








Policy Gradient 能够让算法在连续的空间中选择动作。
Value-Based 方法能够实现单步更新,而Policy Gradient是回合更新。

Critic 部分学习出系统的奖惩值,
由学习到的奖惩值指导Actor的动作。
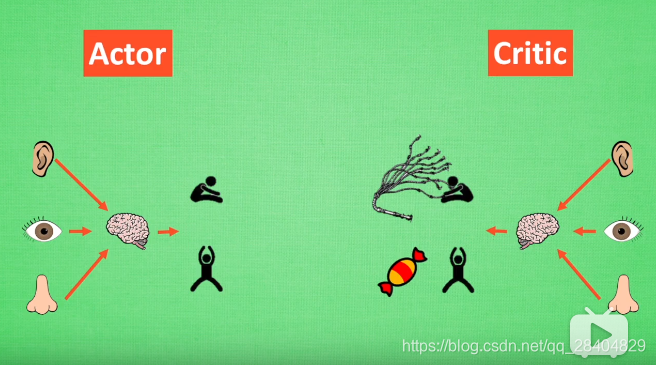
每次参数更新都存在相关性,导致神经网络只能片面的看待问题。
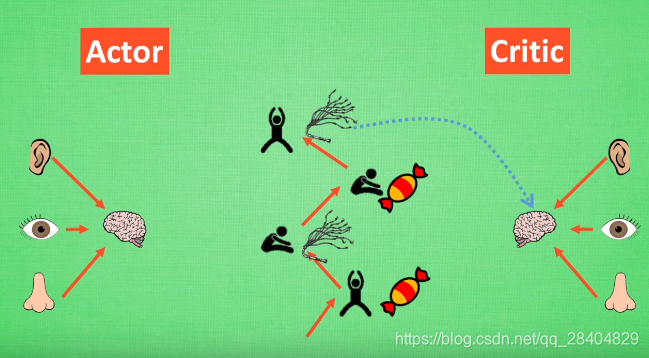
为解决在连续动作上预测学不到东西的问题

https://www.bilibili.com/video/av16921335?p=25
Policy Gradient 能够让算法在连续的空间中选择动作。
Value-Based 方法能够实现单步更新,而Policy Gradient是回合更新。
Critic 部分学习出系统的奖惩值,
由学习到的奖惩值指导Actor的动作。
每次参数更新都存在相关性,导致神经网络只能片面的看待问题。
为解决在连续动作上预测学不到东西的问题
https://www.bilibili.com/video/av16921335?p=25
 2万+
6979
3184
2万+
6979
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























