



一、RAG核心概念
1. 定义
RAG(Retrieval-Augmented Generation)是一种通过实时检索外部知识库增强大语言模型(LLM)生成能力的技术,解决LLM的三大痛点:
-
知识冻结:传统LLM无法动态更新知识
-
幻觉问题:生成内容缺乏事实依据
-
领域局限:通用模型在垂直领域表现不足
2. 核心组件
| 组件 | 作用 |
|---|---|
| 检索器(Retriever) | 从知识库中查找相关文档(如BM25/向量检索) |
| 知识库(Knowledge Base) | 结构化/非结构化数据存储(PDF、数据库等) |
| 生成器(Generator) | 基于检索结果的LLM(如GPT、ChatGLM) |
二、技术原理
1. 工作流程

2. 关键技术
-
稠密检索(Dense Retrieval):使用嵌入模型(如text2vec)将文本映射为向量空间
-
最大边际相关性(MMR):平衡检索结果的相关性与多样性
-
上下文窗口压缩:通过摘要或选择性注意力机制处理长文档
三、实现流程与代码示例
步骤1:知识库构建
# 使用pdfplumber解析中文PDF
import pdfplumber
from langchain.text_splitter import ChineseTextSplitter
def load_pdf(file_path):
with pdfplumber.open(file_path) as pdf:
pages = [p.extract_text() for p in pdf.pages]
return ChineseTextSplitter().split_text("\n".join(pages))
chunks = load_pdf("医疗知识库.pdf") # 获得分块后的文本列表
步骤2:向量化与索引
# 使用text2vec构建本地向量库
from text2vec import SentenceModel
import faiss
import numpy as np
model = SentenceModel("shibing624/text2vec-base-chinese")
vectors = [model.encode(chunk) for chunk in chunks]
# 创建FAISS索引
dimension = vectors[0].shape[0]
index = faiss.IndexFlatIP(dimension) # 内积相似度
index.add(np.array(vectors).astype('float32'))
faiss.write_index(index, "medical_index.faiss")
步骤3:检索增强生成
# 集成ChatGLM3-6B本地模型
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).half().cuda()
def rag_query(query, top_k=3):
# 1. 检索
query_vec = model.encode(query)
distances, indices = index.search(np.array([query_vec]).astype('float32'), top_k)
context = "\n".join([chunks[i] for i in indices[0]])
# 2. 生成
prompt = f"基于以下医学资料回答,若不知道则说未知:\n{context}\n\n问题:{query}"
response, _ = model.chat(tokenizer, prompt)
return response
# 示例:医疗咨询
print(rag_query("糖尿病患者应该如何控制饮食?"))
四、部署方案
1. 轻量级部署
# 使用FastAPI暴露服务
pip install fastapi uvicorn
# api_server.py
from fastapi import FastAPI
app = FastAPI()
@app.post("/ask")
async def ask(question: str):
return {"answer": rag_query(question)}
启动服务:
uvicorn api_server:app --host 0.0.0.0 --port 8000
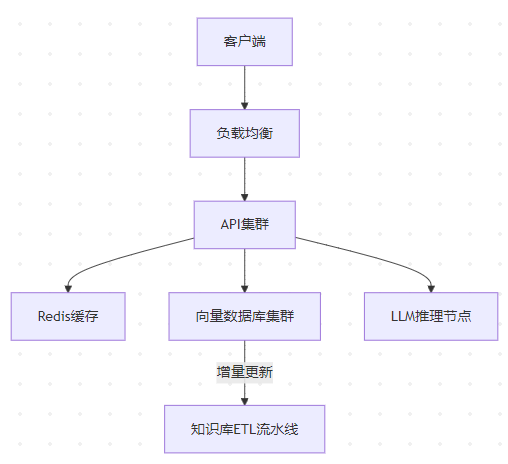
2. 企业级架构
五、应用场景示例
| 领域 | 应用案例 | 技术要点 |
|---|---|---|
| 医疗咨询 | 基于最新指南回答患者问题 | 医学文献PDF解析+术语增强检索 |
| 法律助手 | 根据法条生成合同条款 | 法律条文结构化索引+精确引用 |
| 教育辅导 | 解析教材解答习题 | 多模态检索(文本+公式图片) |
| 电商客服 | 实时查询商品政策回答用户 | 商品数据库SQL转自然语言 |
六、关键问题与解决方案
1. 检索精度不足
-
解决方法:
# 混合检索策略(关键词+向量) from rank_bm25 import BM25Okapi bm25 = BM25Okapi([jieba.lcut(chunk) for chunk in chunks]) keyword_scores = bm25.get_scores(jieba.lcut(query)) combined_scores = 0.5*vector_scores + 0.5*keyword_scores
2. 上下文过长
-
解决方法:动态摘要
from langchain.chains.summarize import load_summarize_chain chain = load_summarize_chain(llm, chain_type="map_reduce") summarized = chain.run(context_docs)
3. 知识更新延迟
-
解决方法:建立增量索引管道
# 使用Watchdog监控文件变化 from watchdog.observers import Observer class FileHandler(FileSystemEventHandler): def on_modified(self, event): update_vector_index(event.src_path)
七、扩展方向
-
多模态RAG:
-
使用CLIP处理图像检索
-
视频语音转文本后建立索引
-
-
自优化系统:
-
通过用户反馈数据微调检索器
-
-
边缘部署:
-
使用TensorRT加速本地LLM推理
-
八、性能评估指标
| 指标 | 计算方法 | 达标参考值 |
|---|---|---|
| 检索召回率@K | 前K个结果中包含正确答案的比例 | @3 > 0.85 |
| 生成事实准确性 | 人工评估答案与参考文档的一致性 | >90%匹配 |
| 端到端延迟 | 从查询到生成的总耗时 | <1.5s(本地LLM) |
通过上述完整框架,开发者可构建适应不同场景的RAG系统,平衡效果、成本与实时性需求。



















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











