 神经网络表达深入解析
神经网络表达深入解析





 本文主要探讨了神经网络的非线性模型,指出线性回归和逻辑回归的局限性,并引出了神经网络作为解决庞大计算量的有效方法。详细介绍了神经网络的模型表示,包括神经元模型、激活单元、权重和输入单元。此外,还阐述了神经网络在多类别分类中的应用,以及编程作业中的向量化矩阵计算技巧。
本文主要探讨了神经网络的非线性模型,指出线性回归和逻辑回归的局限性,并引出了神经网络作为解决庞大计算量的有效方法。详细介绍了神经网络的模型表示,包括神经元模型、激活单元、权重和输入单元。此外,还阐述了神经网络在多类别分类中的应用,以及编程作业中的向量化矩阵计算技巧。
作为英语课程,读中文参考资料的确有助于理解,但是出于对以后更长久的学习优势考虑,笔记中我会尽量采用英文来表述,这样有助于熟悉专有名词以及常见语法结构,对于无中文翻译的资料阅读大有裨益。
Week4-Neural Networks Representation神经网络:表达
一、Non-linear Hypothesis非线性模型(经过考虑,事实上hypothesis这里更像一个模型而非假设,事实上吴恩达在week1的课程中也指出hypothesis这个叫法不够恰当,但是大家都这么叫也就沿袭了)
Linear regression and Logistic regression都需要过多的features,这会导致拟合计算量极大
-
线性回归和逻辑回归都是多项式
-
使用排列组合决定参数数目的的非线性形式多项式

但是计算量肉眼可见依然极其庞大,因此引入一种存在很久的古老算法——Nerual Networks神经网络
第一块的第二节视频介绍了一下历史,etc.略过
二、Model Representation模型表示
-
neuron model:logistic unit
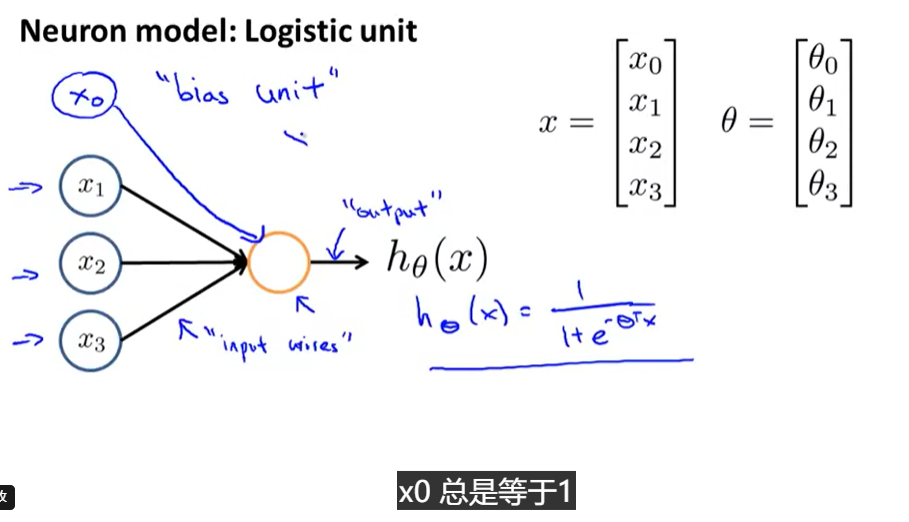
- activation unit 激活单元
- weight 权重θ\thetaθ, or paramaters 参数
- input units输入单元
- 第一层input layer,最后一层output layer,中间层为hidden layers,每一层可以加一个偏差单位bias unit(==1)
-
Neural Network
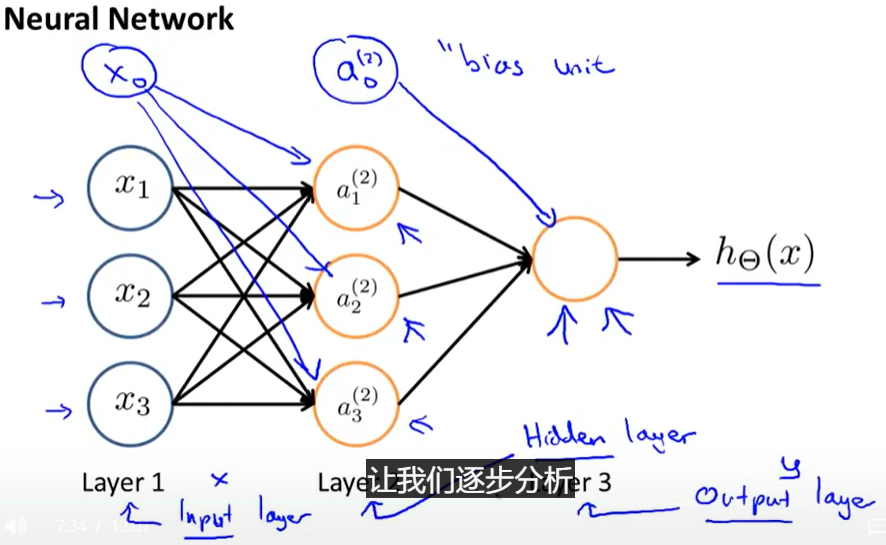
-
aija_i^jaij:=activation of unit i in layer j ;第j层的第i个神经元的激励,指输入后一个神经元得到的输出值
-
Θj\Theta^jΘj权重矩阵,控制着从j到j+1层的映射
-
g:激励函数

-
j层有sjs_jsj个神经元,j+1层有sj+1s_{j+1}sj+1个神经元,则权重矩阵维度为sj+1∗(sj+1)s_{j+1}*(s_j+1)sj+1∗(sj+1)最后的1是整体加一列,这是因为x1层中多了一个常数偏差单位,而a1层中的常数偏差单位并不需要被计算,Sj+1S_{j+1}Sj+1层是矩阵的行(每层输出结果数,a的数目),(SjS_jSj+1)是列
-
-
Forward Propagation:Vectorized implementation前向传播算法的矢量化

- z2=Θ1a1z^2=\Theta^1a^1z2=Θ1a1
- a2=g(z2)a^2=g(z^2)a2=g(z2),add a02=1a_0^2=1a02=1
- z3=Θ2a2z^3=\Theta^2a^2z3=Θ2a2
- hΘ(a)=a3=g(z3)h_\Theta(a)=a^3=g(z^3)hΘ(a)=a3=g(z3)
- 描述:神经网络所做的就像逻辑回归logistic,但并非用x1,x2作为输入特征,而是用a1,a2作为新的输入特征,此特征是自己产生的,通过计算效果比直接用X1,X2作为特征输入好,隐藏层变成了输入向量,这些特征值比x能更好的预测数据
三、Application(Examples)
-
单层神经元可以当作一个逻辑运算单元,看可以执行异或、与、非异或等

-
多层神经元

- 在取非运算的参数前放一个绝对值很大的负数作为权值
-
Multiclass Classification多类别分类
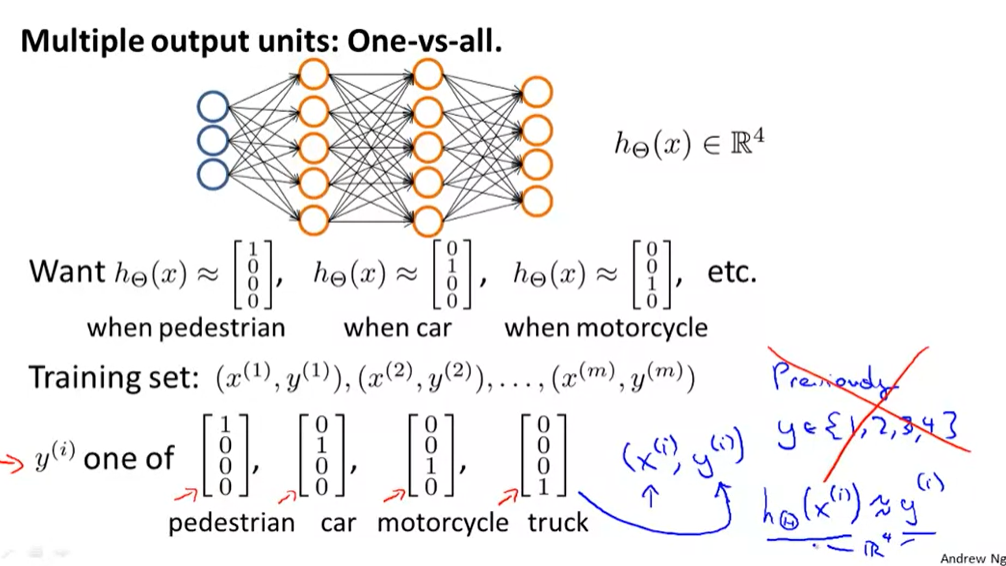
- 每个数据在output layer都只有一个1,也就是one of[1000]T[1 0 0 0]^T[1000]T的含义
四、Programming Assignment

-
第一部分变成任务和week3的正则化逻辑回归表达式一致,实际上课程意思week3就用loop来做矩阵计算,week4教你向量化矩阵计算
h_theta=sigmoid(X*theta);% 5*1 J=sum(-y'*log(h_theta)-(1-y)'*log(1-h_theta))/m+lambda*sum(theta(2:end,:).^2)/(2*m);% 1 demension % ============================================================= grad = grad(:); grad(1)= (h_theta-y)'*X(:,1)/m; grad(2:end)= (h_theta-y)'*X(:,2:n)/m+lambda*theta(2:n)'/m; -
One-vs-ALL Classfication
for c=1:num_labels initial_theta = zeros(n + 1, 1); options = optimset('GradObj', 'on', 'MaxIter', 50); all_theta(c,:) = ... fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ... initial_theta, options); end- 需要使用
fmincg函数而非fminunc - 这个新的优化函数是个坑==,照着注释原模原样用就可以了;
- 这一步题目中说的好像很多,但其实就相当于对每一个选定的C=1:num_label和相应的y==c代入,得到每个C对应的代价函数
- 需要使用
-
在第二步中已经得到了对应y==c(1~10)的Θ\ThetaΘ函数,那么这里分别带入c的值,h=1也就是预测了这个c值,否则就不是;
[c p]=max(sigmoid(X*all_theta'),[],2);% X m*(n+1) all_theta 1*n+1 p=m*1 a_2=m*1-
注意matlab中max函数用法
C = max(A,[],dim) 返回A中有dim指定的维数范围中的最大值,dim=1按列,dim=2按行
如果A是一个矩阵,max(A)将A的每一列作为一个向量,返回一行向量包含了每一列的最大元素
[a b ]=max(A),a是最大值,b是最大值的index(行/列号)
-
-
Neural Networks
a2=sigmoid(X*Theta1'); % X m*n+1 Theta 25 * n+1 a2=[ones(size(a2,1),1) a2]; %m*26 a3=sigmoid(a2*Theta2'); [maxnum index]=max(a3,[],2); p=index;- 最简单的三层前向算法神经网络


















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









