



如果你已经探索过使用 Neo4j 来实现 GraphRAG,你可能已经了解它在提升生成模型输出质量方面的潜力。传统上,这需要深入掌握 Neo4j 和 Cypher(Neo4j 的查询语言)。在本文中,您可以了解到一种更简单的方式,简化 Neo4j 与检索增强生成(RAG)应用的集成,使开发者更容易使用,那就是:适用于 Python 的官方 Neo4j GraphRAG 包(neo4j-graphrag)!
neo4j-graphrag:https://pypi.org/project/neo4j-graphrag/
该 Python 包为您提供了管理 RAG 过程中的检索与生成任务的高效工具。本文将展示如何使用该包执行检索任务。接下来的文章将介绍其生成功能,帮助您构建完整的端到端 RAG 流程。
什么是 GraphRAG?
neo4j-graphrag 包简化了图检索增强生成(GraphRAG)。在 Neo4j,我们相信将图数据库与向量搜索结合起来代表了 RAG 的下一步发展方向。
安装设置
首先,连接到一个预配置的 Neo4j 演示数据库,该数据库模拟了一个电影推荐知识图谱。您可以使用用户名和密码 “recommendations” 访问 https://demo.neo4jlabs.com:7473/browser/。这一设置提供了一个现实场景,向量嵌入数据已作为 Neo4j 数据库的一部分。
使用 Cypher 命令可视化数据:
MATCH (n) RETURN n LIMIT 25;

观察每个节点右侧详情中的 plotEmbedding 属性。我们将在演示中使用这些嵌入执行向量搜索。您可以通过以下 Cypher 命令检查是否存在 moviePlotsEmbedding 向量索引:
SHOW INDEXES YIELD * WHERE type='VECTOR';
在您的 Python 环境中,安装 neo4j-graphrag 包及其他依赖包:
pip install neo4j-graphrag neo4j openai
接着,使用 Neo4j Python 驱动程序连接到数据库:

确保您已设置 OpenAI API 密钥:
import os
os.environ["OPENAI_API_KEY"] = "sk-..."
检索操作
我们的包提供了适用于不同检索策略的多种检索器类(参见文档:https://neo4j.com/docs/neo4j-graphrag-python/current/)。在这里,我们使用 VectorRetriever 类:
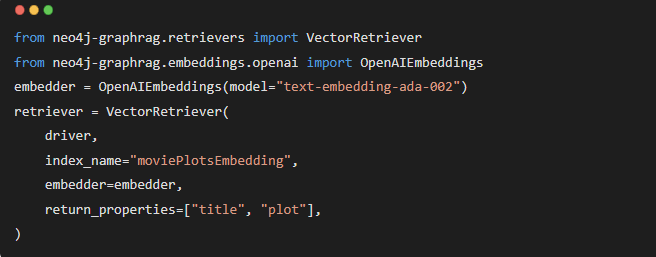
我们使用 text-embedding-ada-002 模型,因为演示数据库中的电影情节嵌入是使用该模型生成的,从而使检索结果更加相关。您可以自定义返回的结果属性,这里我们指定了返回节点属性 title 和 plot。
使用检索器搜索与查询最相关的电影情节,执行近似最近邻搜索以识别最佳匹配的前三个电影情节:

结果可以进一步解析为:

GraphRAG
让我们看看检索器如何集成到简单的 GraphRAG 流程中。要使用 neo4j-graphrag 包执行 GraphRAG 查询,需要以下几个组件:
- 一个 Neo4j 驱动——用于查询 Neo4j 数据库。
- 一个检索器——neo4j-graphrag 包提供了一些实现,并允许您编写自己的检索器。
- 一个 LLM——我们需要调用一个 LLM 来生成答案。neo4j-graphrag 包目前仅提供 OpenAI 的 LLM 实现,但其接口与 LangChain 的聊天模型兼容,并允许您编写自己的接口。
实际操作只需几行代码:

总结
我们展示了如何使用 neo4j-graphrag 包中的 VectorRetriever 类执行简单的检索查询。未来的文章将探讨其他检索策略以及如何在 GraphRAG 流程中使用不同的 LLM。敬请期待!
欢迎您将 neo4j-graphrag 包集成到您的项目中,并在公众号文章下方分享您的见解。
该包代码是开源的,您可以在 GitHub(https://github.com/neo4j/neo4j-graphrag-python) 上找到它,欢迎在上面提交问题。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









