




数据处理
训练数据:
删除历史数据NA, 重复数据, 提取历史数据中竞价队列的所有广告曝光次数,得到每个广告每天的曝光次数
删除静态数据的NA, 重复, 创建时间为-1的数据
每个广告每天的曝光数据和静态数据merge, 按照广告id聚合,得到每个广告的平均曝光数据作为训练数据
测试数据:
原始测试数据按照广告聚合得到每个广告数据, 每个广告数据和静态数据merge作为测试数据
结果记录
之前预测的数据分布是3,3,5,4300, 均值是16-20, 方差是140
----------------------------------------------------------------------------------------------
2019.5.26 12:00:00 baseline 81.3734
主要操作: lgb + train_test_split, 填充负数, 填充历史, 1000以下预测曝光除3
训练数据是 均值是7.7 方差是103, 1,2,4, 最大是23706
原始结果的均值8 方差2.48,最大是124 没有负数
填充负数 均值增加到37, 方差增加到155, 最大是4259, 1000以上的结果的个数20
1000以下结果/3 均值降到17, 方差将到137, 最大值不变
最后结果的均值17 方差137 1.37 2.61 5.78
Name: 预测曝光, dtype: float64
count 4980.000000
mean 17.750297
std 137.943265
min 0.333333
25% 1.379464
50% 2.615156
75% 5.782051
max 4259.000000
Name: 预测曝光, dtype: float64
[7] valid_0's l1: 8.57168 valid_0's mape: 3.48839 valid_0's l2: 1056.11
2019.5.26 16:33 label log化, 结果exp回来 + 10-1000结果/5 -- 79.93 降了
预测的原始结果 3.25 3.25 4.73 34.78, 填充历史2.3 4.1 17 4259(75%数字太大了) 结果/5
最后的结果2.2 3.4 6.6 均值是15.34 方差是136
[270] valid_0's mape: 0.367151 valid_0's l2: 0.594309 valid_0's l1: 0.548976
2019.5.26 17:22 7-1000结果/5 -- 79.72 降了
最后的结果1.5 2.3 6 均值是14 方差是136.53
[5] valid_0's l2: 1308.41 valid_0's l1: 8.87733 valid_0's mape: 3.4552
2019.5.26 19:04 -- 77.5867 降了
tst_his_df['预测曝光'] = ((tst_his_df['预测曝光'] - min_val) / ((max_val - min_val))*1.1) * 4000
count 4980.000000
mean 38.162273
std 160.254893
min 0.000000
25% 3.243055
50% 7.233443
75% 17.808048
max 4400.000000
Name: 预测曝光, dtype: float64
2019.5.26 19:58
最后结果1舍2入 submission2019-05-26 07-56-49--81.8745 提了0.5
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.122490
std 137.932073
min 1.000000
25% 2.000000
50% 3.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.26 20:25 加入good_type 感觉没有变化, 没有提交, 后来都加入了商品类型
count 4980.000000
mean 18.108032
std 137.931734
min 1.000000
25% 2.000000
50% 3.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
历史曝光量 历史pctr ==>
人群定向 ==> countvector
2019.5.26 20:53 曝光和操作数据融合
加入目标转换类型特征 -- 各项指数没变 -- submission2019-05-26 11-08-56--81.5544 -- 降了
选择的列是 ['账户id', '商品id', '商品类型', '行业id', '素材尺寸', '目标转化类型']
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.091165
std 137.933262
min 1.000000
25% 2.000000
50% 3.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[4] valid_0's mape: 3.34169 valid_0's l1: 9.17363 valid_0's l2: 2802.78
2019.5.26 20:53 曝光和操作数据融合
加入计费类型特征 submission2019-05-26 11-10-45 -- 82.124 -- 升了
选择的列是 ['账户id', '商品id', '商品类型', '行业id', '素材尺寸', '计费类型']
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.135141
std 137.936628
min 1.000000
25% 2.000000
50% 3.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[26] valid_0's l1: 9.36731 valid_0's l2: 22552 valid_0's mape: 2.92682
2019.5.26 20:53 曝光和操作数据融合
加入计费类型特征, 目标转化类型 submission2019-05-26 11-13-15--82.3879 -- 升了
选择的列是 ['账户id', '商品id', '商品类型', '行业id', '素材尺寸', '计费类型', '目标转化类型']
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.154217
std 137.940958
min 1.000000
25% 2.000000
50% 3.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[40] valid_0's l2: 21436.8 valid_0's mape: 2.82398 valid_0's l1: 9.12206
2019.5.28 10:17 将文件的最大值修改成4400
submission2019-05-26 11-13-15--82.3878 结果降了-- 0.0001
2019.5.26 20:53 曝光和操作数据融合 使用类别特征
catagory_fea = ['good_type', 'cost_type', 'target_trans_type'] submission2019-05-27 02-40-32 -- 82.044 -- 降了
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.090161
std 137.935338
min 1.000000
25% 2.000000
50% 3.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
心得: 加入新特征的方法: 一次加入一批, 然后每次去掉重要性分数最低的一个. 或者中去掉特征之间相关性最高的一个
每一天NA的曝光数据为0
每一天重复的数据也很少1,2个左右
-------------------------------------------------
加入pctr等特征
2019.5.27 15:40 其他数据不动,使用FM模型
submission2019-05-27 03-37-19--82.7083
Name: 预测曝光, dtype: float64
count 4980.000000
mean 17.762450
std 137.969914
min 1.000000
25% 2.000000
50% 2.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 4999.414062 9285.542969 3.248267 0.04
[------------] Average mse_loss: 6427.691406
[------------] Average MAPE: 3.415881
2019.5.27 17:00 FM模型使用onehot -- 结果下降
submission2019-05-27 05-15-19--81.5405.csv
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.079920
std 137.934418
min 1.000000
25% 2.000000
50% 3.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 940.961914 17377.232422 3.222898 0.02
[------------] Average mse_loss: 6419.920410
[------------] Average MAPE: 3.465045
[ ACTION ] Finish Cross-Validation
[------------] Load model from ./fm_model/model_2019-05-27 05-15-19.txt
[------------] Loss function: squared
[------------] Score function: fm
[------------] Number of Feature: 30
[------------] Number of K: 4
2019.5.27 17:30 LR模型使用
LR模型不使用onehot结果结果全是负数!
LR模型使用onehot结果大量是负数, 最大结果非常小!
2019-05-27_06-10-17_LR_model -- 84.3123
使用LR模型, onehot,其他都没有改变
预测的原始结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 0.277387
std 4.304302
min -11.968400
25% -2.908445
50% 0.744502
75% 3.423118
max 10.513900
Name: 预测曝光, dtype: float64
规则调整之后
Name: 预测曝光, dtype: float64
count 4980.000000
mean 17.360442
std 138.017995
min 0.000000
25% 1.000000
50% 2.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 5054.579102 995.583496 3.016638 0.01
2019.5.27 18:30 LR模型使用 + 最大值改成4300 结果没变
结论: 最大结果应该是4300, 修改最大值不会影响结果
-------------------------- 2019.5.28 数据记录 ---------------------------------------------------------------
expo文件是广告,曝光;expo_all 是所有天的集合;
static_all 是处理后的静态文件
expo_static 是expo_all inner merge static;
train_data 是expo_static 按照ad id group之后的数据
test_data.csv 是 test 和 static merge后, 按照ad id group之后的数据
train_data_op 是 train data 加入op操作数据后的数据
------------------------------------------------------------------------------------------------------------
2019.5.28 已经服务器上的所有数据更新为最新
观察竞价广告队列发现
1. 所有广告是按照total 分数降序排序, 如果前面的策略被命中策略的话, 就不可能曝光, 最终曝光的是第一位没有被策略命中的广告
被策略命中的次数应该是强特
2. 前面的广告的bid 和 pctr 相对较大, 但是不是绝对的大
3. quality 差异很大, 前面的比较大
4. 统计test出现的位置, 如果是前10, 可能会出现, 其他大概率是不会出现的
------------------------------------------------------------------------------------------------------------
2019.5.30
将一个广告id所有请求的平均的total作为当前广告的total,但是有些广告对应的req 是缺失的, 缺失比例大约是1/3....
2019.05.30 22:00 加入特征
之前 2019-05-26_11-13-15_baseline--82.3879.py.log
submission2019-05-30 09-39-36--82.6278.csv -- 升了0.24
selected_cols = ['账户id', '商品id', '商品类型', '行业id',
'素材尺寸', '目标转化类型', '计费类型', '广告id长度',
'召回次数', '中位数请求时间', '最小请求时间',
'平均请求时间', '最大请求时间', '请求时间跨度', '策略过滤次数']
[25] valid_0's l1: 5.79832 valid_0's mape: 1.65594 valid_0's l2: 1458.17
原始结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 13.777041
std 43.662314
min 3.634222
25% 4.264988
50% 5.649794
75% 9.852245
max 1710.064748
Name: 预测曝光, dtype: float64
最终结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.185542
std 137.944906
min 1.000000
25% 2.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.05.30 22:00 加入特征
submission2019-05-30 09-54-24--82.6383.csv -- 提了0.01
selected_cols = ['账户id', '商品id', '商品类型', '行业id',
'素材尺寸', '目标转化类型', '计费类型', '广告id长度',
'召回次数', '中位数请求时间', '最小请求时间',
'平均请求时间', '最大请求时间', '请求时间跨度', '策略过滤次数', '竞价bid_最小',
'竞价bid_最大', '竞价bid_平均', '竞价bid_标准差',
'竞价bid_中位数', 'pctr_中位数', 'pctr_标准差', 'pctr_平均',
'pctr_最小', 'pctr_最大']
[26] valid_0's l1: 5.30009 valid_0's mape: 1.65678 valid_0's l2: 930.778
原始结果 Name: 预测曝光, dtype: float64
count 4980.000000
mean 14.237187
std 30.447519
min 3.626409
25% 4.312783
50% 5.551307
75% 10.753268
max 691.781880
Name: 预测曝光, dtype: float64
最终结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.222289
std 137.943925
min 1.000000
25% 2.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.05.30 22:30 lgb加入特征
结论: quality_ecpm 和 total 效果很好, 提了1个点
selected_cols = ['账户id', '商品id', '商品类型', '行业id',
'素材尺寸', '目标转化类型', '计费类型', '广告id长度',
'召回次数', '中位数请求时间', '最小请求时间',
'平均请求时间', '最大请求时间', '请求时间跨度', '策略过滤次数', '竞价bid_最小',
'竞价bid_最大', '竞价bid_平均', '竞价bid_标准差',
'竞价bid_中位数', 'pctr_中位数', 'pctr_标准差', 'pctr_平均',
'pctr_最小', 'pctr_最大', 'quality_ecpm_最大', 'quality_ecpm_最小',
'quality_ecpm_中位数', 'quality_ecpm_标准差',
'quality_ecpm_平均', 'total_ecpm_最大', 'total_ecpm_标准差', 'total_ecpm_平均',
'total_ecpm_中位数', 'total_ecpm_最小']
[60] valid_0's l2: 17007.9 valid_0's l1: 5.21241 valid_0's mape: 1.07974
原始结果 Name: 预测曝光, dtype: float64
count 4980.000000
mean 12.164074
std 20.455416
min 1.832765
25% 3.320744
50% 4.876342
75% 10.588635
max 297.403358
Name: 预测曝光, dtype: float64
最终结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.054217
std 137.955341
min 1.000000
25% 1.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.31 9.30
使用LR模型+所有特征
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 12010293.000000 36780568.000000 1432.346802 0.02
[------------] Average mse_loss: 20542648.000000
[------------] Average MAPE: 1814.031128
原始结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean -663.213520
std 2692.924828
min -21146.800000
25% -1247.220000
50% -53.021250
75% 811.627000
max 3752.890000
Name: 预测曝光, dtype: float64
最终结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 94.012450
std 355.869474
min 0.000000
25% 1.000000
50% 3.000000
75% 19.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.31 10:00
使用LR模型+所有特征+数值特征归一化
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 8252700.000000 7502644.500000 1825.759766 0.01
原始结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 147.622869
std 567.261995
min -1555.620000
25% -246.452250
50% 162.894000
75% 575.841000
max 1506.980000
Name: 预测曝光, dtype: float64
最终结果
Name: 预测曝光, dtype: float64
count 4980.000000
mean 63.672490
std 215.128863
min 0.000000
25% 1.000000
50% 4.000000
75% 29.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.31 10:05
lgb 去掉特征 'cost_type'
submission2019-05-30 22-09-25--83.4154.csv -- 降了0.3
[37] valid_0's mape: 1.37593 valid_0's l2: 351.826 valid_0's l1: 4.70793 L1小了,L2小了,MAP大了
结论: 还是要看MAP
原始结果
count 4980.000000
mean 11.496247
std 17.773420
min 2.957714
25% 3.791247
50% 5.236900
75% 10.165442
max 242.996684
Name: 预测曝光, dtype: float64
最终结果0
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.064257 -- 均值变大了
std 137.951023
min 1.000000
25% 1.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.31 10:10
lgb 去掉特征 'ad_len'
submission2019-05-30 22-21-57--83.858.csv 提了0.06
[80] valid_0's l1: 5.27914 valid_0's l2: 15858.5 valid_0's mape: 1.00398
Name: 预测曝光, dtype: float64
count 4980.000000
mean 12.520212
std 21.952843
min 0.000000
25% 3.031346
50% 4.891559
75% 11.221659
max 326.489770
Name: 预测曝光, dtype: float64
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.063253
std 137.958223
min 1.000000
25% 1.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019-6-1 :用我的模型:
/data1/data/chenli/for_25/total_data/code/data/submit_data/submission2019-06-01 17-53-22.csv
83.5896
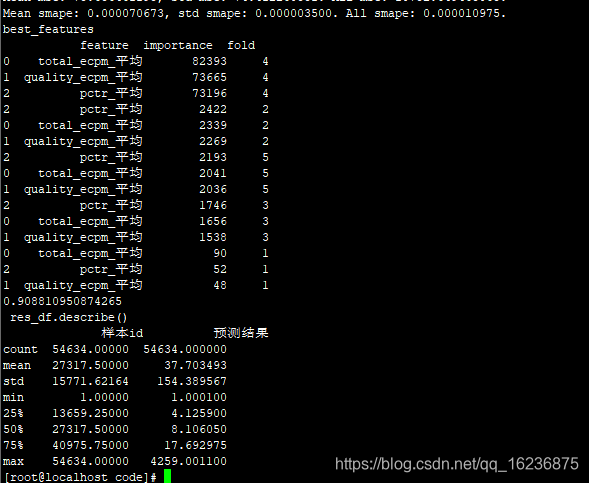
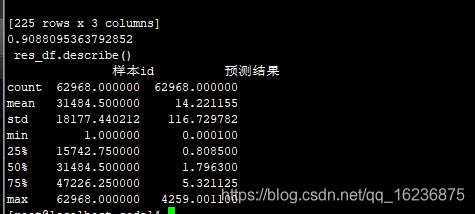
0.90881095087426
Mean mse: 85.099453678, std mse: 63.524667479. All mse: 10124.132823787.
Mean smape: 0.000042089, std smape: 0.000016054. All smape: 0.000009496.
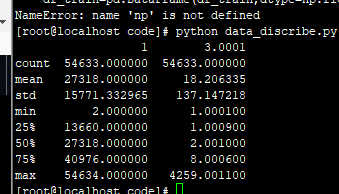
cl 6-2:84.0637 /data1/data/chenli/for_25/total_data/code/data/submit_data/submission2019-06-01 23-19-39_84.0637.csv
调整:lgb参数叶子数10-40,lr:0.1-0.01
Mean mse: 83.134055811, std mse: 64.502434918. All mse: 10145.485771066.
Mean smape: 0.000044071, std smape: 0.000009033. All smape: 0.000002198.
cl用我初赛的调整规则: 6-2 /data1/data/chenli/for_25/total_data/code/data/submit_data/my_submit/submission2019-06-02 11-22-02.csv 80.4256。弃用,
cl 规则: 用bid/10000 :
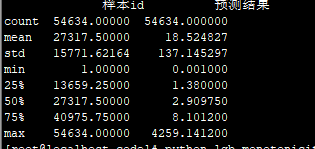
82.6107
cl 规则: 用bid/10000 .1000 以下的3.3 82.6699
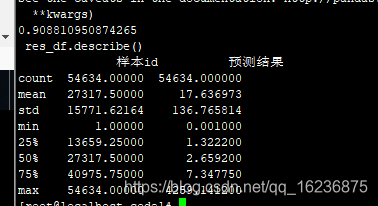
cl 规则: 用rank/10000 .1000 以下的3.3 84.0936
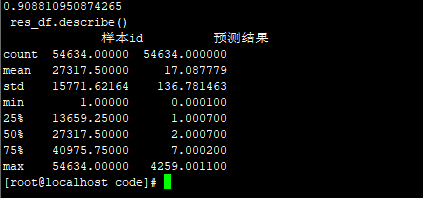
cl 参数:叶子30 lr=0.005
84.0945
submission2019-06-02 13-25-41_84.0945.csv
Mean mse: 83.051070034, std mse: 64.626807090. All mse: 10145.589866755.
Mean smape: 0.000046320, std smape: 0.000006984. All smape: 0.000000352.
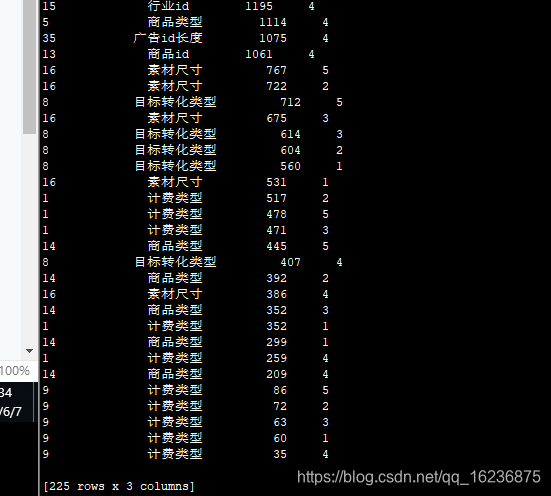
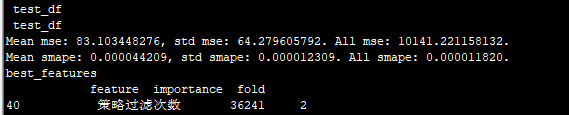
best_features
feature importance fold
13 策略过滤次数 243038 5
13 策略过滤次数 240704 1
13 策略过滤次数 240372 2
13 策略过滤次数 239473 3
13 策略过滤次数 211152 4
12 请求时间跨度 148620 3
12 请求时间跨度 146663 5
7 召回次数 146625 1
12 请求时间跨度 146503 1
12 请求时间跨度 146074 2
7 召回次数 145473 5
7 召回次数 145030 3
7 召回次数 144556 2
7 召回次数 137407 4
12 请求时间跨度 128755 4
0 账户id 127944 3
0 账户id 126633 1
0 账户id 126426 5
0 账户id 124389 2
0 账户id 120806 4
29 total_ecpm_最大 111094 2
29 total_ecpm_最大 111020 5
29 total_ecpm_最大 110954 1
25 quality_ecpm_最小 110244 5
29 total_ecpm_最大 109948 3
25 quality_ecpm_最小 109926 2
25 quality_ecpm_最小 109628 3
33 total_ecpm_最小 107906 1
32 total_ecpm_中位数 106518 5
22 pctr_最小 105714 5
.. ... ... ...
28 quality_ecpm_平均 58432 4
26 quality_ecpm_中位数 58196 3
26 quality_ecpm_中位数 57645 4
11 最大请求时间 57096 5
11 最大请求时间 51074 4
10 平均请求时间 37178 3
10 平均请求时间 37014 2
10 平均请求时间 36499 5
10 平均请求时间 36370 1
10 平均请求时间 31805 4
5 目标转化类型 31305 1
5 目标转化类型 30638 5
5 目标转化类型 30594 3
5 目标转化类型 30336 2
5 目标转化类型 29224 4
4 素材尺寸 25345 1
4 素材尺寸 24998 3
4 素材尺寸 24777 2
4 素材尺寸 24702 5
4 素材尺寸 22305 4
2 商品类型 16579 1
2 商品类型 16259 4
2 商品类型 16219 3
2 商品类型 16192 2
2 商品类型 15994 5
6 计费类型 4015 1
6 计费类型 3926 5
6 计费类型 3905 2
6 计费类型 3856 3
6 计费类型 3467 4
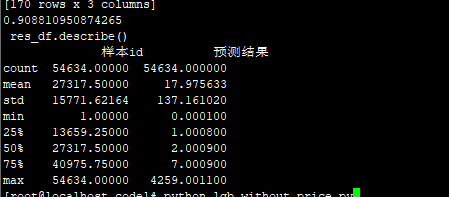
[170 rows x 3 columns]
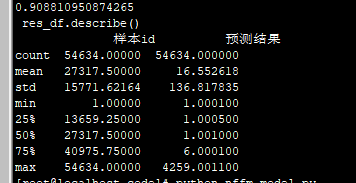
0.908810950874265
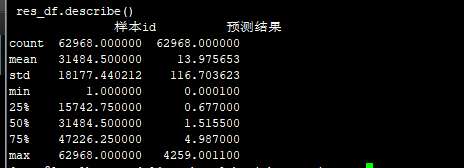
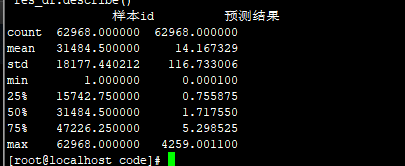
res_df.describe()
样本id 预测结果
count 54634.00000 54634.000000
mean 27317.50000 17.963333
std 15771.62164 137.160860
min 1.00000 0.000100
25% 13659.25000 1.000800
50% 27317.50000 2.000900
75% 40975.75000 7.000900
max 54634.00000 4259.001100
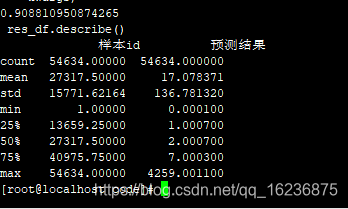
去掉计费类型和商品类型:叶子30 lr=0.005 84.0794 降低了0.02
Mean mse: 82.953286541, std mse: 64.514687994. All mse: 10126.033240696.
Mean smape: 0.000046848, std smape: 0.000007149. All smape: 0.000000863.
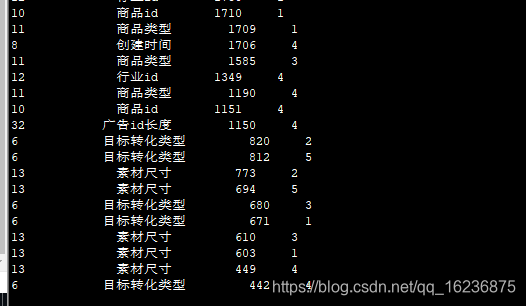
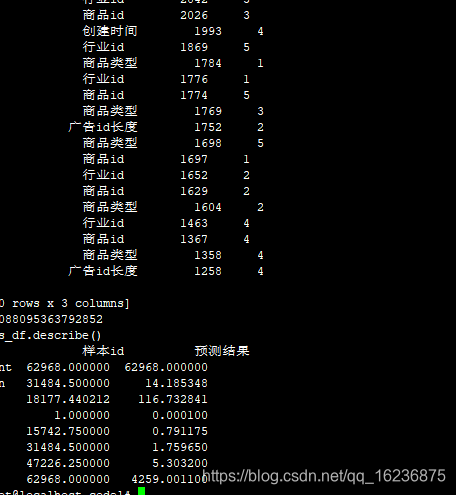
best_features
feature importance fold
11 策略过滤次数 168835 5
11 策略过滤次数 168454 1
11 策略过滤次数 167628 3
11 策略过滤次数 167468 4
11 策略过滤次数 166432 2
5 召回次数 101993 4
10 请求时间跨度 97534 3
5 召回次数 97049 1
10 请求时间跨度 95937 2
10 请求时间跨度 95806 5
5 召回次数 95589 5
10 请求时间跨度 94923 1
5 召回次数 94887 3
10 请求时间跨度 94168 4
5 召回次数 92589 2
0 账户id 89961 4
0 账户id 84576 3
0 账户id 83840 1
0 账户id 83785 5
0 账户id 82334 2
23 quality_ecpm_最小 76937 2
23 quality_ecpm_最小 76703 5
23 quality_ecpm_最小 75846 3
23 quality_ecpm_最小 75417 1
27 total_ecpm_最大 71458 4
27 total_ecpm_最大 71133 3
27 total_ecpm_最大 71125 2
27 total_ecpm_最大 70523 5
20 pctr_最小 70261 4
27 total_ecpm_最大 70255 1
.. ... ... ...
26 quality_ecpm_平均 40346 5
26 quality_ecpm_平均 39981 3
19 pctr_平均 39827 5
26 quality_ecpm_平均 39528 1
19 pctr_平均 39229 1
9 最大请求时间 38893 2
19 pctr_平均 38589 3
9 最大请求时间 38466 3
24 quality_ecpm_中位数 38159 5
9 最大请求时间 38047 5
9 最大请求时间 37885 4
19 pctr_平均 37645 2
9 最大请求时间 36784 1
24 quality_ecpm_中位数 36610 2
24 quality_ecpm_中位数 36164 3
4 目标转化类型 25474 4
8 平均请求时间 24734 5
8 平均请求时间 24419 2
8 平均请求时间 24292 3
8 平均请求时间 24237 4
4 目标转化类型 24139 1
8 平均请求时间 24093 1
4 目标转化类型 23662 5
4 目标转化类型 23553 2
4 目标转化类型 23194 3
3 素材尺寸 18965 1
3 素材尺寸 18827 3
3 素材尺寸 18662 4
3 素材尺寸 18643 2
3 素材尺寸 18565 5
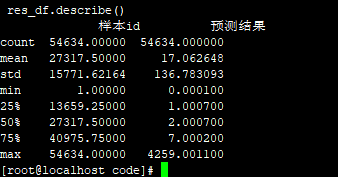
2019.5.31 10:30
lgb 去掉特征 'ad_len' quality_ecpm_平均
submission2019-05-30 23-00-18--83.729.csv 降了0.1
[62] valid_0's mape: 1.0744 valid_0's l2: 16213.5 valid_0's l1: 5.07211
结论: mape升了结果就变差!
Name: 预测曝光, dtype: float64
count 4980.000000
mean 12.910828
std 24.089025
min 2.177680
25% 3.326086
50% 4.895894
75% 10.793466
max 344.191028
Name: 预测曝光, dtype: float64
Name: 预测曝光, dtype: float64
count 4980.000000
mean 18.073293
std 137.956444
min 1.000000
25% 1.000000
50% 2.000000
75% 7.000000
max 4259.000000
Name: 预测曝光, dtype: float64
2019.5.31 11:00
lgb 去掉特征 'ad_len' + 尝试去掉各种低分特征, 结果一直下降, 使用特征选择去掉特征, 结果一直下降
使用的特征选择算法有:
1. 方差消除 效果太差
2. k-best 因为不是有负数, 弃用
3. RFE + svc 因为svc不能有做回归, 弃用
4. RFE + LR 需要设置LR的label属性, 弃用
5. RFE + ridge 效果太差
5. tree_select 需要设置label熟悉, 弃用
2019.5.31 12:10
FM模型 + 去掉特征 'ad_len'
submission2019-05-31 00-01-21--84.6512.csv
[ ACTION ] Cross-validation: 3/3:
[------------] Epoch Train mse_loss Test mse_loss Test MAPE Time cost (sec)
[ 100% ] 10 5118.260742 1015.504517 3.358087 0.07
[------------] Average mse_loss: 3750.202393
[------------] Average MAPE: 3.360003
Name: 预测曝光, dtype: float64
count 4980.000000
mean 2.428600
std 0.000003
min 2.428600
25% 2.428600
50% 2.428600
75% 2.428600
max 2.428660
Name: 预测曝光, dtype: float64
Name: 预测曝光, dtype: float64
count 4980.000000
mean 17.442771
std 138.007226
min 1.000000
25% 1.000000
50% 1.000000
75% 6.000000
max 4259.000000
Name: 预测曝光, dtype: float64
6.3 号:nffm :80多,ffm/fm:84.5675
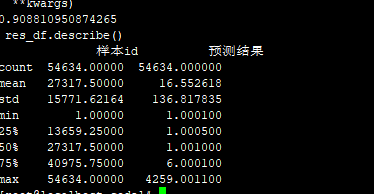
新的统计:ffm 81.99 "策略过滤次数","total_ecpm_平均","quality_ecpm_平均","pctr_平均" ,没有2舍8入,使用原来的填充
新的统计,没有0:ffm 81.5165 "策略过滤次数","total_ecpm_平均","quality_ecpm_平均","pctr_平均" ,没有2舍8入,使用原来的填充
新的数据:81.6338,没有2舍8入; 有2舍8入:81.3722
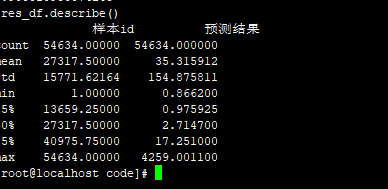
lgb 使用原来的填充,用四舍五入和除以3.3的:76.1248
lgb 不用四舍五入和除以3.3的:submission2019-06-04 11-00-51.csv 73.7732
lgb 使用原来的数据的这三个特征来对比,使用原来的填充,不用四舍五入和除以3的: 76.4056
结论:原来的数据好,要用四舍五入和除以3的
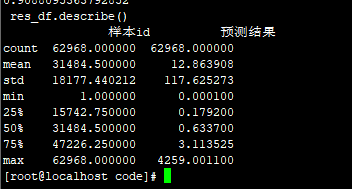
不用四舍五入和除以3.3的:81.8782
使用原来的数据的这三个特征来对比,使用原来的填充,不用四舍五入和除以3.3的:81.8782
6-7 :B 榜:lgb:
7个基本特征:76.8695
lgb :所有原来的特征:82.6607
![]()
3 45个特征:lgb 82.1322

3.1 去掉商品类型和计费类型:lgb 82.2562
3.2 去掉素材尺寸和目标转化类型:82.1751

4 ffm:80.3065所有原来的特征: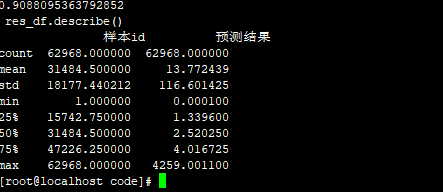
5nffm :所有原来的特征 78.7189
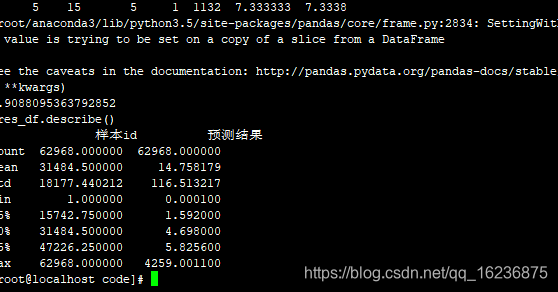
7 fm:所有原来的特征 79.8873
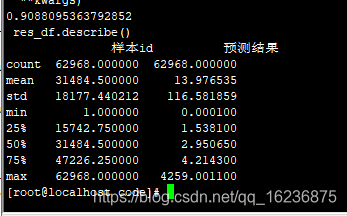
8 LR model :74.0182,有标准化
没有标准化:73.5481
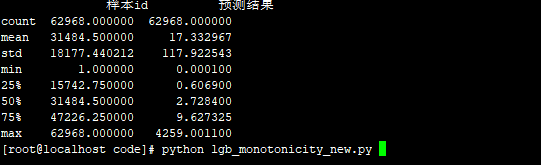
9 队友的FM 模型:83.17.没有标准化
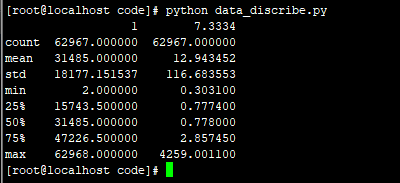
标准化了:79.9608
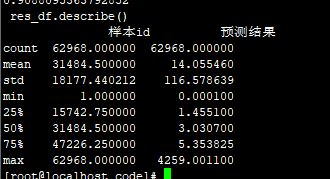
不标准化+四舍五入 83.2593
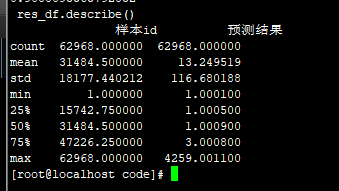
/3.4:83.263
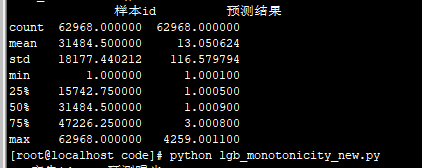
/3.6 83.1658
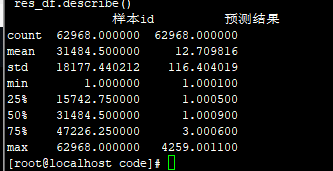
/3.5 83.2212
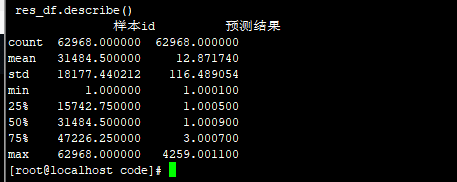
/3.4 >1000的除以2 83.2876
/3.4 >1000的除以7 :83.2967
把历史值放在后面:81.6505
历史值 /3.3 83.2064
test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光']=(dat1 - dat1.min())/(dat1.max() - dat1.min())*1500 83.395
test_group_df.loc[( test_group_df.预测曝光 < 1000), '预测曝光'] =(dat2 - dat2.min())/(dat2.max() - dat2.min())
test_group_df.loc[(test_group_df.预测曝光 > 1000), '预测曝光'] = test_group_df.loc[
(test_group_df.预测曝光 > 1000), '预测曝光'].values /7
test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光']=(dat1 - dat1.min())/(dat1.max() - dat1.min())*1500
83.3971
83.3971
def round_fun1(x): # 二舍八入?
decimal_num = math.modf(x)[0]
if decimal_num <= 0.5:
return math.modf(x)[1]
if decimal_num > 0.5:
return math.modf(x)[1] + 1
print( "test_group_df.head()4")
print(test_group_df.loc[~test_group_df.广告id.isin(common_ad_id)].head())
# test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光']=test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光'].apply(lambda x: ((x - np.min(x))) / (np.max(x) - np.min(x)))
# test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光'] = common_train_df['平均每天曝光'].values/3.3
test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光']=(dat1 - dat1.min())/(dat1.max() - dat1.min())*1500
print( "test_group_df.head()45")
print( test_group_df.describe())
test_group_df.loc[(test_group_df.预测曝光 <1),'预测曝光'] = test_group_df.loc[(test_group_df.预测曝光 <1),'预测曝光'].apply(round_fun1)
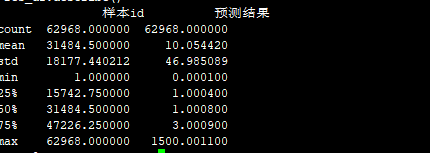
0和1 两个分数一样的合并:
submission_20_51.csv 83.3971
标准化后*1000
test_group_df.loc[( test_group_df.预测曝光 < 1000), '预测曝光'] =((dat2 - dat2.min())/(dat2.max() - dat2.min()))*1000
submission_smx_FM2019-06-09 21-07-32.csv 81.3429
80.8092
test_group_df.loc[test_group_df.广告id.isin(common_ad_id), '预测曝光']=(dat1 - dat1.min())/(dat1.max() - dat1.min())*1000
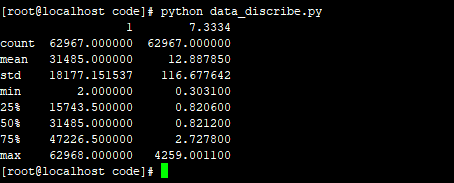
10.5 lgb 使用我的曝光和特征:83.3974
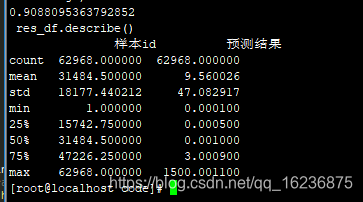
10.6 lgb 使用我新的的曝光和特征 /data1/data/chenli/for_25/total_data/track_log/train_total_expo1.csv:83.4139
FM:使用我新的的曝光和特征 /data1/data/chenli/for_25/total_data/track_log/train_total_expo1.csv: 新mon 83.3974
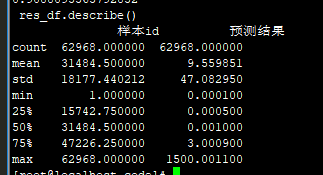
10.6 lgb 使用我新的的曝光和特征 /data1/data/chenli/for_25/total_data/track_log/train_total_expo1.csv,lgb用原来lgb中的规则: 80.3276,全部标准化:80.3276
lgb 加上A 测试集: 我新的曝光
lgb 加上A 测试集: 我旧的曝光
lgb 加上A 测试集: smx的曝光
11 lgb:加了用户特征 82.5219
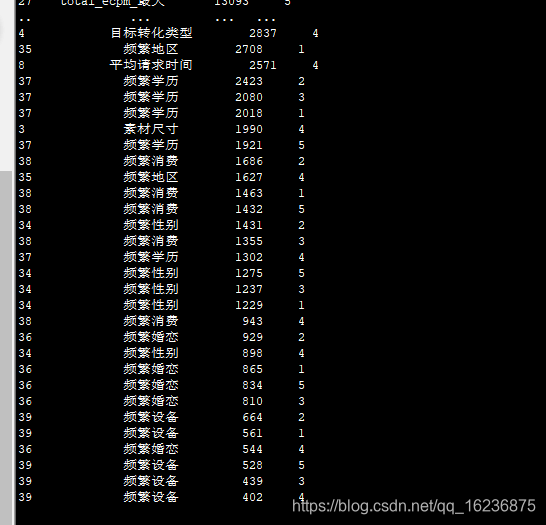

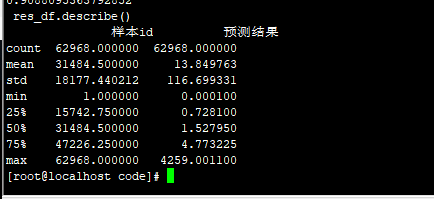
12 FM 去掉几个用户特征
83.1668
1 8.0001
count 62967.000000 62967.000000
mean 31485.000000 13.172069
std 18177.151537 116.677414
min 2.000000 1.000100
25% 15743.500000 1.000500
50% 31485.000000 1.000900
75% 47226.500000 3.000600
max 62968.000000 4259.001100
lgb:

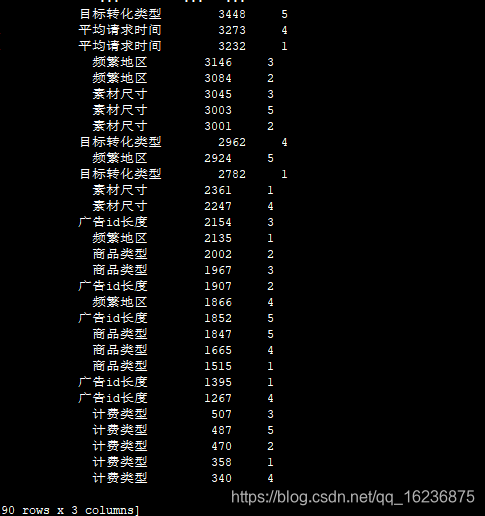
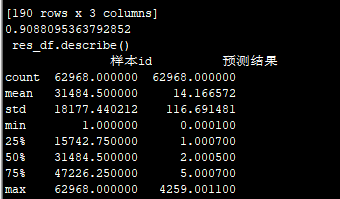
FM:去掉计费类型和商品类型:83.1668
1 8.0001
count 62967.000000 62967.000000
mean 31485.000000 13.172069
std 18177.151537 116.677414
min 2.000000 1.000100
25% 15743.500000 1.000500
50% 31485.000000 1.000900
75% 47226.500000 3.000600
max 62968.000000 4259.001100
FM 去掉:频繁地区和素材尺寸
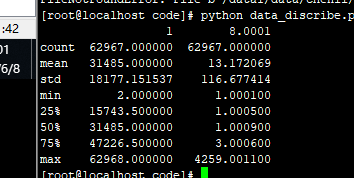
去掉目标转化类型和平均请求时间:81.1616
count 62967.000000 62967.000000
mean 31485.000000 13.627975
std 18177.151537 116.630909
min 2.000000 1.000100
25% 15743.500000 2.000200
50% 31485.000000 2.000700
75% 47226.500000 3.000600
max 62968.000000 4259.001100
lgb:/3.5 82.6117
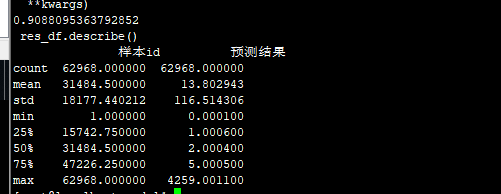
13 lgb+FM :原来的特征 83.1668
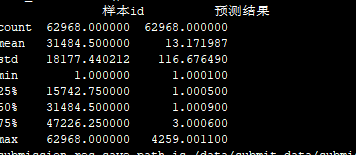
14 smx FFM
1 8.0001
count 62967.000000 62967.000000
mean 31485.000000 13.172069
std 18177.151537 116.677414
min 2.000000 1.000100
25% 15743.500000 1.000500
50% 31485.000000 1.000900
75% 47226.500000 3.000600
max 62968.000000 4259.001100
15 smx nffm:81.6535
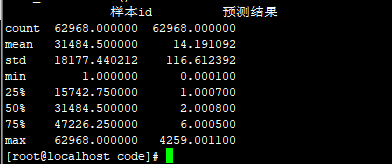
15 smx LGB_:R :72.0884

















 8588
8588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









