



构建知识库是RAG(Retrieval-Augmented Generation)系统的核心环节,其质量直接影响检索和生成的效果。以下是构建知识库的完整流程,涵盖数据准备、处理、存储和优化步骤:
1. 知识库构建流程概览
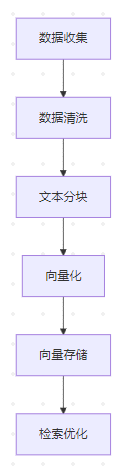
2. 详细步骤与实现方法
步骤1:数据收集
-
数据来源:
-
结构化数据:数据库表格、Excel/CSV(如产品手册、FAQ)。
-
非结构化数据:
-
网页(使用爬虫或
BeautifulSoup)。 -
PDF/Word/PPT(使用
PyPDF2、python-docx)。 -
企业内部文档(Confluence、Notion API)。
-
开源数据集(Wikipedia、ArXiv)。
-
-
实时数据:API接口、数据库日志。
-
-
示例代码(PDF文本提取):
from PyPDF2 import PdfReader def extract_text_from_pdf(file_path): reader = PdfReader(file_path) text = "".join([page.extract_text() for page in reader.pages]) return text
步骤2:数据清洗
-
关键操作:
-
去除无关内容(广告、页眉页脚)。
-
纠正编码错误(如
UTF-8转码)。 -
标准化格式(全角转半角、日期统一)。
-
去除重复文本(如
SimHash去重)。
-
-
示例代码(文本清洗):
import re def clean_text(text): text = re.sub(r"\s+", " ", text) # 合并多余空格 text = re.sub(r"<[^>]+>", "", text) # 去除HTML标签 return text.strip()
步骤3:文本分块(Chunking)
-
分块策略:
-
固定大小分块:每块512个token(适合通用场景)。
-
滑动窗口:重叠50-100个token(保持上下文连贯)。
-
语义分块:用句号/段落分割(适合技术文档)。
-
-
工具推荐:
-
LangChain:
RecursiveCharacterTextSplitter。 -
LlamaIndex:
SentenceSplitter。
-
-
示例代码(LangChain分块):
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, length_function=len ) chunks = text_splitter.split_text(text)
步骤4:向量化(Embedding)
-
模型选型:
模型名称 特点 适用场景 all-MiniLM-L6-v2轻量级(22MB),速度快 本地CPU环境 bge-large-en-v1.5高精度(支持多语言) 生产环境 text-embedding-3-largeOpenAI最新模型(1536维) 云API调用 -
示例代码(Hugging Face嵌入):
from sentence_transformers import SentenceTransformer model = SentenceTransformer("all-MiniLM-L6-v2") embeddings = model.encode(chunks, batch_size=32)
步骤5:向量存储
-
数据库选型对比:
数据库 优点 缺点 适用规模 FAISS 本地运行,速度快 无持久化,需手动保存 小型(<1M条) Milvus 分布式,支持增量更新 部署复杂 大型(>10M条) Pinecone 全托管,自动扩缩容 付费服务 云原生项目 -
示例代码(FAISS存储):
import faiss import numpy as np dimension = 384 # 向量维度 index = faiss.IndexFlatL2(dimension) index.add(np.array(embeddings).astype("float32")) faiss.write_index(index, "knowledge_base.index") # 保存索引
步骤6:元数据关联(可选但重要)
-
附加信息:
-
文档来源(URL、文件名)。
-
时间戳、作者、版本号。
-
业务标签(如产品分类、机密等级)。
-
-
实现方式:
chunks_with_metadata = [{ "text": chunk, "source": "manual.pdf", "page": i+1 } for i, chunk in enumerate(chunks)]
3. 知识库优化技巧
检索质量提升
-
混合检索:
-
结合关键词搜索(BM25)与向量检索。
from rank_bm25 import BM25Okapi corpus = [chunk["text"] for chunk in chunks_with_metadata] bm25 = BM25Okapi([doc.split() for doc in corpus]) keyword_scores = bm25.get_scores(query.split()) -
-
重排序(Rerank):
-
用交叉编码器(Cross-Encoder)对Top-K结果精排。
from sentence_transformers import CrossEncoder reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2") rerank_scores = reranker.predict([(query, chunk) for chunk in top_chunks]) -
性能优化
-
量化索引:使用FAISS的
IndexIVFPQ减少内存占用。 -
分层存储:热数据存内存,冷数据存磁盘。
4. 完整代码示例(LangChain集成)
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
# 1. 加载文档
loader = DirectoryLoader("./docs/", glob="**/*.pdf")
documents = loader.load()
# 2. 分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# 3. 向量化并存储
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = FAISS.from_documents(chunks, embeddings)
vector_db.save_local("my_knowledge_base") # 保存到本地
# 4. 检索示例
query = "如何设置VPN?"
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
relevant_docs = retriever.get_relevant_documents(query)
5. 常见问题解决
-
问题1:分块大小如何选择?
-
技术文档:300-800 token(保留完整代码示例)。
-
对话记录:100-300 token(保持单轮对话连贯)。
-
-
问题2:如何处理多模态数据?
-
图像/视频:先用CLIP提取特征向量,与文本向量联合存储。
-
-
问题3:知识库如何更新?
-
增量更新:Milvus支持动态插入/删除。
-
全量重建:定时重新生成FAISS索引(适合小规模数据)。
-
通过以上步骤,你可以构建一个高质量、可扩展的知识库。实际应用中建议:
-
从小规模开始验证(如1000条数据测试流程)。
-
监控检索命中率,持续优化分块和嵌入模型。
-
定期更新知识库,确保信息时效性。


















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











