









模型选择:
通过采用不同的输入训练样本,决定其算法中各个参数的最优值。
模型选择算法:
1.准备模型的候选M1,M2,...,MK;
2.对各个模型M1,...MK求解其学习结果f1,...fk;
3.对各个学习结果f1,...fk的泛化误差G1,..,GK进行评价;
4选择泛化误差G1,...,GK最小的模型为最终模型。
其中最重要的是第三步骤,在监督学习中并不是要通过庞大的训练集让计算机记住训练集,而是希望通过训练集能够让计算机推导出不在训练集中出现过的样本的值为多少,泛化是指机器对未知测试数据样本的处理能力,泛化误差是指未知的测试输入样本的输出和所做的预测之间的差值。
交叉验证法:
1.把训练样本随机划分为m个集合;
2.对i=1...m循环执行如下操作
(a)对除了Ti以外的训练样本进行学习,求解学习结果为fi;
(b)把上述过程中没有参与学习的Ti作为测试样本,对fi的泛化误差进行评估
其中表示集合内包含的训练样本的个数。
3.对各个i的泛化误差的评估值进行平均,得到最终的泛化误差的评估值
留一交叉验证法:
把分割的数据集设定为训练样本数n,即对n-1个训练样本进行学习,将余下的1个作为测试样本。留一交叉验证法需要循环进行n次学习,如果n的值很大,计算时间回延长,因此使用评估值解析式:
其中:
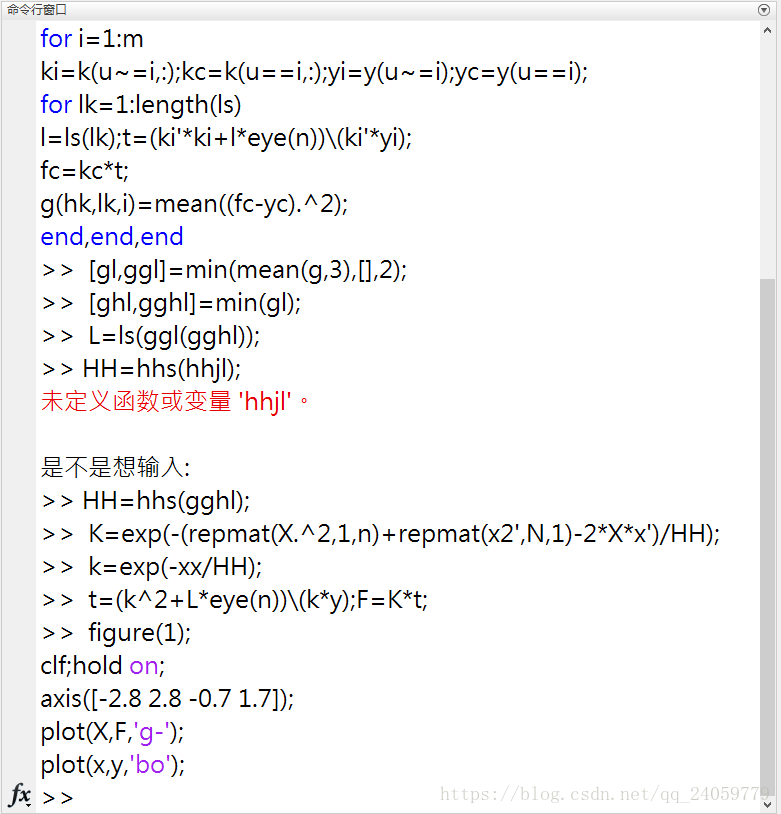
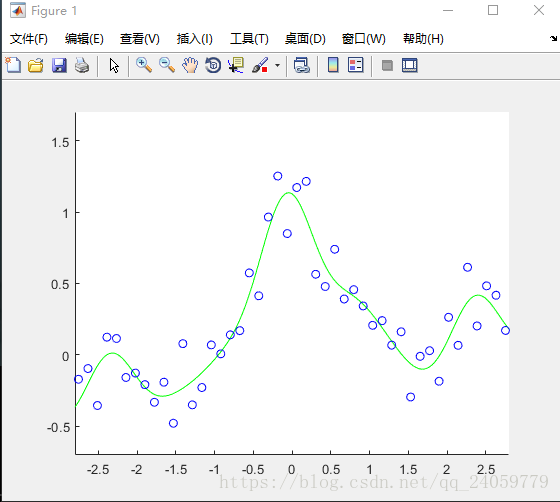
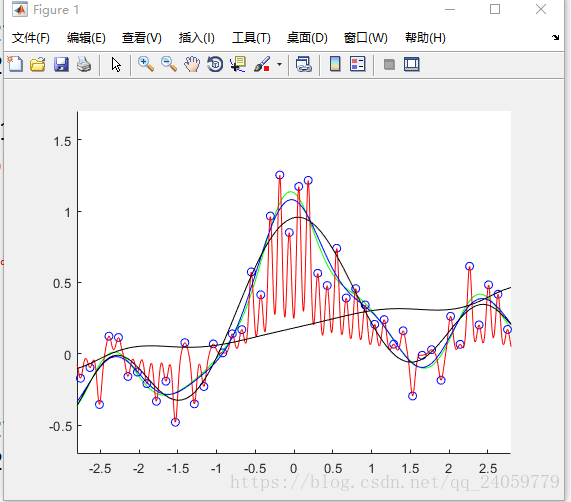
我又做了几个不同参数的拟合还是发现上面的参数拟合的效果最好。

















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









