









 SVM作为机器学习中的经典算法,其优点在于训练模型复杂度取决于支持向量,不易过拟合。在面对线性不可分的数据时,通过非线性映射将数据映射到高维空间,使得分类变得可能。本文探讨了如何解决线性不可分问题以及如何进行多类问题的分类。后续内容将涉及具体实现和代码学习。
SVM作为机器学习中的经典算法,其优点在于训练模型复杂度取决于支持向量,不易过拟合。在面对线性不可分的数据时,通过非线性映射将数据映射到高维空间,使得分类变得可能。本文探讨了如何解决线性不可分问题以及如何进行多类问题的分类。后续内容将涉及具体实现和代码学习。
1 SVM的优点
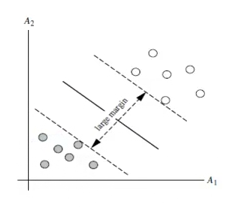
训练好的模型算法复杂度是由支持向量的个数决定,而不是数据维度决定,所以SVM不太容易过拟合。
SVM训练出来的模型完全依赖于支持向量,即使训练集里面所有非支持点都去除,重复训练过程,结果模型完全一样
一个SVM如果训练得到的支持向量个数少,则模型更容易泛化(比如各有1个点,剩下的所有可以随便扔)
2 针对线性不可分情况
数据集在空间中对应的向量不可以被一个超平面分开
2.1 如何解决?
- 利用一个非线性的映射,把原数据集中的向量点转化到更高维度的空间中
- 在这个高纬度空间找一个线性超平面来根据线性可分的情况处理
&n

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









