




冯诺依曼结构
高性能计算机一般都采用冯诺依曼结构。这是由于CPU的运算速度远远高于存储内存(FLASH)的读写速度,为了不浪费CPU的计算性能,在运行程序前,需要把程序从FLASH里全部读写到速度更快的运行内存(SRAM)里去,然后CPU才能运行程序。所以冯诺依曼结构的计算机都会有一个开机的环节,所谓开机就是把FLASH里的数据加载到运行内存中去的过程。
哈佛结构
大部分单片机采用哈佛结构。因为单片机的CPU运行速度一般没有那么快,CPU可以直接从flash里读出程序,然后直接执行。也就是没有开机环节,上电立即运行。
程序的运行过程
单片机把程序的运行一般分为3个环节:取指(Fetch),译码(Decode),执行(Execute)
对于c语言编写好的程序来说,经过编译器编译,会把程序里的指令和数据分开存放,形成一个hex或者bin文件,最终烧录到单片机FLASH里。比如我们要写一个计算1+2=?的程序。那+号和=号就是指令,而1和2就属于数据。
取址
开机后,程序里的数据会被搬运到SRAM里,而指令部分是从flash里直接读取,CPU从FLASH里取回需要执行的指令,即所谓的取指。但是需要注意的是程序里的数据部分是需要先从flash里搬运到SRAM里,才能供CPU读写的,这也是因为数据的读写频率较高,而flash存储器的性能无法满足高频的读写要求,不过code类型的数据不用搬运。
说到了取指,就不得不提一下地址(address),单片机里的所有内存空间和设备寄存器,都会被统一分配一个地址,方便CPU去访问,比如,ARM-cortex-m3内核的架构,这些地址是在架构设计之处就规定死的,单片机厂家只能按照这个规定去生产。其中,FLASH的地址空间被限定在0x0800 0000-0x0807 FFFF之间,比如有款ARM-cortex-m3内核的单片机,其存储内存是128k,那它的寻址空间就是0x0800 0000-0x0801 FFFF,我们编写好的用户程序,就会按照这个地址顺序,由低到高,一条条的存储在FLASH的存储空间里,取指时,也是按照这个地址顺序,由低到高,一条条的从FLASH里读取指令。
译码
指令被读取到CPU里以后,还不能直接被执行,因为在CPU内部有一个指令集寄存器,寄存器里规定了CPU可以执行的指令,也就是说CPU只能执行这个指令集里的指令,所以FLASH里取来的指令,再执行之前,需要经过一个译码电路,解释成CPU可以执行的指令,才能去执行,这个解码的过程,就是译码,译码过后,CPU就可以执行该指令了。
执行
单片机上电后,CPU会到按照地址由低到高的顺序,从FLASH里取来一条指令,执行,执行完毕后,接着会去取第二条指令,执行,如此下去,直到程序执行完毕,因此我这里称这种程序的执行方式为顺序执行。
以1+2=?这个程序为例,帮助大家理解计算机是如何执行程序完成计算的。编译器会把1+2=?编译成汇编语言,程序有4条指令构成,会被分别存放在0x0800 0000,0x0800 0004,0x0800 0008,0x0800 000C四个地址对应的flash空间里
MOV R1 ,1 //1把数据1 放入CPU的R1寄存器
MOV R2 ,2 //2把数据2 放入CPU的R2寄存器
ADD R1,R2 //3把R1,R2寄存器里的数据进行加法运算
STR 0X20000002,R1 //4把运算结果放入内存地址为 0X20000002单元里存放
CPU在执行这4个指令的时候,会按照存储地址由低到高的顺序执行,先执行第一条,再执行第二条,再执行第二条,最后执行第四条,顺序执行。
结合STM32看代码、变量存放
STM32F103C8T6单片机
- FLASH大小64KB,地址:0x8000000~0x8010000
- SRAM大小20KB,地址:0x20000000~0x20005000
编写一个简单的程序:

编译后:
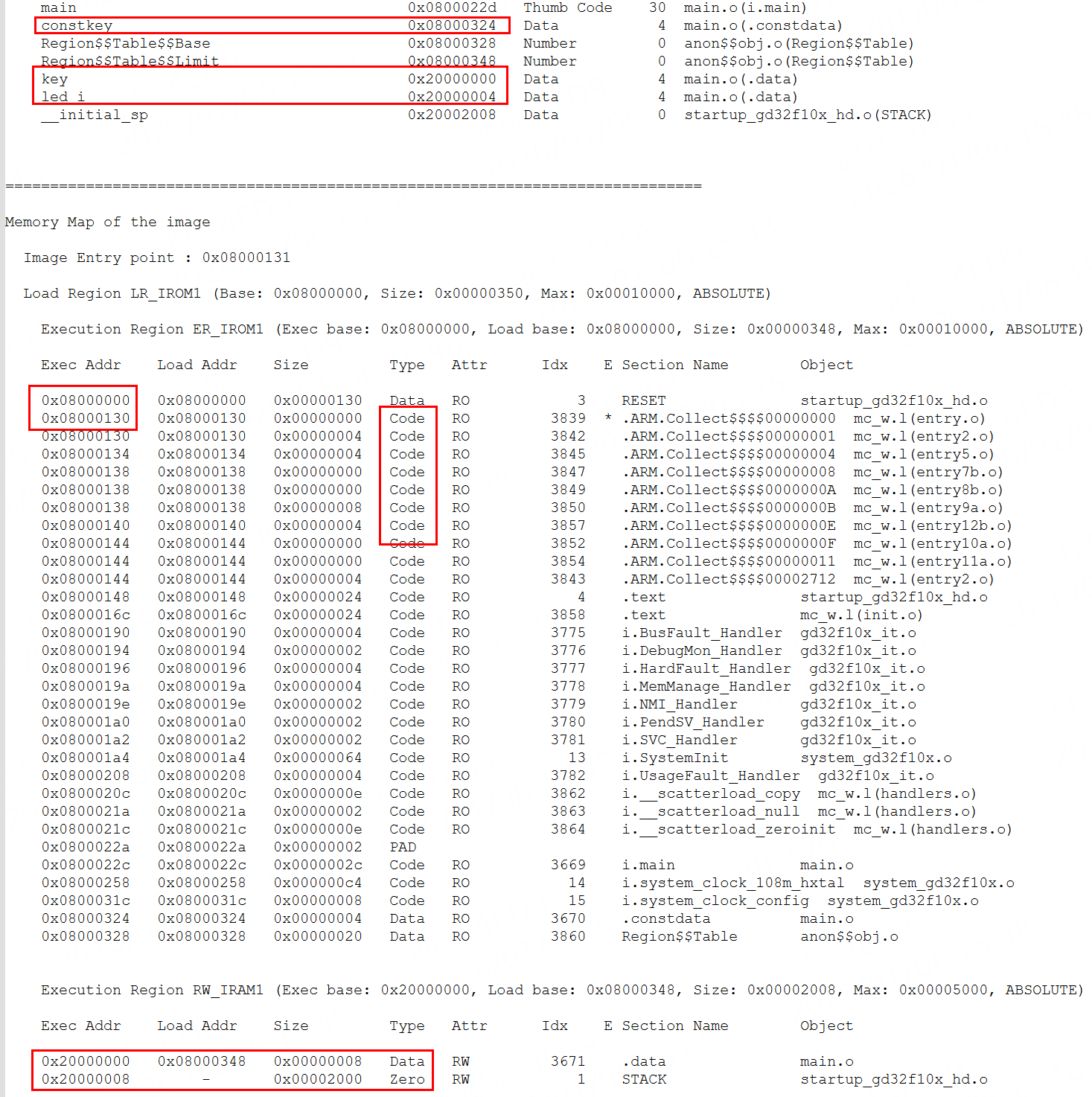
得到如下信息:
- 指令存放在0x8000000起始的FLASH地址中。
- const变量和指令一样,只存放在FLASH中。
- 全局变量会在SRAM中分配地址,key地址0x20000000、led_i地址0x20000004。
- 全局变量可能会有两个地址,Exec Addr和Load Addr,即执行地址和加载地址。程序启动时,会将加载地址中的数据复制到执行地址。0x20000000地址的8个字节是key、led_i,他们的初始值就保存在0x08000348。STM32在进入main函数前会把0x08000348地址的8个数据复制到0x20000000,这样变量就有了初始值。
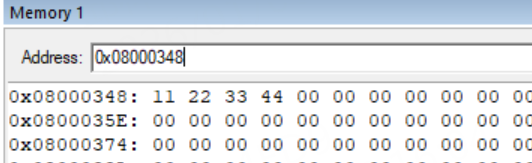
Exec Addr(执行地址)和Load Addr(加载地址)
Exec Addr(执行地址)
执行地址是程序运行时指令或数据在内存中的实际位置。程序在执行时,CPU会根据这个地址访问指令和数据。执行地址通常位于RAM中,因为RAM具有更快的读写速度,适合程序运行时的频繁访问。
例如,在STM32中,程序的全局变量和中间变量会被加载到SRAM中,执行地址就是这些变量在SRAM中的位置。
Load Addr(加载地址)
加载地址是程序在存储器(如Flash或ROM)中的存储位置。程序在上电或复位时,通常会从加载地址将数据复制到执行地址。加载地址通常位于Flash中,因为Flash适合存储程序代码和初始化数据。
例如,在STM32中,程序的代码和初始化数据会存储在Flash中,加载地址就是这些数据在Flash中的位置。
二者的联系
加载与运行的关系:加载地址是程序的初始存储位置,而执行地址是程序运行时的实际位置。程序启动时,通常需要将加载地址中的数据复制到执行地址。
映射关系:在映像文件中,加载地址和执行地址之间的映射关系由链接器脚本定义。例如,RW数据会从加载地址复制到执行地址,而ZI数据(未初始化变量)会在执行地址中初始化为0。
示例
以下是一个典型的内存映射:
Load Region LR_IROM1 (Base: 0x08000000, Size: 0x0000293c)
Execution Region ER_IROM1 (Exec base: 0x08000000, Load base: 0x08000000)
Execution Region RW_IRAM1 (Exec base: 0x20000000, Load base: 0x08002904)
代码段:加载地址和执行地址相同(如0x08000000),因为代码直接从Flash中执行。
RW数据段:加载地址在Flash中(如0x08002904),执行地址在SRAM中(如0x20000000)。
注意事项
地址对齐:加载地址和执行地址需要根据内存对齐要求进行调整,以避免访问错误。
内存覆盖:在设计加载和执行地址时,需要确保解压或复制操作不会导致内存覆盖。
STM32的Icode、Dcode
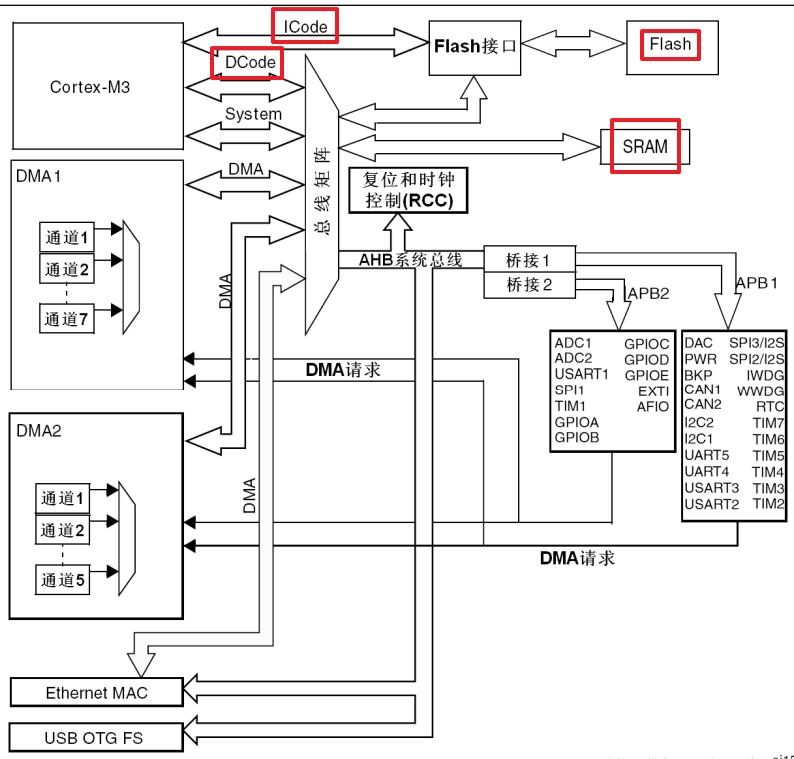
STM32芯片是属于哈佛架构。
哈佛架构的数据总线,指令总线是分开独立的,CPU通过Icode从Flash中取指令,再译码,得到数据的地址,再通过Dcode总线和SRAM进行数据交互。
将程序指令和数据存储在不同的存储空间中,每个存储器独立编址、独立访问。哈佛架构的微处理器通常具有较高的执行效率,其程序指令和数据指令分开组织和储存的,执行时可以预先读取下一条指令。
FLASH读指令速度瓶颈
数据放在SRAM,速度还是比较快的。但是指令放在Flash,速度就比较慢了。
常常听到一句话:“你的MCU跑得不够快,不是因为主频低,而是Flash拖了后腿“。即便你拥有Cortex-M7内核、480MHz主频、双BankFlash和ART加速器,只要Flash配置不当,整个系统依然可能“卡成PPT”
你把STM32H743超频到500MHZ,代码逻辑完美,外设驱动无误,结果一运行就HardFault。调试器显示PC指针跳到了未知地址,仿佛程序自己“走丢了”。最后查了一圈才发现,问题根源竟是那行被忽略的FLASH->ACR I= FLASH_ACR_LATENCY_6WS;没写对。Flash等待周期(Waitstates)到底是什么?它如何影响STM32的整体性能?
实际上,在微控制器内部,每一条指令的背后都是一场精密协作的“接力赛”:
1.PC递增→2.地址译码→3.字线激活→4.位线感应放大→5.ECC校验→6.送入预取缓冲→7.返回CPU
而这其中最慢的一环,往往就在第4步-浮栅晶体管中的电荷检测过程
为什么Flash读取天生“慢半拍”?
Flash是一种非易失性存储器,它的每个存储单元本质上是一个带有“浮栅的MOSFET。要判断这个单元是“0还是“1”,就需要向控制极施加电压,然后测量漏极电流是否达到阀值。这个过程涉及模拟电路的建立时间,远比SRAM那种直接连接电源的方式复杂得多。
STM32是怎么解决这个问题的?
ST为了解决高速CPU与慢速Flash之间的矛盾,设计了一整套多层次的优化体系
- 等待周期(Waitstates):最基础的时间补偿机制
- 预取缓冲(PrefetchBuffer):提前加载下一条指令
- ART Accelerator/l-Cache:缓存常用代码段,实现“零等待
- 双Bank结构(如H7系列):允许一边运行代码一边擦写另—Bank
- 动态电压调节(DVS):提升Flash供电电压以加快响应速度
这些技术层层叠加,最终目标只有一个:让CPU尽可能少地停下来等Flash。




















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











