




 本文探讨了在限定第二类错误率的前提下,如何寻找最优决策面以最小化第一类错误率的问题。介绍了R1和R2样本区域,以及如何通过调整拉格朗日乘子λ来实现这一目标。并解释了如何使用似然比密度函数求得λ,以及Neyman-Pearson决策规则的应用。最后,通过ROC曲线评估分类方法的性能。
本文探讨了在限定第二类错误率的前提下,如何寻找最优决策面以最小化第一类错误率的问题。介绍了R1和R2样本区域,以及如何通过调整拉格朗日乘子λ来实现这一目标。并解释了如何使用似然比密度函数求得λ,以及Neyman-Pearson决策规则的应用。最后,通过ROC曲线评估分类方法的性能。
首先介绍一下背景:
R1 阴性样本区域, R2 阳性样本区域;
w1 阴性样本类别, w2 阳性样本类别;
第一类错误:假阳性 P1(e); 第二类错误: 假阴性 P2(e);
这个问题有两个变量,一个是决策面,一个是拉格朗日乘子
首先目标方程为:在第二类错误为m的情况下,使得第一类错误最小所求得的决策面
min P1(e) s.t. P2(e)=m;
目标方程 min Y=P1(e)+ \lambda (P2(e)-m)
分别对x和\lambda求偏导数,令他们得0可以得到:
而这个决策边界应该使得:
当然,\lambda的值是很难求得,可以使用似然比密度函数p(l|w2)求得\lambda
由于P(L|w2)>=0 ,P2(e) 是\lambda的单调函数,即当\lambda增加时P2(e)将逐渐减小,当\lambda=0时,P2(e)=1,当\lambda->+无穷,则P2(e)->0, 因此可以采用试探法对几个不同的\lambda 值计算出P2(e)后, 总可以找到一个合适的\lambda值,它刚好能够满足P2(e)=m的条件,又使得P1(e)尽可能小.
决策规则:
使得\lambda是使决策区域一个阈值,这种在限定一类错误率为常数而使得另一类错误率最小的决策规则称作Neyman-Pearson决策规则.
ROC曲线:Sn为真阳性(1-P1(e))作为纵坐标,假阳性(1-Sp=P2(e))作为横坐标,例如下面的图
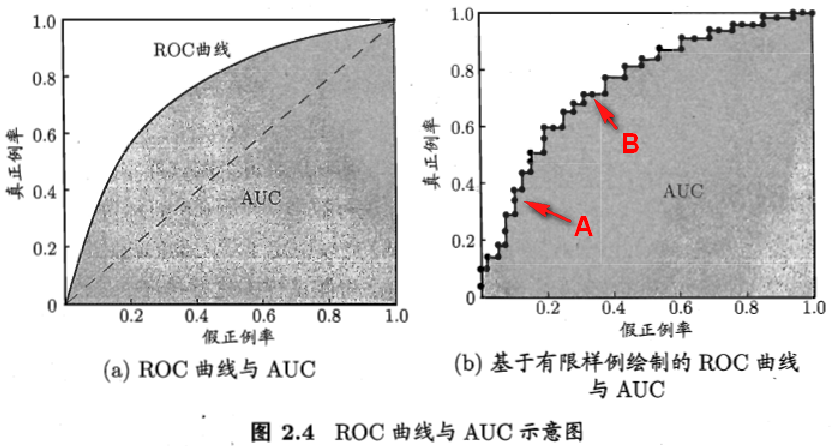
(0.1,0.7)点表示在某一阈值下假阳性为10%时,真阳性为70%.
对于一个决策方法,总是希望真阳性率高,假阳性率低,如果某种方法的真阳性率总是等于其假阳性率,那么就没有任何应用价值,这就是ROC曲线中的对角线,任何分类方法或检验方法,其ROC曲线都必须在对角线左上方可能有实际价值,ROC曲线越靠近左上角,说明方法的性能越好,因此人们通过ROC曲线来全面的评价一种分类方法或者比较两种分类方法的优劣,

















 4980
4980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









