



目录
-
背景
-
Rag核心原理介绍
-
Rag环境搭建(含大模型DeepSeek部署)
-
Rag系统代码实现
-
总结
背景
当下数字化浪潮席卷全球,数据呈爆炸式增长,计算能力指数级提升,算法持续创新突破,三者共同构筑起人工智能发展的坚实底座。高性能芯片赋予机器强大算力,深度学习等算法让模型能挖掘数据深层价值,推动人工智能从理论迈向广泛应用。但从技术角度看,人工智能最容易落地的场景如下:
-
RAG知识库(Retrieval-Augmented Generation)
RAG通过“检索+生成”结合的”外挂“,将外部知识库与大语言模型(LLM)深度融合。其核心逻辑是用户提问时,系统先从知识库中检索相关内容,检索出内容进行算法排序,再结合这些检索结果利用大模型LLM总结、归纳和润色等生成人类可理解的自然语来回答,减少了传统模型“幻觉”与知识时效性问题。 -
AI Agent(智能体)
AI Agent是具备环境感知、自主决策与执行能力的智能实体,能够通过工具调用、多轮对话等实现复杂任务闭环,如智能机器人。其本质是“大模型+工具+记忆”的协同系统。 -
生成式BI(Generative Business Intelligence)
生成式BI通过自然语言交互,理解业务需求,转为SQL或处理程序提取、加工数据,并将数据转化为可视化报告与决策建议,降低数据使用门槛。其核心价值在于“平民化数据分析”,让非技术人员也能通过对话获取洞见,同时也可为业务查找数据、认识数据提供很大帮助,但这数据准确度上需要做出很多数据语料、提示工程、微调等工作。
-
数字人技术
通过3D建模、语音合成与动作捕捉,打造高度拟人化的虚拟形象,实现多模态交互,即通过文字识、图像识别或语音识别转换为自然语言,传递给大模型LLM,大模型生成的文字转化语音、手势动作等进行交互,如直播带货,节目播音、教育陪练(英语口语练习)
-
汽车智能座舱
通过大模型与多模态交互(语音、文本、图像多种形态交互),重构人车关系。情感化交互、多轮对话、车内外感知、智能驾驶等
-
协同办公自动化
通过AI赋能会议、文档与项目管理,提升协作效率。文档生成、流程自动化、代码编写、内容生成、音频、视频、图片生成等等
以上等等应用在各个行业各个领域创新应用遍地开花,层出不穷,可谓百花齐放,但笔者这里先从Rag系统介绍开始。
RAG知识库介绍
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将传统信息检索统与大语言模型相结合的技术架构。它先从大量的外部知识中将有用的信息提取出来,再将这些信息输入大语言模型整理成清晰自然的回答,用户提问时,系统先从知识库中检索相关内容,检索出内容进行算法排序,再结合这些检索结果利用大模型LLM总结、归纳和润色等生成人类可理解的自然语来回答,其核心逻辑和技术实现如下:
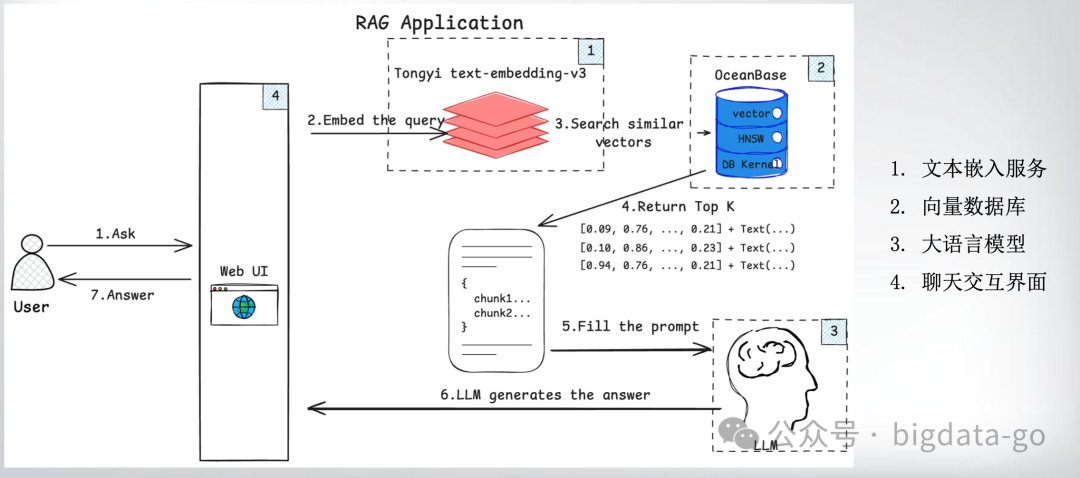
Rag系统核心原理简单可以理解三部分:
-
数据准备:支持多格式文档(PDF、Word、网页等)的解析与分段处理,使用BERT、Sentence-BERT等生成嵌入模型将文档转换为向量,确保语义完整性,存储于向量数据库(如Milvus、Pinecone、chroma,目前国产数据库也有向量数据库)
-
数据检索:为了快速的在向量数据库中找到与问题相关的文本块,用户输入的问题也需要经过生成嵌入模型(这里必须使用与文本块转换相同的生成嵌入模型)转化为嵌入向量,在检索时,从而可与向量库中的向量相互匹配(计算余弦相似度),返回Top-K相关文档。
-
LLM生成环节:生成模块基于检索内容生成答案,并通过重排序(Rerank)机制优化结果相关性。将检索结果与用户问题拼接为增强提示词(Prompt),输入LLM生成最终答案。
目前Rag系统在多个领域中得到了广泛应用,并且取得了显著的效果提升,但其有优缺点:
-
**优点:****可动态接入最新数据,避免模型知识过期;**可解释性答案附带引用来源,提升可信度;成本效益,减少对模型参数量的依赖,降低训练与推理成本。
-
缺点:需优化向量模型与检索算法,避免“答非所问”;需定期更新数据源,处理格式多样性与冗余信息;延迟问题,检索环节增加响应时间,需通过缓存、异步处理优化。
LLM环境搭建
普通PC也可搭建基于Langchain开发框架+Ollama部署模型工具+Chroma向量数据库+DeepSeek R1构建的Rag系统,环境搭建可分为五个步骤:
1 Pycharm开发环境准备
Pycharm安装后,需要配置conda环境,File->settings->项目下Python Interpreter配置add interpreter
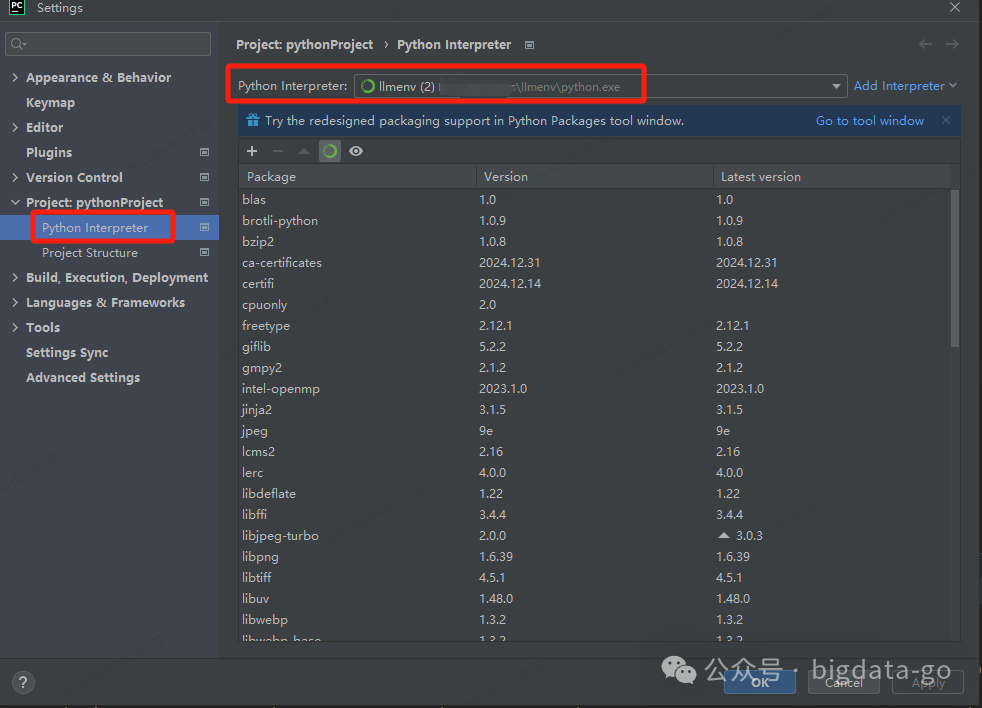
配置conda Enviroment,配置conda Executable 并选择Use existing environment的conda的虚拟环境
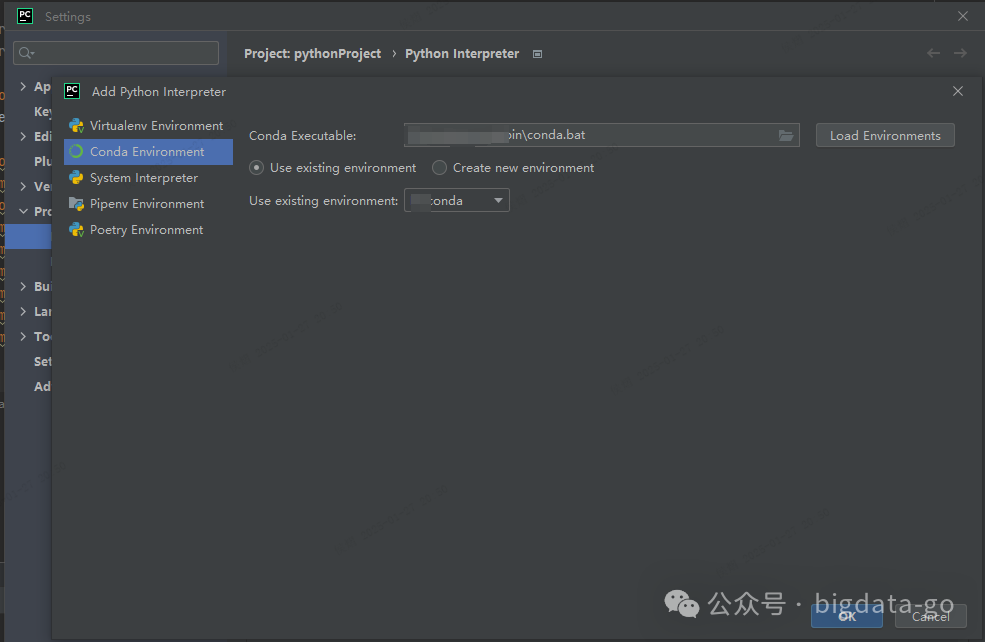
2 Conda虚拟环境搭建
Conda是一个开源的软件包管理系统和环境管理系统,它被设计用于在多版本环境中管理软件包及其依赖关系。Conda主要用于Python环境,但也支持其他语言和平台。Conda可以在Linux、OS X和Windows等操作系统上运行。
使用Conda的几大好处:
-
版本控制:Conda允许用户在同一台机器上安装和管理多个Python版本,以及特定版本的软件包和依赖关系。这对于开发和测试特别有用,因为你可以轻松地在不同的环境中切换。
-
包管理:Conda提供了一个丰富的软件包库,用户可以轻松地安装、更新和卸载各种Python包。
-
环境管理:Conda允许用户创建独立的环境,每个环境可以有自己的依赖关系和Python版本。这有助于隔离项目,防止不同项目之间的冲突。
下面是一些常见的Conda命令:
conda list:列出当前conda环境中已安装的软件包。``conda create:创建一个新的conda环境。例如,``conda create -n llmenv python=3.11``将创建一个名为llmenv 的新环境,并安装Python 3.11版本。``conda activate:激活一个已存在的conda环境。例如,``conda activate llmenv``将激活名llmenv的环境。``conda deactivate:停用一个已存在的conda环境。``conda install:在当前的conda环境中安装一个或多个软件包。例如,``conda install numpy``将安装numpy包。``conda update:更新当前conda环境中的软件包到最新版本。例如,``conda update numpy``将更新numpy包到最新版本。``conda remove:从当前的conda环境中移除一个软件包。例如,``conda remove numpy``将移除numpy包。``conda search:搜索可用的软件包。例如,``conda search numpy``将列出所有可用的numpy包版本。
笔者搭建conda环境使用的命令
`1 创建conda环境``conda create -n llmenv python=3.11``2 激活环境` `conda activate llmenv``3 关闭环境``conda deactivate`
3 在上述安装的Conda环境上安装Langchain、Chroma、Pytorch等包
其他还有各种包准备:chromadb、bs4、langchain_community、langchain_chroma、langchain_ollama、langchain_text_splitters
`pip install langchain #安装过程中可能会报错,包依赖的问题直接安装相应的包后,继续安装即可``pip install chromadb``pip install pytorch::python torchvision torchaudio -c pytorch``...``以上需要什可以使用pip install命令进行安装`
4 启动向量数据库chromadb
在conda PowerShell Prompt窗口运行,启动chromadb向量数据库
chroma run
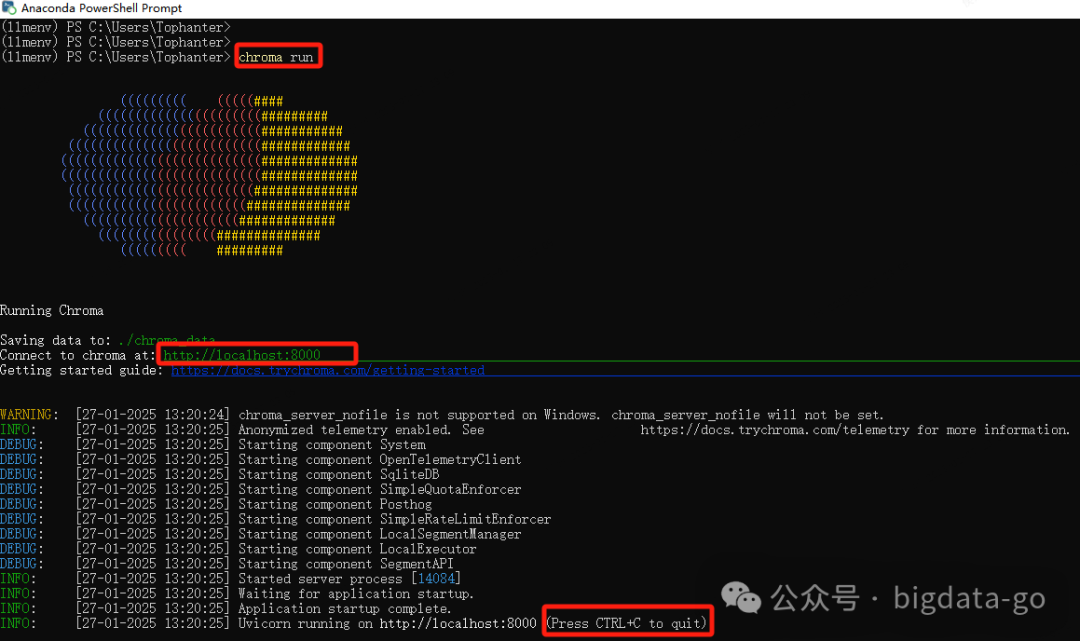
http://localhost:8000
远程可以连接地址和端口,python代码中可创建创建远程客户端Client
5 安装Ollama
Ollama是一个专为在本地环境中运行和定制大型语言模型而设计的工具。它提供了一个简单而高效的接口,用于创建、运行和管理这些模型,同时还提供了一个丰富的预构建模型库,可以轻松集成到各种应用程序中。Ollama的目标是使大型语言模型的部署和交互变得简单,无论是对于开发者还是对于终端用户,在官方网页:https://ollama.com/download/windows上,注册下载安装即可。
ollama可以搜索可下载的全球预训练模型如DeepSeek、阿里通义等
`https://ollama.com/search``#ollama run qwen2.5`
笔者下载的是deepSeek R1模型:
ollama run deepseek-r1
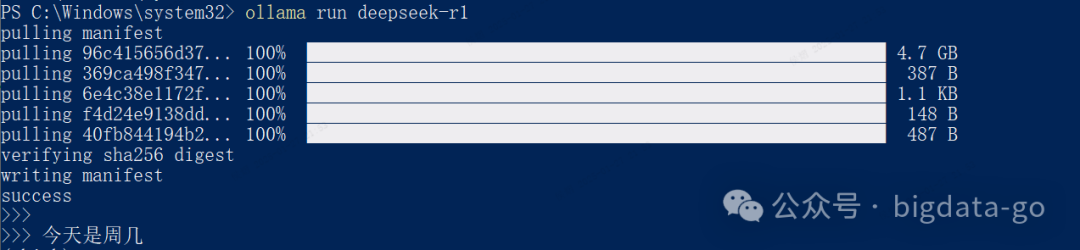
第一次运行模型,会下载到ollama环境后并运行,运行后可直接进行对话,如“今天是周几”。如果在下载过程需要其他库,直接命令下载即可(这里还要下载,如nomic-embed-text)。

Rag系统代码实现
这里使用的Langchain开发框架,向量数据库使用的Chroma、大模型用的是DeekSeek-R1(推理更优),做出一个简单代码实现。
整体代码说明:把网页上
https://lilianweng.github.io/posts/2023-06-23-agent/
使用切词模型加载到向量数据库chroma内,提交给向量数据库进行相似度匹配,一般使用欧氏距离(或相似性余弦、或皮尔森相关系数),对搜索出的多条相似内容,按照相似度进行排名,再封装进prompt给大模型,LLM再对以上多条内容归纳总结生成出回答。
import os``os.environ['USER_AGENT'] = \` `'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'``import chromadb from langchain_ollama` `import OllamaLLMimport bs4``from langchain_community.document_loaders import WebBaseLoaderfrom` `langchain_text_splitters import RecursiveCharacterTextSplitter #文本分割``from langchain_ollama import OllamaEmbeddings``from langchain_core.prompts import PromptTemplate``from langchain.chains import RetrievalQA``from langchain_chroma import Chroma # 这里需要导入包 pip install langchain_chroma`
`def lang_rag():` `# 1. 初始化llm, 让其流式输出` `llm = OllamaLLM(model="deepseek-r1",` `temperature=0.1,` `top_p=0.4,` `# callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]) )` `loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),` `bs_kwargs=dict(` `parse_only=bs4.SoupStrainer(` `class_=("post-content", "post-title", "post-header")` `)` `),` `)` `docs = loader.load() #上述文档加载,` `text_splitter= RecursiveCharacterTextSplitter(` `chunk_size=1000, chunk_overlap=200) #配置切词参数` `splits = text_splitter.split_documents(docs) #进行切词` `vectorstore = Chroma.from_documents(#加载到向量数据库chroma内` `documents=splits,` `embedding=OllamaEmbeddings(` `model="nomic-embed-text"),` `collection_name='ddd')` `# 提示词模板` `prompt = PromptTemplate(` `input_variables=['context', 'question'],` `template=` `"""You are an assistant for question-answering tasks.` `Use the following pieces of retrieved context to answer the question.` `you don't know the answer, just say you don't know without any explanation` `Question: {question} Context: {context} Answer:""",` `)` `print('提示词模板创建')` `# 向量数据库检索器` `retriever = vectorstore.as_retriever()` `print('向量数据库检索器')` `qa_chain = RetrievalQA.from_chain_type(` `llm,` `retriever=retriever,` `chain_type_kwargs={"prompt": prompt}` `)` `# what is Composition API?` `question = "what is Ai agent?"` `result = qa_chain.invoke({"query": question})` `print("question1:")` `print(result)` `question2 = "what is react?"` `result = qa_chain.invoke({"query": question2})` `print("question2:")` `print(result)`
`question3 = "什么智能体?,用中文回答"` `result = qa_chain.invoke({"query": question3})` `print("question3:")` `print(result)`
`if __name__ == '__main__':` `lang_rag()
上述代码粘贴可运行,前提是前面的环境搭建好,包安装好。
总结
**纵观历史,每个伟大时代产生以新技术新工具出现和使用而应运而生,如三次工业革命重塑了人类文明进程。第一次工业革命以蒸汽机为标志,**加速了城市化与世界市场形成深刻改变了社会结构,推动机器生产取代手工劳动,同时也创造机器生产和使用新的工作岗位。第二次工业革命以电力和内燃机为核心,人类进入“电气时代”,在取代马车交通工具等也产生汽车、火车和飞机新的交通工具等,同时也创造新工作岗位。第三次工业革命以电子计算机、原子能等为标志,推动人类进入信息时代,使人类社会从工业社会向信息社会跃迁,生产力与生活方式发生革命性变革。亦是如此,旧事物被新事物时同样会创造新的工作岗位,需要适应新事物、接受新事物、与新事物为伍。以人工智能为标志,第四次智能时代已来,****机械任务自动化、创意工作增效,生活里服务智能化、信息茧房破壁、人机交互拟真化渗透人们工作和生活的日常。为此**人们担忧人工智能替代很多人的工作,但这是历史车轮滚滚向前无法阻挡,唯有拥抱变化,拥抱AI,以AI为伍,跟上时代步伐与其同伴前行.......**
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









