









python实现fastq文件GC含量的计算
fastq格式是生物信息分析中最常见的格式之一
通常我们可以将测序的数据分为双端测序和单端测序双端测序的数据含有两个fastq格式的文件,单端测序的数据只有一个fastq格式的文件
-
第一行是用来区分不同reads的一个ID号,一般以@符号开头,这一行是用来区分不同的reads,而这一行本身包含了很多的信息。
Read Record Header
Flow Cell ID
Lane
Tile
Tile Coordinates
Barcode -
第二行是测序的序列,也就是reads的序列
-
第三行一般是一个+号,或者与第一行的信息相同
-
第四行是碱基质量值,是对第二行序列的碱基的准确性的描述,一个碱基会对应一个碱基质量值,所以这一行和第二行长度是一样的,如果不一样就说明数据有问题。
-
fastq文件
@HWI-D00621:692:HW52WBCX2:1:1101:5079:2466 1:N:0:AAGTATCGTAAGACAC
ACTCCTACGGGAGGCAGCAGTAGGGAATTTTGGGCAATGGGCGAAAGCCTGACCCAGCAACGCCGCGTGTGTGATGAAGCCCCTAGGGGTGTAAAACACTGTCAGTAGGGAAGAACAAATGACTGTACCTACAGAGGAAGCACCGGCTAACTCCGTGCCAGCAGCCGCGGTAATACGGAGGGTGCAAGCGTTATCCGGAATCATTGGGCGTAAAGAGTTCGTAGGCGGTATATCAAGTCTGGTGTTAAAT
+
DDDDDIIIIIIIIIIIIIIIIIIIIHIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIHIIIIIIIIIIHIIIIIIIIIIIIIIIIIHHHHIIIIIIIIIHIIGHHIIHIIIIIIGIEHIIHIIIIIIIIGHHHIIIIHFHIIGIIIFHIIEHEHHFHIIHIIIIIIEEHHHFHIIIHHIHIIIIIIIHH=GHIII=E?FHHGHIIIHDH=BFHIHICHHHHHIIIHHH?FHGHIFHEGFGHHIIH@H
GC含量的意义:
GC含量是在所研究的对象(例如放线菌)的全基因组中,(鸟嘌呤)(Guanine)和胞嘧啶(Cytosine)所占的比例。一种生物的基因組或特定DNA、RNA片段有特定的GC含量。
计算下面的fq文件的gc含量:
fastq文件 : Bacterial_F1_1.fq
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:wangmeng
# email:15670536819@163.com
gccontent=open("/home/***/Data/ele_data_2019_2_28/Bacterial_F1_1.fq","r")
#set the the values to 0
a=0
g=0
c=0
t=0
linenumber=0
gccontent.readline()
for line in gccontent:
line=line.lower()
linenuber+=1
if linenumber%4==1:
print line
print linenumber
for gc in line.lower():
if gc=="a":
a+=1
if gc=="c":
c+=1
if gc=="g":
g+=1
if gc=="t":
t+=1
print "number of a's " + str(a)
print "number of c's " + str(c)
print "number of g's " + str(g)
print "number of t's " + str(t)
gc=(g+c+0.)/(a+t+g+c+0.)
print "gc content:"+str(gc)
结果:
因为只取第二行的序列信息,所以每四行取一行计算,下面是取到的序列。
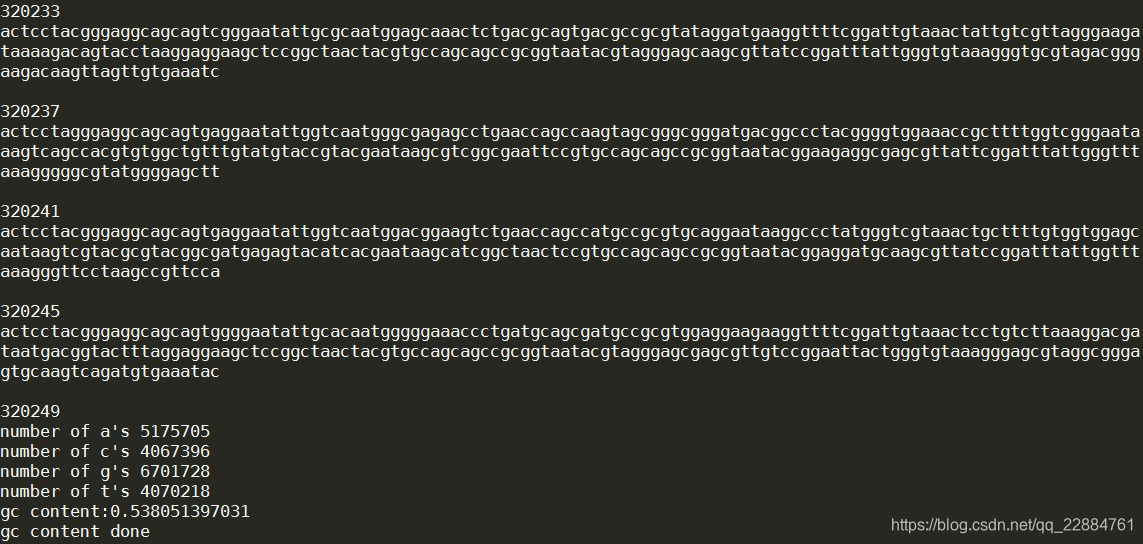 看到gc含量为53.8%,符合实际情况。
看到gc含量为53.8%,符合实际情况。
搜索公共号:ShengXinZaTan

















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









