








Policy Gradients 相比于 Q-learning 的好处是,它可以在一个连续的空间内选择动作。

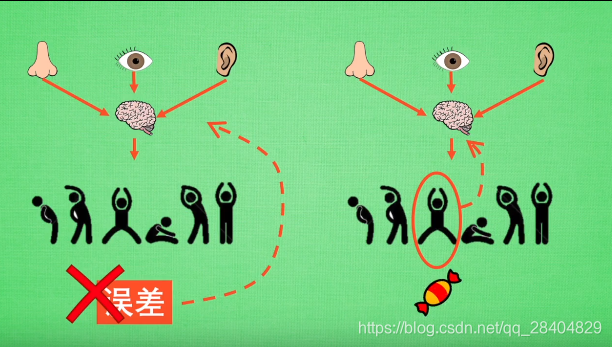
神经网络选择操作的行为,根据反馈如果是正向的则加大下一次被选中的几率,如果是反向的则减少下一次被选中的几率。
原视频:
https://www.bilibili.com/video/av16921335?p=22
Policy Gradients 相比于 Q-learning 的好处是,它可以在一个连续的空间内选择动作。
神经网络选择操作的行为,根据反馈如果是正向的则加大下一次被选中的几率,如果是反向的则减少下一次被选中的几率。
原视频:
https://www.bilibili.com/video/av16921335?p=22

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























