 逻辑回归与正则化详解
逻辑回归与正则化详解





 本文深入探讨了逻辑回归模型及其在分类问题中的应用,详细解析了逻辑回归的数学原理,包括Sigmoid函数、决策边界及代价函数的推导。同时,针对过拟合问题,介绍了正则化技术,通过调整参数避免模型复杂度过高,保持泛化能力。
本文深入探讨了逻辑回归模型及其在分类问题中的应用,详细解析了逻辑回归的数学原理,包括Sigmoid函数、决策边界及代价函数的推导。同时,针对过拟合问题,介绍了正则化技术,通过调整参数避免模型复杂度过高,保持泛化能力。
作为英语课程,读中文参考资料的确有助于理解,但是出于对以后更长久的学习优势考虑,笔记中我会尽量采用英文来表述,这样有助于熟悉专有名词以及常见语法结构,对于无中文翻译的资料阅读大有裨益。
Week3 Logistic Regression and Regularzation
一、Logistic Regression
-
Classification分类问题
-
Logistic Regression逻辑回归模型
- hθ(x)=g(θTX)h_\theta(x)=g(\theta_TX)hθ(x)=g(θTX)
- 对于给定的输入变量X,θ\thetaθ,计算输出变量=1的可能性
- hθ(x)=P(y=1∣x;θ)h_\theta(x)=P(y=1|x;\theta)hθ(x)=P(y=1∣x;θ)
- X:Feature Vector
- g:Logistic function/Sigmoid function
- g(z)=11+e−zg(z)=\frac{1}{1+e^{-z}}g(z)=1+e−z1
-
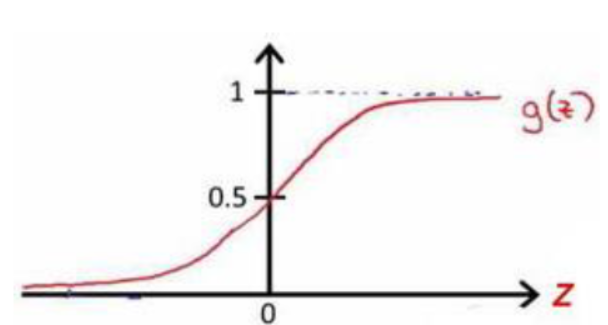
- hθ(x)=g(θTX)h_\theta(x)=g(\theta_TX)hθ(x)=g(θTX)
-
Decision Boundary决策边界
-
根据逻辑回归模型函数可归纳得到
θTx>=0,y=1\theta^Tx>=0,y=1θTx>=0,y=1
θT<0,y=0\theta^T<0,y=0θT<0,y=0
-
-
如何拟合Logistic Regression的参数θ\thetaθ——Cost Function
- We know in Linear Regression
- j(θ)=1m∑i=1m12(hθ(xi)−yi)2j(\theta)=\frac{1}{m}\sum_{i=1}^{m}\frac{1}{2}(h_\theta(x^i)-y^i)^2j(θ)=m1∑i=1m21(hθ(xi)−yi)2
- In Logistic Regression
- J(θ)=1m∑i+1mCost(hθ(xi)−yi)J(\theta)=\frac{1}{m}\sum_{i+1}^{m}Cost(h_\theta(x^i)-y^i)J(θ)=m1∑i+1mCost(hθ(xi)−yi)
- Cost(hθ,y)=−log(hθ(x)),y=1Cost(h_\theta,y)=-log(h_\theta(x)) ,y=1Cost(hθ,y)=−log(hθ(x)),y=1(成本函数)
- Cost(hθ(x),y)=−log(1−hθ(x)),y=0Cost(h_\theta(x),y)=-log(1-h_\theta(x)) ,y=0Cost(hθ(x),y)=−log(1−hθ(x)),y=0
- Cost(hθ,y)=−ylog(h)−(1−y)log(1−h)Cost(h_\theta,y)=-ylog(h)-(1-y)log(1-h)Cost(hθ,y)=−ylog(h)−(1−y)log(1−h)
- 带入J(θ\thetaθ)后得到的J可以证明是一个凸函数,化简后代价函数形式上与Linear Logistic的代价函数一致
- J(θ)=1m∑i=1m[hθ−y]xjJ(\theta)=\frac{1}{m}\sum_{i=1}^{m}[h_\theta-y]x_jJ(θ)=m1∑i=1m[hθ−y]xj
-
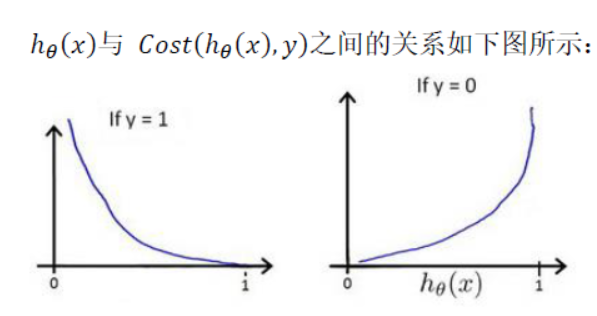
- Meaning: when y=0 h=0,then Cost=0;when y=0,h=1,then cost->+∞+\infty+∞
- J(θ)=1m∑i+1mCost(hθ(xi)−yi)J(\theta)=\frac{1}{m}\sum_{i+1}^{m}Cost(h_\theta(x^i)-y^i)J(θ)=m1∑i+1mCost(hθ(xi)−yi)
- Octave中的高级函数
costFunction自动寻找当前参数的最优高级算法,返回
- We know in Linear Regression
-
Multiclass Classification——one-vs-all 一对多,多类别分类
-
将数据分成1和很多类,仍然是二元分类
hθ(x)=p(y=i∣x;θ);i=1,2...kh_\theta(x)=p(y=i|x;\theta);i=1,2...khθ(x)=p(y=i∣x;θ);i=1,2...k
-
二、Regularization正则化
- 过拟合问题——与training set高度吻合,但是失去预测意义
- 解决方案
- 手动丢弃或者模型选择
- 正则化,保留所有Features,但是减少参数大小
- 以多项式拟合为例,过拟合是由高次项导致的,让高次项系数趋于0是解决思想
- 对J(θ\thetaθ)引入Regularization Parameter(正则化参数)(不对θ0\theta_0θ0进行修正(or called “惩罚”)
- J(θ)=12m[∑i=1m(hθ(xi)−yi)2+λ∑j=1nθj2]J(\theta)=\frac{1}{2m}[\sum_{i=1}^{m}(h_\theta(x^i)-y^i)^2+\lambda\sum_{j=1}^n\theta_j^2]J(θ)=2m1[∑i=1m(hθ(xi)−yi)2+λ∑j=1nθj2]
- 原理解释:令λ\lambdaλ很大,则为了Cost Function尽量小,所有θi(i!=0)\theta_i(i!=0)θi(i!=0)都会减小;但也不能太大,不然所有参数趋于0
- Regularized Linear Regression正则化的线性回归
- θ0:=θ0−α[1m∑i=1m(hθ−yi)x0i]\theta_0:=\theta_0-\alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta-y^i)x_0^i]θ0:=θ0−α[m1∑i=1m(hθ−yi)x0i]
- θj:=θj−α[1m∑i=1m(hθ−yi)xji+λmθj]=θj(1−aλm)−a1m∑i=1m(hθ−yi)xj\theta_j:=\theta_j-\alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta-y^i)x_j^i+\frac{\lambda}{m}\theta_j]=\theta_j(1-a\frac{\lambda}{m})-a\frac{1}{m}\sum_{i=1}^{m}(h_\theta-y^i)x_jθj:=θj−α[m1∑i=1m(hθ−yi)xji+mλθj]=θj(1−amλ)−am1∑i=1m(hθ−yi)xj
- Regularized Logistic Regression正则化的逻辑回归
- J(θ)=1m∑i=1m[−yilog(hθ)−(1−yi)log(1−hθ)]+λ2m∑j=1nθj2J(\theta)=\frac{1}{m}\sum_{i=1}^{m}[-y^ilog(h_\theta)-(1-y^i)log(1-h_\theta)]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2J(θ)=m1∑i=1m[−yilog(hθ)−(1−yi)log(1−hθ)]+2mλ∑j=1nθj2
- 梯度下降函数与Linear Regression形式上一致
三、Week3 编程练习
-
Logistic Regression
-
Visuralizing the data
Function
plot(x,y,color,style...)plot函数提供的可选线属性如下表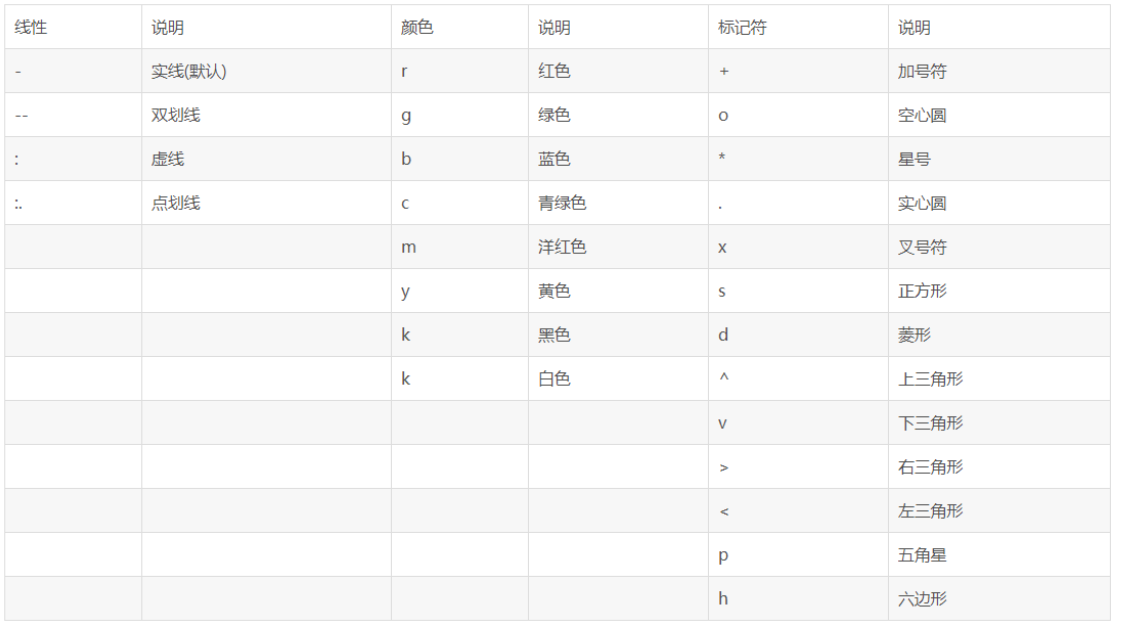
可选全局属性如下
LineWidth——指定线宽
MarkerEdgeColor——指定标识符的边缘颜色
MarkerFaceColor——指定标识符填充颜色
MarkerSize——指定标识符的大小
-
Find函数
- Find(X)找到X为真的结果,元素顺序按列排序
- [row,col] = find(X>0 & X<10,3),找到矩阵中满足条件得前三个元素,输出[row,col]坐标
-
size
-
一个返回值返回行、列,向量返回
-
size(A,n)
如果在size函数的输入参数中再添加一项n,并用1或2为n赋值,则 size将返回矩阵的行数或列数。其中r=size(A,1)该语句返回的是矩阵A的行数, c=size(A,2) 该语句返回的是矩阵A的列数
-
-
ones(a,b)
- 输出一个a*b的全1矩阵
-
fminunc Matlab自带的一个高级函数,可以找到最好的θ\thetaθ
-
contour
- 绘制等高线函数
-
Legend
- 给画出的图像放上图例
-
Linspace(1,100,2)
- 产生等差数列
-
matlab逻辑判断为真即可赋值=1
-
-
特别注意,在我编写代码的过程中对于矩阵的转置几次没有仔细查看,导致计算结果错误,这种错有时不会报错,但是你本想获得一个标量,会得到一个矢量;本想获得矢量,变成了标量,这是我对自己很大的一个收获
-
参考代码
-
写出S函数
g=1./(1+exp(-z)); -
求代价函数和相应的θ\thetaθ导数
J=(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)))/m; grad = (sigmoid(X*theta)-y)'*X/m; -
对模拟数值,求出大于一的预测量
p = sigmoid(X*theta)>=0.5; -
求正则化后的逻辑回归代价函数以及相应的θ\thetaθ导数
-
-
J=(-y'*log(sigmoid(X*theta))-(1-y)'*log(1-sigmoid(X*theta)))/m+lambda*sum(theta(2:size(theta),:).^2)/(2*m);
grad(2:n)= (sigmoid(X*theta)-y)'*X(:,2:n)/m+lambda*theta(2:n)'/m;
grad(1)= (sigmoid(X*theta)-y)'*X(:,1)/m;
```


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









