




大家好,我是唐叔!今天咱们来聊聊Pandas这个数据分析利器在处理JSON数据时的妙用。JSON作为一种轻量级的数据交换格式,在Web开发和数据分析中无处不在。掌握Pandas与JSON的互转技巧,能让你在数据处理时事半功倍!
文章目录
一、Pandas读取JSON数据
1. 从本地文件读取JSON
首先,咱们看看如何从本地文件读取JSON数据。Pandas提供了read_json()函数,使用起来非常简单:
import pandas as pd
# 从本地文件读取JSON
df = pd.read_json('data.json') # 假设有一个data.json文件
print(df.head())

2. 从HTTP请求读取JSON数据
实际工作中,我们更多会遇到从API接口获取JSON数据的情况。这时候需要结合requests库来获取数据:
import pandas as pd
import requests
# 发送HTTP GET请求获取JSON数据
response = requests.get('https://api.example.com/data')
data = response.json() # 将响应转换为Python字典
# 将字典转换为DataFrame
df = pd.DataFrame(data)
print(df.head())
如果JSON数据结构比较复杂,比如嵌套了多层,可以使用json_normalize()函数来展平:
from pandas import json_normalize
# 假设获取的JSON数据有嵌套结构
complex_data = {
"total": 2,
"users": [
{
"name": "张三",
"age": 25,
"address": {
"city": "北京",
"street": "朝阳区"
}
},
{
"name": "李四",
"age": 30,
"address": {
"city": "上海",
"street": "浦东新区"
}
}
]
}
# 展平嵌套的JSON结构
df = json_normalize(complex_data, 'users', meta=['total'])
print(df)

二、将Pandas数据转换为JSON
1. 基本转换方法
把DataFrame转换为JSON同样简单,使用to_json()方法即可:
# 创建一个示例DataFrame
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 35],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
# 转换为JSON字符串
json_str = df.to_json()
print(json_str)
# 转换为JSON文件
df.to_json('output.json', orient='records', force_ascii=False)

2. 不同格式的JSON输出
Pandas提供了多种JSON输出格式,通过orient参数控制:
# 按记录输出(最常用的格式)
print(df.to_json(orient='records'))
# 按索引输出
print(df.to_json(orient='index'))
# 按列输出
print(df.to_json(orient='columns'))
# 按值输出
print(df.to_json(orient='values'))
3. 处理中文编码问题
默认情况下,中文会被转换为Unicode编码。如果想保留原始中文,可以设置force_ascii=False:
print(df.to_json(orient='records', force_ascii=False))
PS:验证了使用PyCharm的控制台打印没效果,但是输出文件是可以做到保留原始中文的。
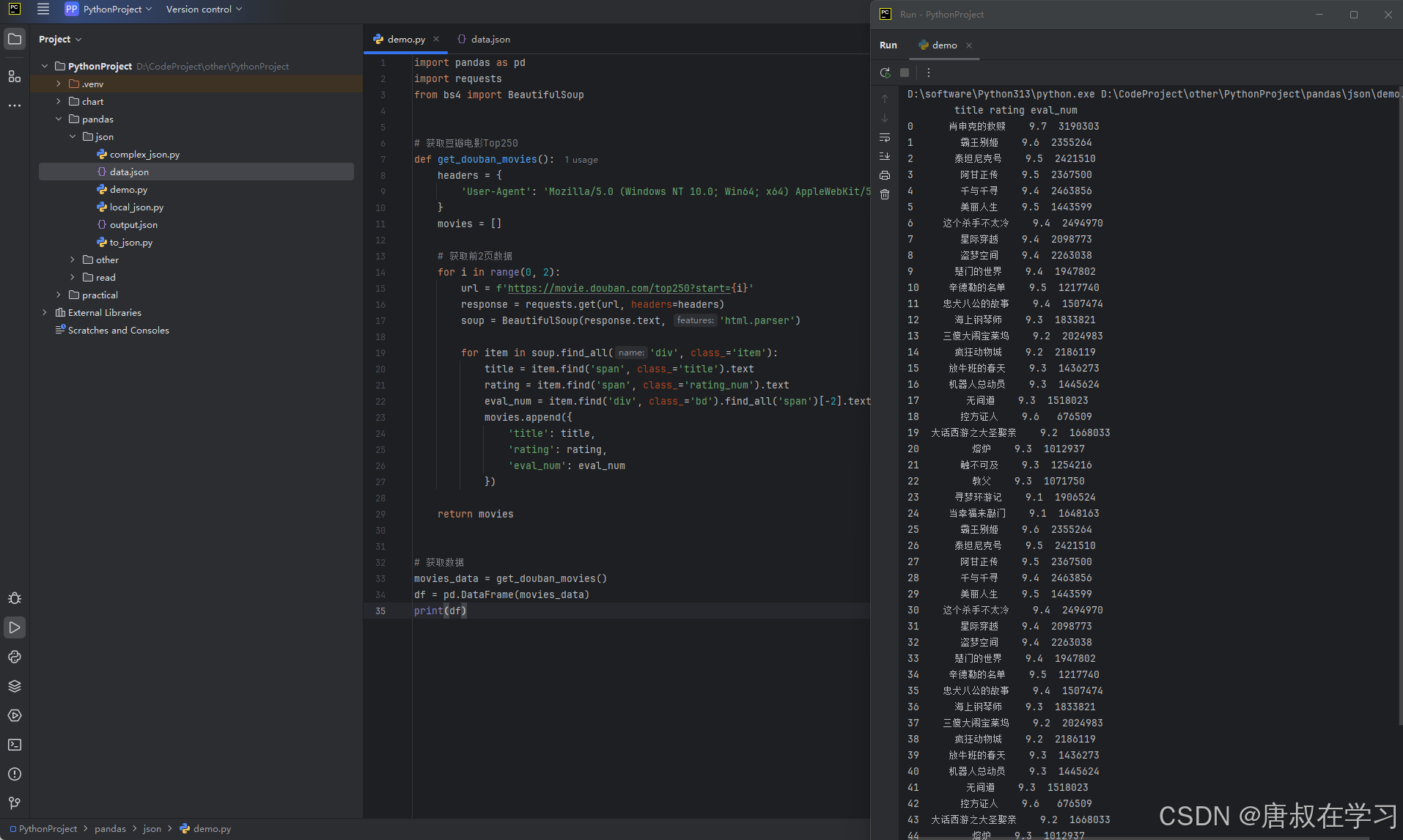
三、实战案例:获取豆瓣电影Top50
豆瓣提供了公开的API接口(需要申请API key),但为了演示,我们先使用简单的网页版接口:
import pandas as pd
import requests
from bs4 import BeautifulSoup
# 获取豆瓣电影Top50
def get_douban_movies():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
movies = []
# 获取前2页数据
for i in range(0, 2):
url = f'https://movie.douban.com/top250?start={i}'
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.find_all('div', class_='item'):
title = item.find('span', class_='title').text
rating = item.find('span', class_='rating_num').text
eval_num = item.find('div', class_='bd').find_all('span')[-2].text.replace('人评价', '')
movies.append({
'title': title,
'rating': rating,
'eval_num': eval_num
})
return movies
# 获取数据
movies_data = get_douban_movies()
df = pd.DataFrame(movies_data)
print(df)
四、常见问题解答
Q1:为什么我的JSON数据读取后格式不对?
A:JSON数据结构千变万化,建议先用print(data)查看原始结构,再决定如何转换。复杂的嵌套结构可能需要json_normalize来处理。
Q2:如何只转换DataFrame的某几列为JSON?
A:可以先选择需要的列,再转换:
df[['姓名', '年龄']].to_json()
Q3:处理大型JSON文件时内存不足怎么办?
A:可以尝试:
- 使用
chunksize参数分块读取 - 使用
ijson库流式处理大型JSON文件
五、总结
今天唐叔带大家学习了:
- 使用
read_json()读取本地JSON文件 - 结合requests获取HTTP接口的JSON数据
- 使用
json_normalize处理复杂嵌套结构 - 使用
to_json()将DataFrame转换为JSON - 处理中文编码问题
- 一个完整的天气数据分析案例
记住,数据处理的关键在于理解数据结构。拿到JSON数据后,先打印出来看看结构,再决定如何处理。
好了,今天的分享就到这里。如果你觉得有用,别忘了点赞、收藏、关注三连!有什么问题欢迎在评论区留言,唐叔会一一解答。
唐叔小贴士:JSON数据格式虽然灵活,但缺乏严格的结构定义。在实际项目中,建议使用JSON Schema来定义数据格式,这样可以减少很多数据处理时的麻烦。
往期Python文章推荐



















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











