软件工程师开始尝试将检索机制与生成能力结合,构建 检索增强生成(Retrieval Augmented Generation, RAG) 系统。RAG 系统的主要目标是:
- 降低 LLM 生成幻觉性回答的风险,
- 提供答案的引用来源,
- 避免为文档人工标注元数据的需求。
论文旨在通过三个不同领域(科研、教育、生物医学)的案例研究,揭示在工程实践中构建 RAG 系统时所遇到的主要失败点,并探讨系统在运行过程中需要不断调整与验证的挑战。
二、RAG 系统的工作流程
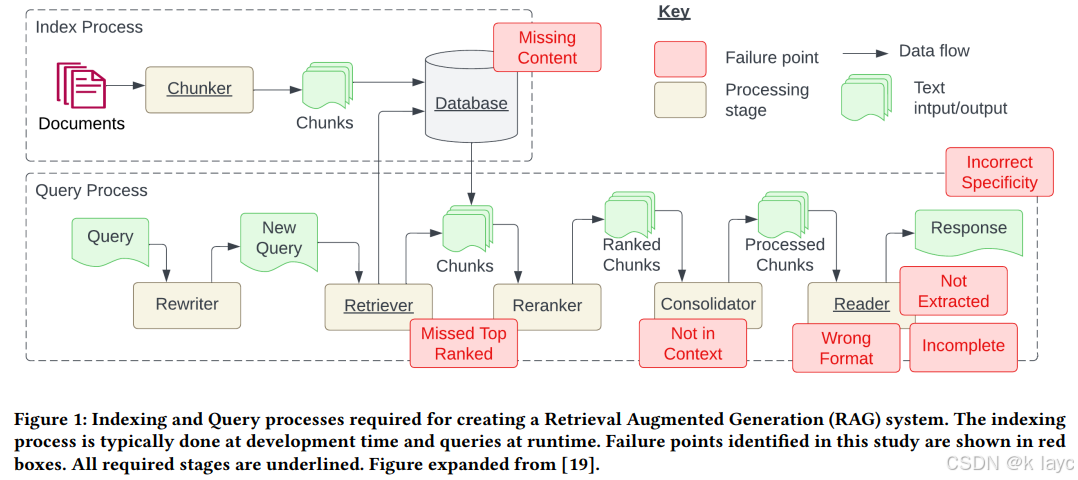
RAG 系统通常分为两个主要流程:索引过程 和 查询过程。
1. 索引过程(Index Process)
- 文档预处理与分块
将原始文档拆分成若干较小的片段(chunks)。分块大小需要精心设计:- 过小可能导致信息不全,无法回答复杂问题;
- 过大则可能引入噪音。
- 嵌入生成
对每个分块使用嵌入模型将其转换成一个向量表示,即$embedding$。这些嵌入向量存入一个向量数据库,便于后续检索。
2. 查询过程(Query Process)
- 查询转换
用户提出的自然语言查询会先通过预处理转换成一个标准化查询,然后再生成其嵌入表示。 - 相似度检索
利用余弦相似度等方法比较查询向量和文档向量:
cos ( θ ) = A ⋅ B ∥ A ∥ ∥ B ∥ \cos(\theta) = \frac{A \cdot B}{\|A\|\|B\|} cos(θ)=∥A∥∥B∥A⋅B
检索出最相似的 Top- k k k 文档。 - 上下文整合与回答生成
将检索到的文档作为上下文传递给大语言模型,经过定制化的提示(prompt),生成最终的回答。由于 LLM 存在 token 限制和响应速率限制,通常还需要设计有效的整合(Consolidation)策略,以保证所选上下文能够包含正确的答案。
三、案例研究简介
论文中通过三个案例研究展示了 RAG 系统在不同领域中的应用与挑战:
- Cognitive Reviewer
面向科研文献分析的系统,帮助研究者对上传的相关论文进行排序和问答。 - AI Tutor
教育领域的 RAG 系统,集成到学习管理系统中,支持学生对学习内容提问,并提供可追溯答案来源。 - Biomedical Question and Answer
使用 BioASQ 数据集构建的生物医学问答系统,针对领域特定的问题进行回答,考验系统在大规模文献中提取信息的能力。
四、论文提出的七个失败点
论文总结了在构建 RAG 系统时可能遇到的七个关键失败点,每个失败点都反映了实际应用中的一个重要问题:
-
FP1:缺失内容 (Missing Content)
当问题在已有文档中没有答案时,系统应返回“对不起,我不知道”,但有时系统可能生成看似合理但错误的回答。 -
FP2:未检索到排名靠前的文档 (Missed the Top Ranked Documents)
虽然正确答案存在于某个文档中,但由于排序算法或设定的 Top- k k k 限制,该文档未能被包含在检索结果中。 -
FP3:上下文整合失败 (Not in Context - Consolidation Strategy Limitations)
即使相关文档已被检索,整合过程(例如在多个文档中筛选出最佳信息)未能将答案有效整合进上下文中,导致 LLM 无法生成正确回答。 -
FP4:答案未被正确抽取 (Not Extracted)
答案实际上存在于上下文中,但由于上下文中噪音过多或信息冲突,LLM 无法正确提取出关键内容。 -
FP5:格式错误 (Wrong Format)
当问题要求以特定格式(例如表格或列表)回答时,LLM 有时会忽略这一要求,生成格式不正确的回答。 -
FP6:回答具体性不匹配 (Incorrect Specificity)
系统生成的回答可能过于笼统或反之,过于具体,不能满足用户特定的需求。这在教育领域尤为明显,教师往往需要更具针对性的解释。 -
FP7:回答不完整 (Incomplete)
答案虽然部分正确,但缺少关键信息,无法全面回答用户的问题。例如,当用户询问多个文档的关键点时,最好分开提问以获得完整答案。
五、经验教训与未来研究方向
论文从实际案例中总结出两大关键经验:
-
验证必须在运行中进行
离线评估往往无法揭示所有问题,只有在系统实际运行时才能发现并验证各种失败点。 -
稳健性需要不断演化
RAG 系统的鲁棒性并非一开始就能设计好,而是在不断的实际应用与校准中逐步提高。
未来研究方向包括:
-
分块与嵌入策略的优化
- 探讨启发式分块(例如基于标点、段落结束)与语义分块的优劣。
- 研究如何生成更适用于特定领域的嵌入表示。
-
RAG 与微调(Finetuning)的比较
- 分析两者在准确性、延迟、成本及隐私安全方面的权衡,帮助工程师选择最适合的系统架构。
-
测试与监控方法的改进
- 建立自动化生成测试用例与评估指标(例如利用 OpenAI 的 OpenEvals 框架)。
- 结合自适应系统的思想,实现系统的实时监控和动态调优。
六、总结
论文为软件工程师在构建 RAG 系统时提供了一个宝贵的经验总结,通过三个不同领域的案例研究,揭示了从文档分块、嵌入生成、检索、整合到回答生成过程中可能遇到的七大失败点。未来的研究需要在分块策略、嵌入质量、系统验证和实时监控等方面进行更多探索,才能实现更加鲁棒和高效的 RAG 系统。

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









