




 本文深入探讨了机器学习算法的评估方法,包括偏差与方差的诊断,正则化的合理应用,以及面对偏斜数据时的策略调整。通过实例解析,如垃圾邮件分类器的建立和处理数据不平衡问题,提供了实用的指导。
本文深入探讨了机器学习算法的评估方法,包括偏差与方差的诊断,正则化的合理应用,以及面对偏斜数据时的策略调整。通过实例解析,如垃圾邮件分类器的建立和处理数据不平衡问题,提供了实用的指导。
作为英语课程,读中文参考资料的确有助于理解,但是出于对以后更长久的学习优势考虑,笔记中我会尽量采用英文来表述,这样有助于熟悉专有名词以及常见语法结构,对于无中文翻译的资料阅读大有裨益。
一、Evaluating a Learning Algorithm
1. Deciding What to Try next
-

- 但是这大量都会浪费你六个月时间而无所帮助,接下来介绍“Machine Learning Diagnostic [.daɪəɡ’nɑstɪk]”来解决这个问题
2.Evaluating a Hypothesis
- 评估Hypothesis:取出少量数据按照7:3=训练集(随机选择):测试集
- 误差此处叫误分类率Multiclassification error,也成为0/1错分率
-
- 训练集60、交叉验证集20(Cross Vadidation)、测试集20
- 选择CV最小的哪一种hypothesis,这样测试的时候,测试集就与hypothesis毫无关系

二、Bias vs. Variance
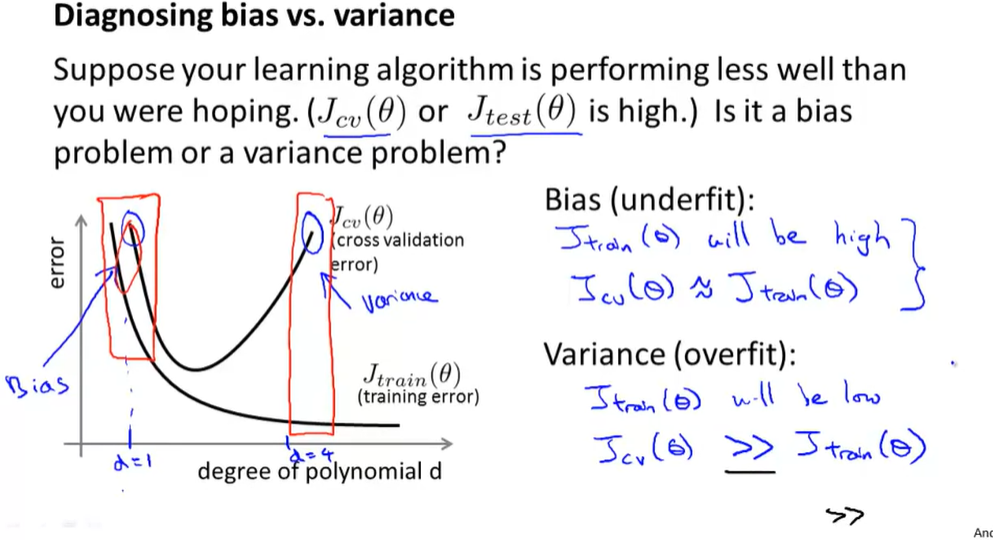
1.Diagnosing Bias vs. Variance
-
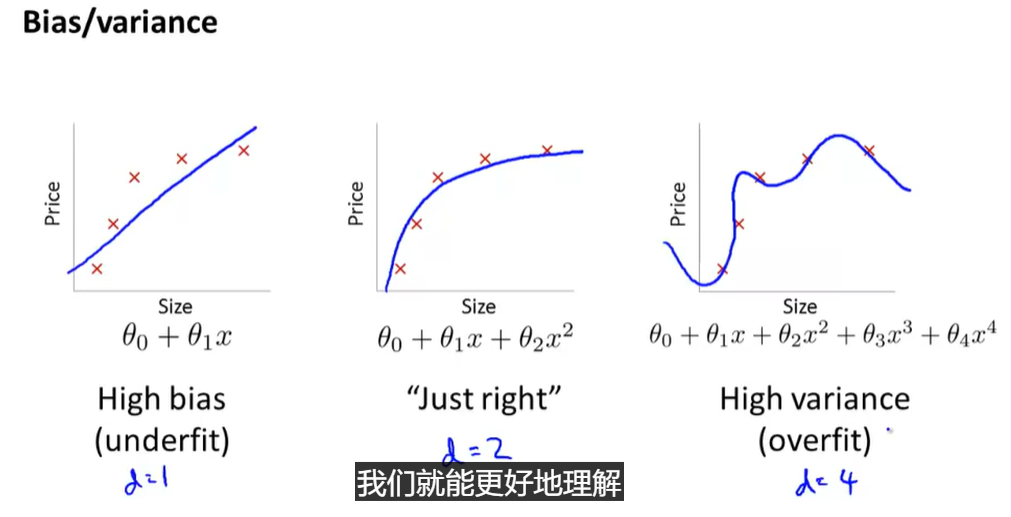
- 对于不同情况,偏差和方差的数值有所区别,如下图
-
2. Regularization and Bias/Variance
- 正则化λ\lambdaλ过大,施加给Θ\ThetaΘ的惩罚过大,导致Hypothesis最终近似一条直线
- 过小,则无意义
- 需要恰到好处,如何选取?
- 对Θ\ThetaΘ进行步进,同样的分开计算JtestJ_{test}Jtest和cv
3. Learning Curves学习曲线
- High bias
-
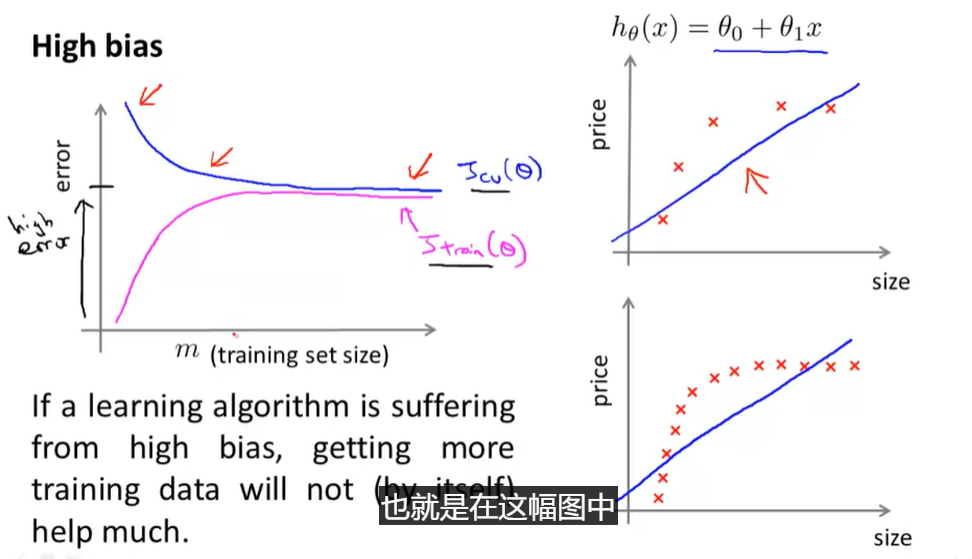
- 交叉验证误差和训练集误差都较高但很接近,此时选择更多训练集毫无意义(size为训练集)
-
- High Variance
-
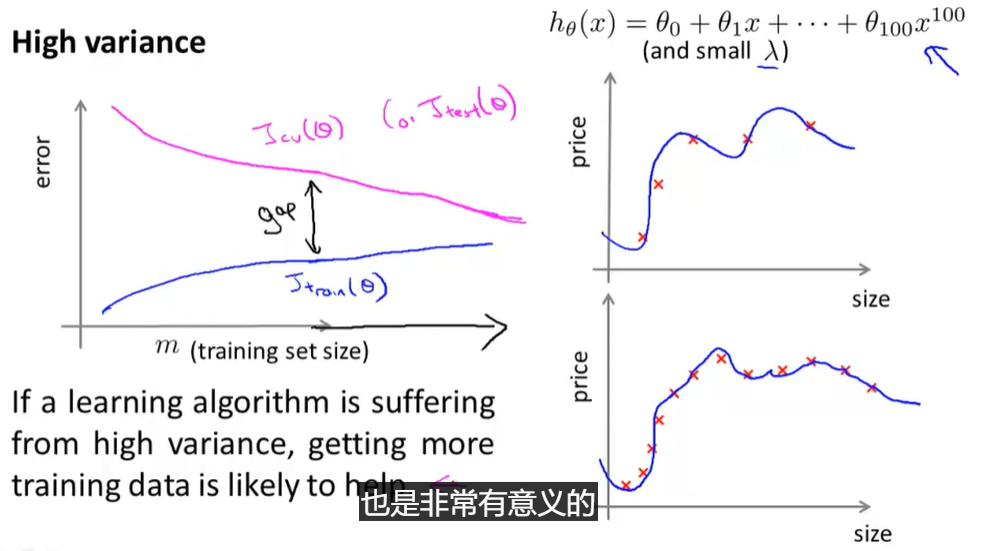
- 训练集误差和cv误差直接按相差很多,训练集误差小一些,cv误差较大
-
4. Deciding what to do next Revisited
-
decision
-
Getting more training examples: Fixes high variance
-
Trying smaller sets of features: Fixes high variance
-
Adding features: Fixes high bias
-
Adding polynomial features: Fixes high bias
-
Decreasing λ: Fixes high bias
-
Increasing λ: Fixes high variance.
-
Model Complexity Effects:Fixes high variance.
-
-
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.
三、Building a Spam Classifier
1. Prioritizing what to work on
- 提出忠告:系统性选择解决方案,永远比大多数人早晨醒来一拍脑门决定搞一堆数据然后跑上半年有用的多
2. Error Analysis误差分析
- 先用一个小系统迅速搭建跑起来,之后从分类错误中去寻找为何出了问题
- 最好有一种数值计算的方法来并行评估你的特征选取
四、Handling Skewed Data偏斜类问题
- 事例偏差极大,分类事例,患癌和无癌差别达到0.05/99.5
- 此时如果预测y=0,错误率仅有0.05,而神经网络大多99%准确率,此时用error analysis就不那么有用
1. Error Metrics for Skewed Classes
- 查准率Precision / 召回率,查全率Recall
-
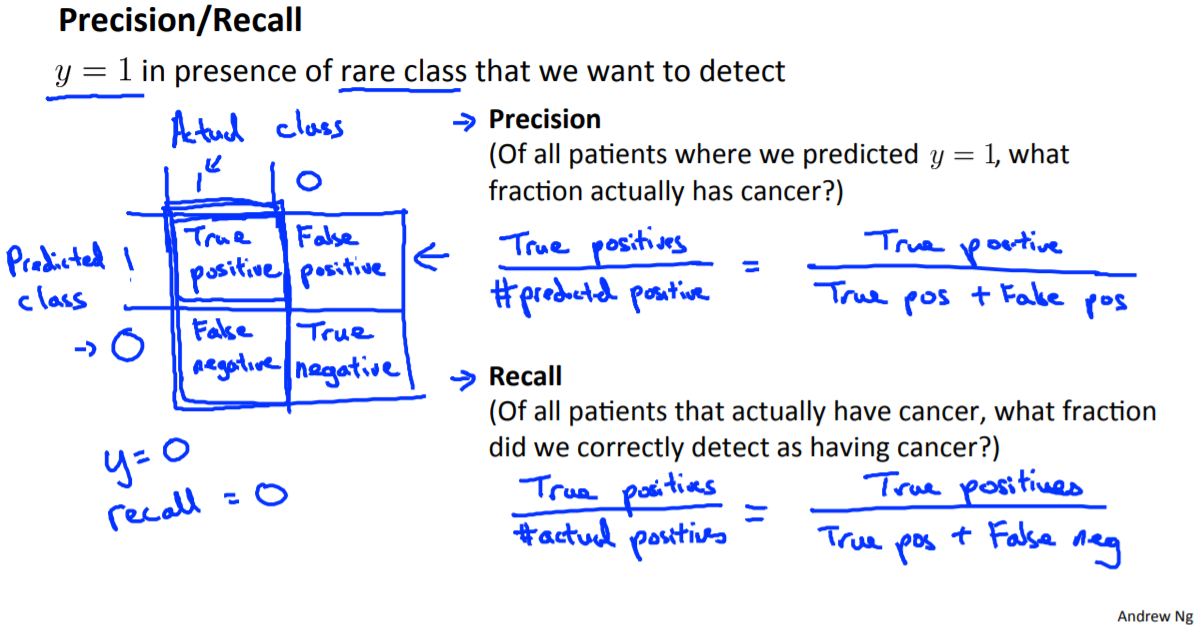 - 查准率=$\frac{\text{True pos} }{\text{all predict pos} }$
- 召回率=$\frac{\text{True pos} }{\text{all real pos} }$
- 查准率=$\frac{\text{True pos} }{\text{all predict pos} }$
- 召回率=$\frac{\text{True pos} }{\text{all real pos} }$
2. Trading off precision and recall
-
如果希望非常谨慎(通知癌症),可以选择查准率很高,但召回率很低,把h>0.9才认为y=1
-
相反的做法相应改变(比如筛选COVID疑似)
-
权衡P和R的公式,F公式:F=2PRP+RF=2\frac{PR}{P+R}F=2P+RPR
五、Using Large Data Set
1.Data for Machine Learning


















 1862
1862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









