



一、RAG 系统核心原理与技术选型
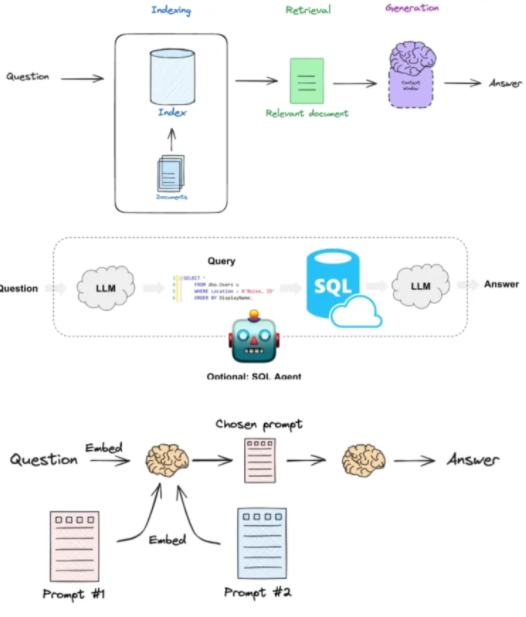
1.1 RAG 技术架构解析
RAG(检索增强生成)系统通过向量检索+LLM 生成的双轮驱动架构,解决传统 LLM 的三大痛点:
- 知识滞后:实时接入最新数据
- 内容幻觉:基于检索结果生成保证事实性
- 私有数据缺失:支持企业知识库集成
核心流程包括:
- 数据摄取:加载 PDF/Word/ 网页等格式文件
- 文本分块:将长文本拆分为 500-1000 字的语义片段
- 向量索引:通过 Embedding 模型生成向量存储到数据库
- 检索增强:根据用户问题检索相关文档片段
- 生成优化:将检索结果与问题结合生成最终回答
1.2 技术栈选型建议
| 组件 | 推荐方案 | 替代方案 |
|---|---|---|
| 文本加载 | PyPDF2/Unstructured | BeautifulSoup(网页) |
| 分块工具 | RecursiveCharacterTextSplitter | CharacterTextSplitter |
| Embedding | BAAI/BGE-large-zh-v1.5 | text-embedding-ada-002 |
| 向量数据库 | FAISS(本地)/Pinecone(云端) | Chroma/Qdrant |
| LLM | Qwen-1.8/InternLM-3.0 | GPT-4-Turbo |
| 部署框架 | FastAPI+Uvicorn | Flask+Gunicorn |
二、数据准备与预处理
2.1 数据采集与清洗
2.1.1 多源数据加载
python
from langchain.document_loaders import PyPDFLoader, TextLoader, WebBaseLoader
# 加载PDF文件
loader = PyPDFLoader("data/report.pdf")
documents = loader.load()
# 加载本地文本文件
loader = TextLoader("data/faq.txt")
documents += loader.load()
# 加载网页内容
loader = WebBaseLoader("https://example.com")
documents += loader.load()
2.1.2 文本清洗
python
import re
def clean_text(text):
# 去除特殊字符
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', text)
# 合并连续空格
text = re.sub(r'\s+', ' ', text).strip()
# 去除过长空白行
text = '\n'.join([line for line in text.split('\n') if len(line) > 10])
return text
# 批量清洗文档
cleaned_docs = [Document(page_content=clean_text(doc.page_content), metadata=doc.metadata) for doc in documents]
2.2 文本分块策略
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_documents(cleaned_docs)
2.3 向量数据库初始化
python
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vector_db = FAISS.from_documents(chunks, embeddings)
# 保存索引
vector_db.save_local("faiss_index")
三、RAG 系统核心组件构建
3.1 检索器配置
python
# 从本地加载索引
vector_db = FAISS.load_local("faiss_index", embeddings)
# 配置检索参数
retriever = vector_db.as_retriever(
search_type="similarity",
search_kwargs={"k": 5, "score_threshold": 0.7}
)
3.2 LLM 选择与优化
3.2.1 本地模型部署
python
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
llm = LlamaCpp(
model_path="models/qwen-1.8-chat-int4.bin",
n_ctx=4096,
temperature=0.6,
top_p=0.95
)
3.2.2 云端模型调用
python
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
model_name="gpt-4-1106-preview",
temperature=0.2,
max_tokens=1000
)
3.3 RAG 链构建
python
from langchain.chains import RetrievalQA
prompt_template = """
已知信息:
{context}
用户问题:
{question}
请基于已知信息,以专业技术文档的格式回答用户问题,要求逻辑清晰、步骤明确。
"""
chain_type_kwargs = {
"prompt": PromptTemplate.from_template(prompt_template),
"verbose": True
}
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs
)
四、系统评估与优化
4.1 核心评估指标
| 指标 | 计算方法 | 优化方向 |
|---|---|---|
| 上下文召回率 | 检索到的关键信息数 / 总关键信息数 | 调整分块策略、优化 Embedding |
| 答案忠实度 | 基于检索内容的事实数 / 答案总事实数 | 强化 prompt 约束、增加检索结果权重 |
| 响应相关性 | 人工标注相关性评分 | 优化检索排序、调整 prompt 模板 |
4.2 性能优化技巧
4.2.1 检索优化
python
# 混合检索(向量+关键词)
from langchain.retrievers import EnsembleRetriever
vector_retriever = vector_db.as_retriever()
bm25_retriever = BM25Retriever.from_documents(chunks)
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3]
)
4.2.2 生成优化
python
# 流式输出
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = ChatOpenAI(
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
temperature=0.1
)
五、系统部署与监控
5.1 API 服务搭建
python
# main.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
class QueryRequest(BaseModel):
query: str
top_k: int = 5
@app.post("/query")
async def handle_query(request: QueryRequest):
try:
result = qa_chain({"query": request.query, "top_k": request.top_k})
return {"answer": result["result"]}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
5.2 容器化部署
dockerfile
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
5.3 监控与日志
python
# 集成Prometheus
from prometheus_fastapi_instrumentator import Instrumentator
Instrumentator().instrument(app).expose(app)
# 日志配置
import logging
logging.basicConfig(
filename="app.log",
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)
六、进阶优化与扩展
6.1 多模态支持
python
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, Tool
tools = [
Tool(
name="ImageSearch",
func=lambda query: image_search_api(query),
description="用于搜索与查询相关的图片"
)
]
agent = initialize_agent(
tools,
OpenAI(temperature=0),
agent="zero-shot-react-description",
verbose=True
)
6.2 长期记忆增强
python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
memory=memory
)
6.3 安全与隐私保护
python
# 数据加密存储
from cryptography.fernet import Fernet
key = Fernet.generate_key()
cipher_suite = Fernet(key)
encrypted_docs = [Document(page_content=cipher_suite.encrypt(doc.page_content.encode()), metadata=doc.metadata) for doc in documents]
# 访问控制
from fastapi.security import OAuth2PasswordBearer
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.post("/query")
async def handle_query(request: QueryRequest, token: str = Depends(oauth2_scheme)):
# 验证token
pass
七、总结与资源推荐
7.1 关键步骤回顾
- 数据处理:清洗→分块→向量化
- 核心组件:检索器 + LLM+RAG 链
- 部署优化:API 服务→容器化→监控
- 扩展方向:多模态→记忆增强→安全加固
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 5436
5436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









