







参考:https://www.cnblogs.com/AndyJee/p/7879765.html
FM 适用于高度稀疏的数据场景
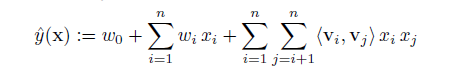
w是输入特征的参数,《vi,vj》是输入特征i,j 间的交叉组合特征,v是k维向量。
前面两个就是我们熟知的线性模型,后面一个就是我们需要学习的交叉组合特征,正是FM区别与线性模型的地方。
为什么要通过向量v 的学习方式而不是简单地wij 参数?
在稀疏的条件下,这样的表达方法打破了特征的独立性,更好地挖掘特征之间的相关性,
模型复杂度是O(kn)
应用: 回归,分类,排序。
模型学习方法: SGD
优点: 通过向量交叉学习的方式来挖掘特征之间的相关性,:在高度稀疏的条件下更好地挖掘数据特征间的相关性,尤其是对训练样本中没出现的交叉数据。计算目标函数和随机梯度下降做优化学习时都可以在线性时间内完成。
FM 对比SVM:
区别: SVM 的二元特征交叉参数是独立的,如Wij,而FM 的二元特征交叉参数是两个k 维的向量vi,vj,<vi,vj> 和<vi,vk> 不是独立的,而是相互影响的。
FM : 可以在原始形式下进行优化学习,基于kernel 的非线性SVM通常要在对偶形式下进行; FM 的模型预测是和训练样本独立,而SVM 与部分训练样本有关,即支持向量。
2 FFM 模型:
https://blog.youkuaiyun.com/lyx_yuxiong/article/details/81238855
改进: 不但认为特征和特征之间潜藏着关系,还认为特征和特征类型之间潜藏着关系。
特征类型:某些特征实际上是来自数据的同一个字段
FM 认为每个特征有一个隐因子向量,FFM 认为每个特征有f个隐因子向量,这里的f 便是特征一共来自多少个field ,二阶部分变成ΣΣ<Vi,fj,Vj,fi>xi xj。
FM和FFM 实践中,需要对样本做归一化处理。
总结: 因子分解机也算矩阵分解算法的一种,因为它的学习结果也是隐因子向量,也是通过隐因子向量的点积代替原来的单个权重参数。
在DSP 或者推荐场景中,FFM 主要用于评估站内的CTRCTR和CVR,即一个用户多商品的潜在点击率和点击后的转化率,CTR和CVR 预估模型都是在线性训练,然后线上预测。
-
用户相关的特征
年龄、性别、职业、兴趣、品类偏好、浏览/购买品类等基本信息,以及用户近期点击量/购买量/消费额等统计信息 -
商品相关的特征
商品所属品类、销量、价格、评分、历史CTR/CVR等信息 -
用户-商品匹配特征
浏览/购买品类匹配、浏览/购买商家匹配、兴趣偏好匹配等 -
FFM 是默认进行样本数据的归一化,特征的归一化,省略0 值特征。
3 DeepFM 的结构
FM和DNN 的特征结合:同时学习低阶和高阶的特征交叉,主要是由FM 和DNN 两部分组成,底部共享同样的输入,模型表示为:
![]()
Deep 部分: 深度部分是一个前馈神经网络,与图像或语音类的输入不同,CTR 的输入一般是及其稀疏的,因此需要重新设计网络结构,在第一层隐藏层之前,引入一个嵌入式来完成输入向量压缩到低位稠密向量。
嵌入层的结构:
1) 尽管不同的filed 的输入长度不同,但是embedding 之后向量的长度均为k。2) 在FM 中得到的隐变量Vik 作为嵌入层网络的权重。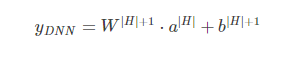

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









